
四月初,r/ClaudeAI 社区里出现了一个帖子,标题很平静:“Something happened to Opus 4.6’s reasoning effort”。
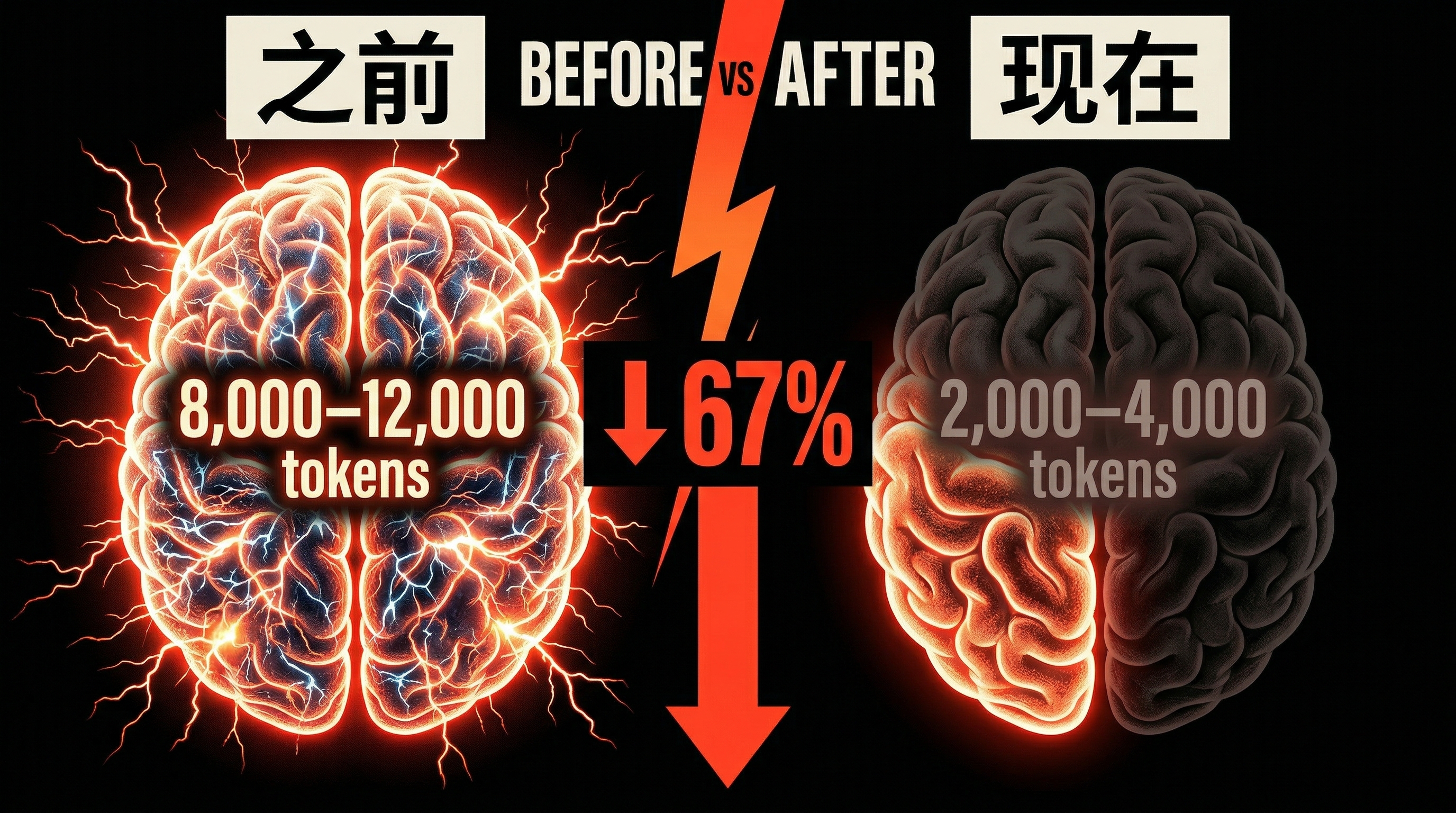
帖主没有愤怒,没有指责,只是上传了一张对比截图:同样的提示词,同样的任务,几周前的Opus 4.6会调用几千个thinking token仔细推理,而现在——它的思考几乎消失了。
这个帖子最终获得了 ⬆️2917 赞和 427 条评论。
几天后,另一个帖子出现了,措辞就没那么客气了:“Anthropic stayed quiet until someone showed Claude’s thinking depth dropped 67%”。又是 ⬆️1669 赞,242 条评论。
两帖合计超过4500赞,成为本周 r/ClaudeAI 最热话题之一。
Anthropic到底做了什么?更重要的是,它没做什么?
事件还原:用户如何发现的
要理解这件事,得先明白Claude的"扩展思考"(Extended Thinking)功能是怎么工作的。
当你使用Opus 4.6的推理模式时,模型会先用一段"内部思考"来分析问题,这段思考会消耗token——就像你在纸上打草稿,打得越多,推理越深入,答案往往越准确。
几位重度用户发现,4月初的Opus 4.6在推理任务上的thinking token数量,相比一个月前大幅减少。他们做了系统性测试:
- 用相同的数学证明题测试,thinking token从早期的约 8,000-12,000 个降到了 2,000-4,000 个
- 用同样的代码架构设计题,推理深度下降约 67%
- 最终答案质量可感知地变差,尤其是需要多步骤推理的任务
这不是玄学,是可量化的性能退化。
问题来了:Anthropic什么时候公告过这件事?
没有。
67%,意味着什么?
有人可能会问:thinking token少一点,有那么严重吗?
严重。
打个比方:你雇了一个工程师解决复杂bug,他原来会花3小时仔细分析代码路径,现在只花1小时草草看一遍就给你答案。答案可能看起来差不多,但在真正复杂的问题上,差距会暴露出来。
Claude的Extended Thinking正是为了解决这类"需要深度推理"的任务而设计的:数学证明、代码架构、法律分析、战略规划。这些场景里,thinking token的削减直接等于推理质量的削减。
更让用户不满的是:为这个功能付钱的,正是那些最需要深度推理的用户。Claude Pro订阅每月 $20,Claude Max 高达每月 $100-$200,宣传卖点之一就是Opus模型的扩展思考能力。
你买的是一辆V8发动机,发现它偷偷换成了V4,而销售手册还没更新。
Anthropic的沉默
在社区爆发之前,没有任何来自Anthropic官方的公告、changelog 或说明。
这个模式其实已经有迹可循。2024年,OpenAI被用户发现悄悄削减了GPT-4 Turbo的上下文质量,也是社区先发现,官方后跟进。当时引发了一轮关于"AI公司是否有义务通知模型变更"的大讨论,最后不了了之。
现在轮到Anthropic。
在用户数据摆出来、帖子大规模传播之后,才有Anthropic的工作人员在评论区现身回应,表示"正在调查",或者给出含糊的技术解释。
这种"等用户发现再回应"的模式,本质上是一种信息不对称的默认选项——如果没有足够多有技术能力的用户去检测、测量和发声,普通用户永远不会知道他们使用的模型被降级了。
这不是孤例:AI厂商的"静默降级"历史
AI行业有一个不成文的惯例:模型可以随时更新,不需要通知用户。
这在技术上是合理的——模型需要持续优化,版本迭代是常态。但问题在于,“优化"和"降级"之间的界限从来没有被清晰定义过,而厂商显然不会主动区分。
几个有记录的案例:
OpenAI GPT-4(2023-2024年):多位研究者发表论文,证明GPT-4在数学、代码和推理任务上的性能随时间系统性下降。OpenAI最初否认,后来承认进行了"效率优化”。
GPT-4o的视觉能力(2024年):用户发现GPT-4o在图像理解任务上的质量大幅下降,事后发现是Anthropic调整了模型的视觉权重以降低计算成本。
Claude 2 到 Claude 2.1:Anthropic在版本更新时削减了部分推理能力,这次有官方changelog,但描述极为模糊。
Opus 4.6 thinking depth(2026年):本次事件。
规律很清晰:当优化带来成本节省时,厂商倾向于悄悄执行。当用户发现时,先沉默,再给出技术性解释(“这是权衡”、“整体体验更好了”),然后继续。
为什么厂商会这样做?
理解这个问题,需要站在商业逻辑的角度。
Thinking token极其昂贵。 每一个thinking token都要消耗真实算力,在模型规模越来越大、用户量越来越多的情况下,thinking深度是最容易也最值得压缩的成本项。用户感知不明显,但财报感知非常明显。
没有法律约束。 目前没有任何规定要求AI公司在模型性能变化时通知用户。服务条款通常写明"功能可能随时变更",一句话就覆盖了所有情况。
用户验证成本高。 大多数用户没有能力系统性测试模型性能变化,即使感觉"最近Claude变笨了",也很难量化。这种模糊性保护了厂商。
竞争压力。 承认自家模型降级,相当于给竞争对手递刀子,没有厂商愿意主动做这件事。
你能做什么?
1. 建立自己的基准测试集
选取10-15个你真实工作中常用的、需要深度推理的任务,定期用同样的prompt测试当前模型。这是发现性能变化最直接的方法。
2. 关注 thinking token 数量
如果你使用Claude的Extended Thinking,可以在API层面观察每次调用的thinking token消耗。如果某段时间内这个数字系统性下降,就值得警惕。
|
|
3. 参与社区监督
r/ClaudeAI 这次的事件表明,用户集体的观察和数据整理是唯一有效的外部监督机制。当你注意到性能异常时,发帖、分享数据,比沉默更有价值。
4. 考虑保留历史基准
如果你依赖Claude完成关键业务,定期保存一批"金标准"问答对,用于纵向对比,建立自己的模型性能追踪体系。
最后说一句
Anthropic的品牌形象一直建立在"负责任的AI"上——这是他们的核心叙事,也是他们区别于OpenAI的最大卖点。
但"负责任"如果只体现在安全政策上,而不体现在对付费用户的基本透明度上,那这个品牌承诺就是残缺的。
用户有权知道,他们付钱使用的模型,昨天和今天是否还是同一个模型。
这不是过分的要求。
参考来源