
在本地 AI 排行榜上,Gemma 4 把几乎所有对手都打下去了——只有 Claude Opus 4.6 和 GPT-5.2 还站着。
2026 年 4 月 2 日,Google DeepMind 发布了 Gemma 4。
这次不是悄悄发布,而是一出手就拿出了四款模型,从手机能跑的 E2B 到服务器级别的 31B Dense,全系 Apache 2.0 开源,商用无限制。
结果在 Reddit LocalLLaMA 社区,一个帖子获得了 821 个赞:
“Gemma 4 just casually destroyed every model on our leaderboard except Opus 4.6 and GPT-5.2.”
“随手就把排行榜上的模型全干掉了”——这句话在社区里传了好几天。
发生了什么?
一、Gemma 4 到底有多强
先看数字。
| Benchmark | Gemma 4 31B | Gemma 4 26B MoE | Gemma 4 E4B | Gemma 3 27B(上代) |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 67.6% |
| AIME 2026(数学竞赛) | 89.2% | 88.3% | 42.5% | 20.8% |
| GPQA Diamond(博士级科学) | 84.3% | 82.3% | 58.6% | 42.4% |
| Codeforces ELO(编程竞赛) | 2150 | 1718 | 940 | 110 |
几个对比让这个数据更有感觉:
- 上代 Gemma 3 27B 的 AIME 分数是 20.8%,这代 31B 是 89.2%。同量级参数,数学能力直接翻了 4 倍多。
- Codeforces ELO 2150 意味着什么?人类竞赛程序员里,这个分数大约对应前 0.3%。
- 在全球开源模型排行榜(Arena AI)上,31B 版本排名第 3,26B MoE 版本排名第 6。
和 Qwen 3.5 比:Gemma 4 31B 在 MMLU Pro 上(85.2% vs ~82%)略有优势,但两者都处于同一档位——这是真正的顶级开源模型之争,不再是"比闭源差一截的替代品"。
二、26B 跑起来只用 4B 的算力——这是怎么回事
这是 Gemma 4 最有意思的地方,也是为什么叫"怪物"。
Gemma 4 26B 的全称是 Gemma 4 26B A4B——A4B 代表 “Active 4B”,意思是推理时只激活 3.8B 参数,但整体参数量是 26B。
这用的是 MoE(Mixture of Experts,混合专家)架构:
模型内部有很多"专家网络",每次推理时,一个路由机制决定激活哪些专家来处理当前的 token。大多数参数大部分时间都是闲置的。
实际效果:26B MoE 的推理速度和 4B 模型相当,但性能接近 26B 模型。
换个说法:你用 4B 模型的算力和速度,跑出了 26B 的效果。
| 对比维度 | 26B MoE (A4B) | 标准 26B Dense |
|---|---|---|
| 总参数量 | 26B | 26B |
| 推理激活参数 | 3.8B | 26B |
| 推理速度 | ≈ 4B 模型 | 慢 6-7 倍 |
| 性能 | 接近 26B Dense | 26B Dense |
| VRAM 占用 | 更低 | 更高 |
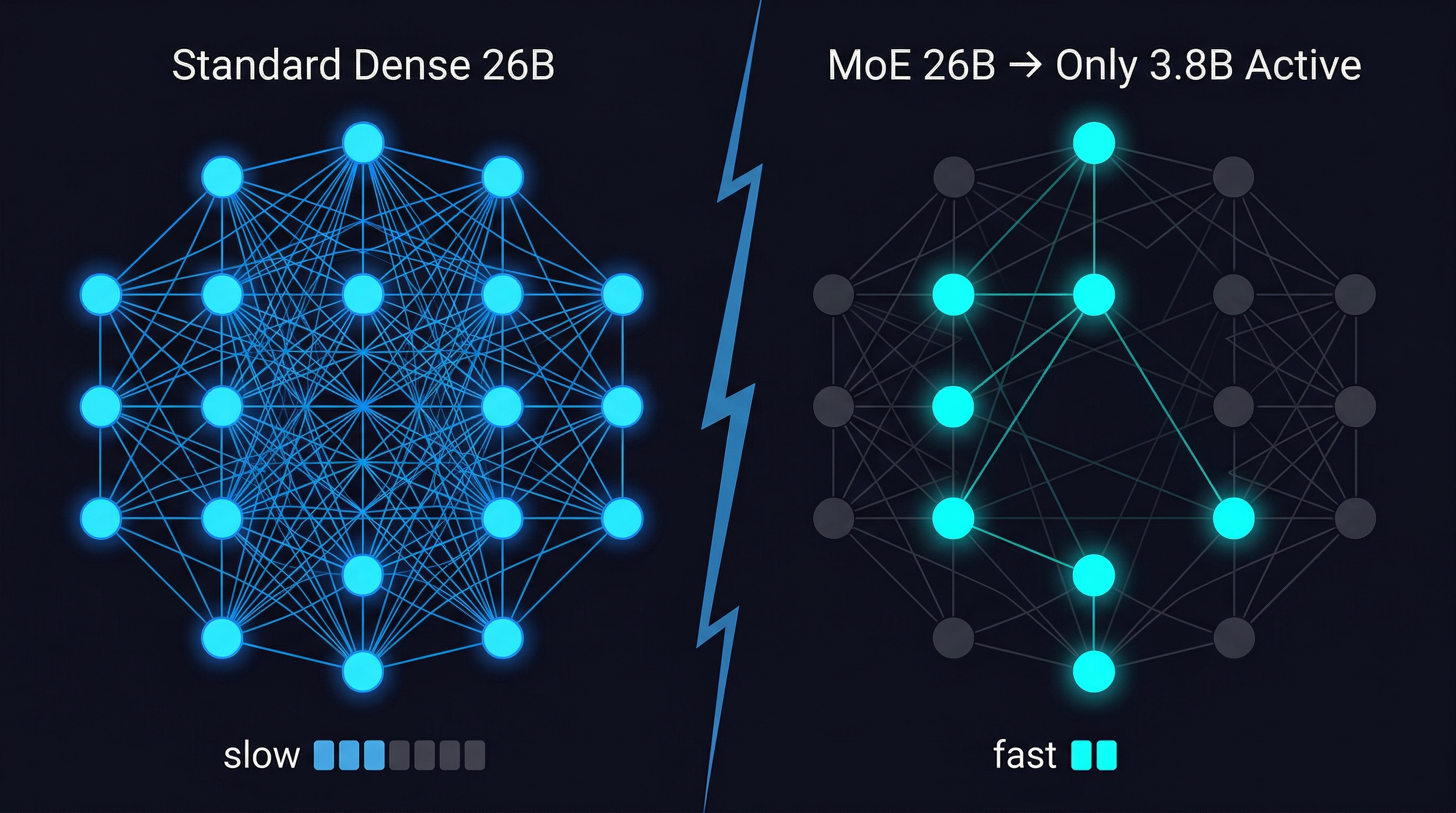
这也解释了为什么 26B MoE 在排行榜上是第 6,而不是像直觉预期的那样输给 31B Dense 很多——它在效率上弥补了一部分性能差距。
三、Per-Layer Embeddings:小模型变强的真正秘密
MoE 解释了 26B 的效率问题,但 Gemma 4 的 E2B 和 E4B 这两个小模型也明显强过上代,靠的是另一个技术:Per-Layer Embeddings(PLE,逐层嵌入)。
理解这个之前,先理解传统方法的问题。
传统 Transformer 的做法:每个 token 进入模型时,做一次 embedding 查找,得到一个向量,然后这个向量流过所有的层,逐层累积上下文信息。问题是:这个初始向量需要"预装"所有层可能用到的信息——负担很重,而且很多信息在特定层其实用不上。
PLE 的做法:加一个额外的嵌入表,为每个 token 在每一层单独提供一个小向量(256 维,而不是主嵌入的 1536 维)。这些向量存在闪存里,推理开始时一次性加载。
效果是什么?
token “cat” 在第 2 层的含义可以是"我是一个名词",在第 18 层的含义可以是"我是一种小动物"。
每一层都能接收"当前这个 token 现在对我意味着什么"的专属信号,而不是只靠第一层的静态向量撑到最后。
这让小模型能更充分地利用有限参数——不是堆参数,而是让每个参数都更精准地工作。
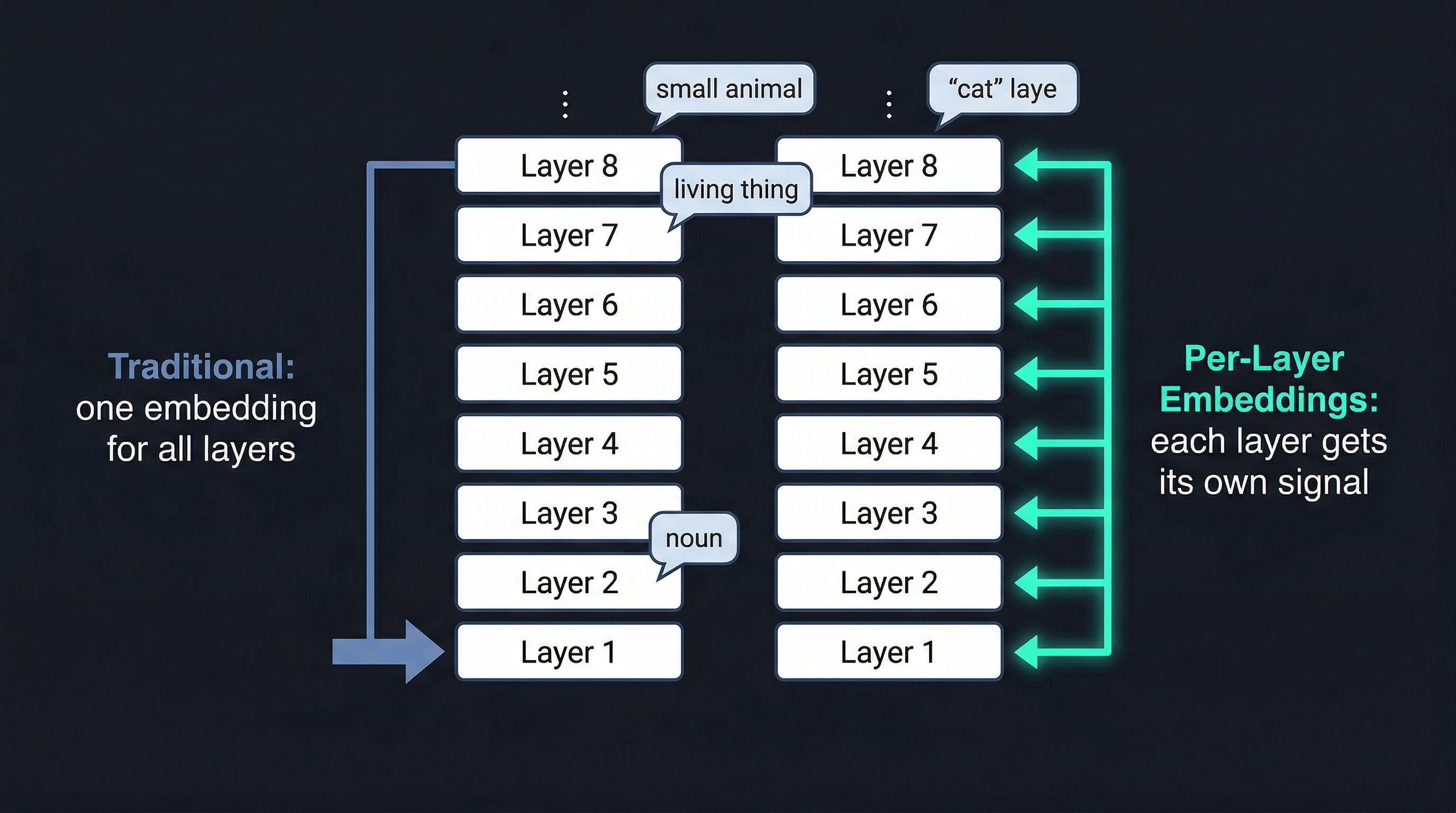
这也是为什么 E4B(4B 参数)在 AIME 2026 上能拿到 42.5%,而上代 27B(参数量是它的 7 倍)只有 20.8%。
四、Gemma 4 的四个版本:该选哪个
| 版本 | 实际参数 | 主要特性 | 最低硬件 | 推荐硬件 |
|---|---|---|---|---|
| E2B | ~2B 激活 | 手机/嵌入式,支持视频+音频 | 4GB RAM | 手机/树莓派 |
| E4B | ~4B 激活 | 轻量多模态 Agent,支持音频 | 8GB RAM | M 系列 MacBook |
| 26B MoE (A4B) | 3.8B 激活 | 最佳性价比,速度≈4B | 16GB VRAM | RTX 4090 / 4080 |
| 31B Dense | 31B | 最高性能,适合微调 | 24GB VRAM | H100 / A100 |
大多数开发者的选择:
- 笔记本 / M 系列 Mac → E4B:够用,速度快,支持多模态
- 有 16-24GB VRAM 的台式机 → 26B MoE:性能最强,速度还快
- 需要微调的研究场景 → 31B Dense
五、本地跑起来:三分钟上手
方式一:Ollama(推荐)
|
|
Ollama 自动处理量化和下载,运行后本地起 OpenAI 兼容 API,可以直接接 Cursor、Open-WebUI、任何支持 OpenAI 格式的工具。
方式二:llama.cpp(更高性能)
|
|
Q4_K_M 是 4bit 量化版本,26B MoE 在 Q4 下约需 10-12GB VRAM,一块 RTX 4080 可以流畅运行。
方式三:LM Studio(图形界面)
打开 LM Studio,搜索 gemma-4,点击下载。模型加载后自动提供本地 API 服务。适合不想碰命令行的用户。
六、和其他模型对比:该用 Gemma 4 替代什么
坦诚说明差距:
| 维度 | Gemma 4 26B(本地) | Claude Sonnet 4.6(云端) |
|---|---|---|
| 代码生成(复杂项目) | ★★★★☆ | ★★★★★ |
| 数学推理 | ★★★★★ | ★★★★★ |
| 指令遵循 | ★★★★☆ | ★★★★★ |
| 长上下文 | 256K ✅ | 200K ✅ |
| 多模态(图片/视频) | ✅ 原生支持 | ✅ |
| 数据隐私 | ✅ 完全本地 | ❌ 上传云端 |
| 延迟 | 无网络延迟 | 取决于网络 |
| 成本 | 电费(趋近于零) | 按 token 计费 |
真正适合替代 Claude/GPT 的场景:
- 本地代码审查:速度快、不上传代码、够用
- 数学和逻辑推理:Gemma 4 的强项,接近顶级闭源模型
- 多模态本地应用:截图分析、文档理解,数据不出本机
- 高吞吐批量处理:不需要实时响应的任务,本地成本为零
仍然建议用 Claude 的场景:
- 复杂多步骤工程任务(Claude Code 的 Agent 能力目前仍领先)
- 需要工具调用和实时信息的场景
- 写作质量要求很高的内容创作
这件事的意义
Gemma 4 之所以在社区里引发轰动,不只是因为它跑分高。
更重要的信号是:开源模型与顶级闭源模型之间的差距,正在以比预期快得多的速度收窄。
半年前,本地模型还处于"能用但将就"的阶段。现在,Gemma 4 31B 在数学竞赛题上的成绩(AIME 89.2%)已经超过了绝大多数闭源商业模型的公开数据。
这条线在继续移动。
对开发者的实际意义:
- 本地 AI 工作流正在变得可行——不只是代码补全,而是真正的任务自动化
- 数据隐私敏感场景(医疗、法律、企业内部数据)有了更可信赖的本地选项
- 运行成本正在接近于零——对高吞吐场景来说,这是量变引发质变
Gemma 4 只是一个节点。它证明了 Google 在开源模型上认真了——Apache 2.0 授权、商用无限制,这是一个明确的市场信号。
快速上手清单
- 确认显卡 VRAM:16GB 以上跑 26B MoE,8GB 以上跑 E4B
- 安装 Ollama:
ollama run gemma4:4b先试跑 - 或下载 LM Studio,搜索 gemma-4,一键启动
- 把 Open-WebUI 的模型切换到本地 Gemma 4
- 测试你最常用的代码/推理任务,感受实际效果
参考资料
- Gemma 4: Byte for byte, the most capable open models - Google Blog
- Welcome Gemma 4: Frontier multimodal intelligence on device - HuggingFace
- A Visual Guide to Gemma 4 - Maarten Grootendorst
- Gemma 4 Developer Guide: Benchmarks & Local Deployment - Lushbinary
- Google Gemma 4 Deep Dive: Architecture, MoE & Benchmarks - Qubrid AI
- Reddit: Gemma 4 just casually destroyed every model on our leaderboard - r/LocalLLaMA
- Reddit: Per-Layer Embeddings - A simple explanation - r/LocalLLaMA
- Reddit: Gemma 4 26b is the perfect all around local model - r/LocalLLaMA