本地 AI 的 2026 抉择:2万块的显卡到底值不值?
一个真实的选择题:朋友问我该不该花2万块买 RTX 4090 跑本地 AI,还是继续用 Claude API。我帮他算了笔账。
前言
这个问题在 2026 年初的 Reddit LocalLLaMA 社区异常火爆。随着开源模型(如 Llama 3、Qwen 2.5)的能力突飞猛进,越来越多的人开始纠结:是投资本地硬件,还是继续依赖云端 API?
这不是一个简单的"买vs不买"问题,而是一道需要精确计算的投资决策题。本文将帮你算明白这笔账。
一、经济账:3年总成本对比
本地方案:一次性投入 + 持续电费
硬件成本(2026年中国市场):
- RTX 4090(24GB):约 20,000 元
- 配套升级(电源、主板、机箱等):约 5,000 元
- 初始投入总计:25,000 元
电费成本:
- RTX 4090 满载功耗:450W
- 假设每天使用 4 小时,每月 120 小时
- 月耗电:450W × 120h = 54 kWh
- 民用电费约 0.6 元/kWh
- 月电费:32.4 元
- 3年电费:1,166 元
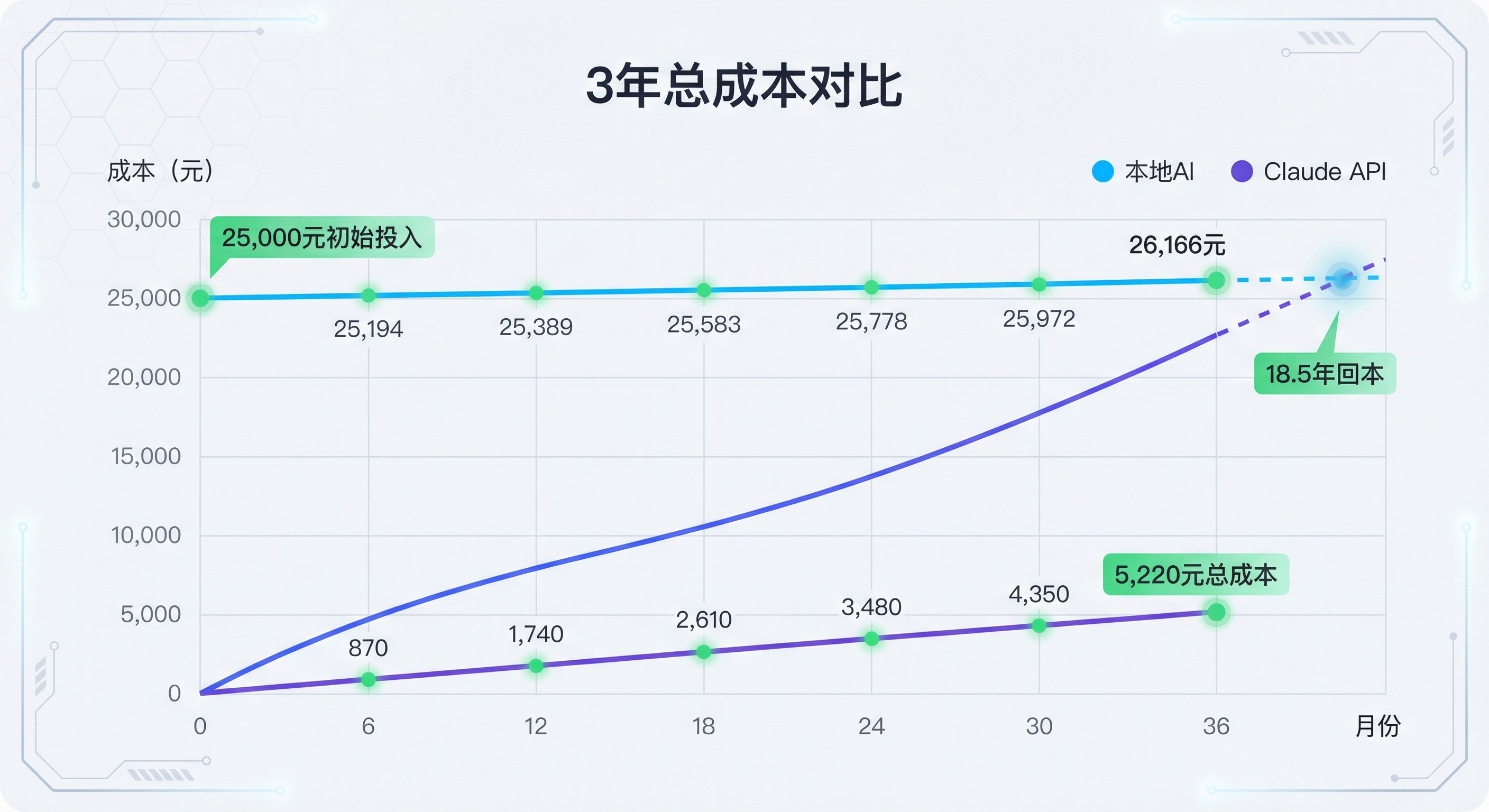
3年总成本 = 25,000 + 1,166 = 26,166 元
云端方案:按需付费
Claude Sonnet 4.5 API 定价(2026年):
- Input:$3/百万 tokens
- Output:$15/百万 tokens
使用场景估算: 假设中度使用:
- 每天对话 50 轮,每轮平均:
- Input:2,000 tokens
- Output:500 tokens
- 日消耗:Input 10万 tokens + Output 2.5万 tokens
月度成本计算:
- Input:10万 × 30天 = 300万 tokens = 3M tokens
- 成本:3M × $3/MTok = $9/月
- Output:2.5万 × 30天 = 75万 tokens = 0.75M tokens
- 成本:0.75M × $15/MTok = $11.25/月
- 月度总成本:$20.25 ≈ 145 元
3年总成本 = 145 × 36 = 5,220 元
盈亏平衡点计算
公式:
|
|
结论:中度使用场景下,需要 18.5 年才能回本。
但如果我们提高使用频率:
高频使用场景(每天 200 轮对话):
- 月度 API 成本:145 × 4 = 580 元
- 盈亏平衡点:25,000 / (580 - 32.4) ≈ 45 个月 ≈ 3.8 年
这个时间长度就比较合理了。
成本计算器(你可以代入自己的数据)
|
|
二、性能账:能力维度对比
单纯看经济账是不够的,还需要考虑实际能力差异。
本地模型的优势
| 维度 | 表现 |
|---|---|
| 隐私安全 | ✅ 数据不出本地,敏感信息完全可控 |
| 延迟 | ✅ 无网络延迟,实时响应 |
| 使用限制 | ✅ 无请求频率限制,无内容审核 |
| 离线可用 | ✅ 无需网络,随时可用 |
| 可定制性 | ✅ 可以微调(Fine-tune)自己的模型 |
本地模型的劣势
| 维度 | 表现 |
|---|---|
| 推理能力 | ❌ Llama 3 70B 在复杂推理、代码生成上仍落后 Claude Sonnet 4.5 |
| 上下文窗口 | ❌ 多数本地模型 32K-128K,Claude 达 200K |
| 多模态能力 | ❌ 本地视觉模型能力有限,Claude 原生支持 |
| 稳定性 | ❌ 需自己维护硬件和环境,系统崩溃需自己处理 |
| 更新速度 | ❌ 需手动下载新模型,Claude 自动更新 |
实际使用场景对比
代码生成任务:
- Claude Sonnet 4.5:准确率 ~85%,一次性生成可用代码
- Llama 3 70B:准确率 ~65%,需要多次迭代
长文本分析(10万字):
- Claude:原生支持 200K 上下文,一次分析完成
- 本地模型:需要分段处理,增加复杂度
图像理解:
- Claude:原生支持,可读图、分析图表
- 本地:需额外部署视觉模型,性能较差
三、决策树:你应该选哪个?
根据使用频率、任务类型和预算,我用决策树帮你定位:
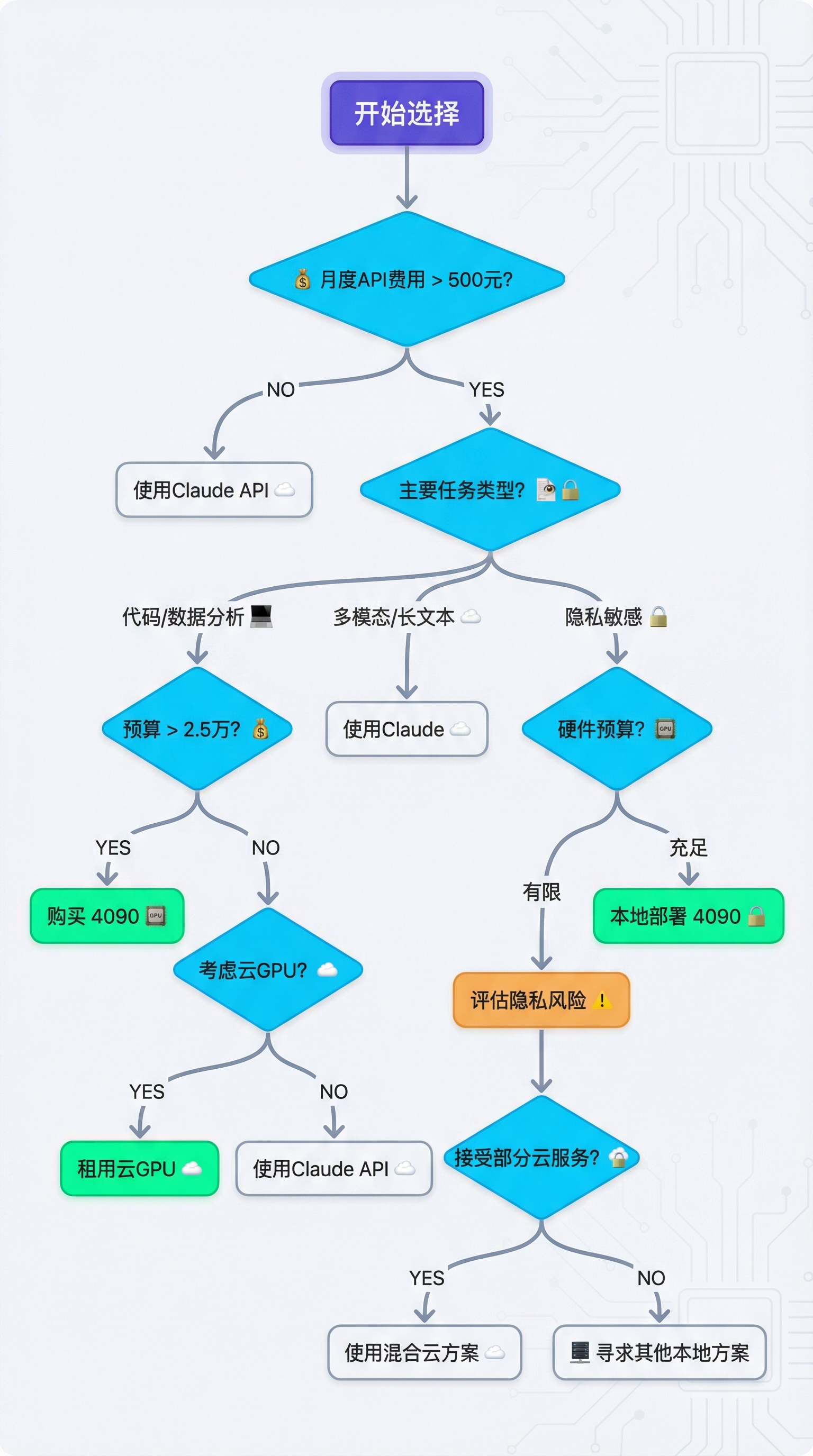
场景化建议
✅ 应该买 4090 的情况:
- 高频重度用户:每月 API 费用超过 500 元(约每天 200+ 轮对话)
- 代码为主:主要做代码生成、调试、数据分析
- 隐私敏感:处理敏感数据,不能上传云端
- 学习研究:需要频繁实验不同模型和参数
- 离线需求:经常在无网络环境工作
❌ 不应该买 4090 的情况:
- 轻度用户:每月 API 费用低于 100 元
- 多模态需求:频繁使用图像、视频分析
- 长文本处理:经常处理超过 10 万字的文档
- 不想折腾:不想维护硬件和软件环境
- 预算紧张:2.5 万对你来说是一笔大钱
⚠️ 可以考虑的情况:
- 中度用户(月 API 费 200-400 元)
- 对隐私有需求但不强制
- 有学习意愿,愿意折腾
四、混合方案:最优解是什么?
经过分析,我发现纯本地或纯云端都不是最优解。
推荐的混合方案
分层使用策略:
| 任务类型 | 使用方案 | 理由 |
|---|---|---|
| 日常对话、问答 | Claude API | 成本低,质量高 |
| 代码生成、调试 | 本地模型 | 高频使用,隐私保护 |
| 图像理解 | Claude API | 本地模型能力不足 |
| 长文本分析 | Claude API | 上下文窗口优势 |
| 敏感数据处理 | 本地模型 | 隐私保护 |
硬件配置建议:
- 不一定要上 RTX 4090
- RTX 4070 Ti Super(16GB):约 8,000 元,可运行 13B-30B 模型
- RTX 4080 Super(16GB):约 1.2 万元,性价比更高
- 云 GPU + 本地推理:按需租用,灵活性高
实施路线图
阶段一:纯云端试用(1-2个月)
- 使用 Claude API,统计实际使用量和费用
- 记录哪些任务高频使用
- 评估对隐私、延迟的敏感度
阶段二:轻量本地部署(3-6个月)
- 如果月费用 > 200 元,考虑入手 4070 Ti Super
- 部署本地模型处理高频任务
- 复杂任务仍使用 Claude
阶段三:深度优化(6个月后)
- 如果本地使用频率很高,升级到 4090
- 建立完善的本地-云端切换机制
- 微调专属模型
五、我的最终建议
不要盲目追求"全本地"或"全云端"。
2026 年的 AI 使用应该是智能分流的:
- 简单任务 → 本地小模型(快速、便宜)
- 复杂任务 → Claude Sonnet 4.5(高质量、可靠)
- 敏感任务 → 本地大模型(隐私保护)
给朋友的最终建议:
- 先用 Claude API 2 个月,统计实际费用
- 如果月费用 < 200 元,继续用云端
- 如果月费用 > 400 元,入手 RTX 4070 Ti Super 试水
- 如果本地体验良好,再考虑升级到 4090
记住:技术是工具,不是目的。适合自己的,才是最好的。
参考数据与来源
- Claude API 官方定价
- Claude API 价格计算器
- Local AI 真实成本效益分析
- 本地 AI 硬件成本上升分析
- Should I invest in a beefy machine for local AI
更新日期:2026-02-04 下次回顾:2026-06-01(模型能力可能有大变化)