“我放弃了ChatGPT,把所有AI工作都迁移到本地LLM——这是2026年最正确的决定。”
这是Reddit r/AI_Agents版块一个引爆讨论的热帖标题。发帖人称,2026年将是"本地AI之年",并详细列出了他转向本地AI的三大理由:零延迟、真正隐私、长期成本更低。
但事实真的这么简单吗?
作为一个已经在AI领域深耕两年的开发者,我在这场"本地 vs 云端"的争论中看到了太多非此即彼的极端观点。今天,我想从实际使用体验出发,帮你做出真正适合自己的选择。
引言:为什么"本地AI之年"引发热议
首先,我们得承认这个Reddit热帖戳中了很多开发者的痛点。
为什么"本地AI之年"这个说法会引发如此强烈的共鸣?
- 云端API涨价成常态:OpenAI、Anthropic在2025年多次调整价格,虽然单位成本下降,但高频用户的总支出仍在增长
- 隐私焦虑从未消失:把代码、文档、商业数据上传到云端,始终是企业用户的心病
- 延迟问题无法忽视:再快的API也抵不过本地推理的即时响应
但热帖只说了一半真相。
同样的Reddit社区,也有人晒出账单:为了跑7B模型,花了2万块升级电脑,电费每月多出300块,最后发现性能还不如GPT-4。
所以问题不是"哪个更好",而是**“哪个更适合你”**。

本地AI的三大优势
1. 零延迟的爽快体验
这是最直观的感受。用云端API,你发送请求 → 等待网络往返 → 接收流式响应,整个过程至少1-2秒。
本地AI?按下回车的瞬间,文字就开始涌现。
对于以下场景,这种体验差异是巨大的:
| 场景 | 云端API | 本地AI |
|---|---|---|
| 代码补全 | 有明显等待 | 几乎即时 |
| 长文档总结 | 等待5-10秒 | 2-3秒开始输出 |
| 实时对话 | 网络波动影响体验 | 稳定流畅 |
2. 真正的隐私保护
把敏感数据上传到云端,本质上是把控制权交给了第三方。
本地AI的隐私优势体现在:
- 数据不出设备:你的代码、财务数据、客户信息永远在本地
- 无监控风险:不用担心模型提供商使用你的数据进行训练
- 合规友好:对于医疗、金融等受监管行业,本地部署更容易满足合规要求
但要注意:本地部署≠绝对安全,你仍然需要做好设备安全、访问控制等工作。
3. 长期成本更低
这是争议最大的点。让我们算一笔账:
云端API成本(以GPT-4级别模型为例):
- 每天1000次API调用
- 平均每次0.01美元
- 月成本:300美元 ≈ 2100元人民币
- 年成本:约25,000元
本地AI成本:
- 硬件投入:RTX 4090(15,000元)或 Mac Studio(20,000元)
- 电费增加:约200元/月 × 12 = 2,400元/年
- 软件成本:0元(开源模型)
- 第一年总成本:约17,000-22,000元
结论:如果你的API调用量够大(每天超过500次),第二年之后,本地AI就能回本并开始省钱。

本地AI的现实挑战
1. 硬件门槛不低
想跑得动7B模型,你至少需要:
- 显存:16GB起步(推荐24GB)
- 内存:32GB以上
- 存储:至少100GB SSD空间
这意味着一张RTX 4090(约15,000元)几乎是刚需。如果你想跑13B或更大模型,硬件成本会翻倍。
Mac用户相对幸运:M2/M3 Max的统一内存架构让本地AI变得更划算,但Mac Studio的价格依然不菲(2万起步)。
2. 性能差距客观存在
这是很多人回避但必须面对的事实:
- 推理能力:本地7B模型 ≈ GPT-3.5水平,远逊于GPT-4/Claude Opus
- 代码能力:本地模型在复杂任务、多文件推理上明显吃力
- 上下文窗口:本地模型通常支持8K-32K,而云端已支持128K+
如果你需要的是最强推理能力,本地AI目前还无法替代云端API。
3. 维护成本被低估
跑本地AI不是"装完就完事":
- 模型更新:新模型发布,你得重新下载、部署
- 依赖管理:Python环境、CUDA版本都可能出问题
- 性能调优:量化、蒸馏、提示词优化都需要时间学习
对于非技术背景的用户,这些都不是小事。
云端AI的不可替代性
说了这么多本地AI的好话,我们必须承认:云端API在相当长一段时间内,仍是大多数人的最优选择。
云端不可替代的四大场景
- 复杂推理任务:GPT-4、Claude Opus在复杂问题上的能力,本地模型暂时无法匹敌
- 多模态能力:图像理解、语音交互,云端模型的成熟度远超本地
- 弹性需求:项目初期需求不确定,按量付费的云端更灵活
- 团队协作:多人共享、权限管理、使用统计,云端产品有完整的SaaS功能
云端体验的持续优化
2025-2026年,云端AI也在进化:
- 边缘节点部署:OpenAI、Anthropic在全球部署更多节点,延迟已降至200ms以内
- 流式响应优化:首字生成时间(TTFT)大幅缩短
- 价格持续下降:GPT-4o-mini等轻量模型让单次调用成本降至0.0001美元级别
2026年推荐方案:混合部署
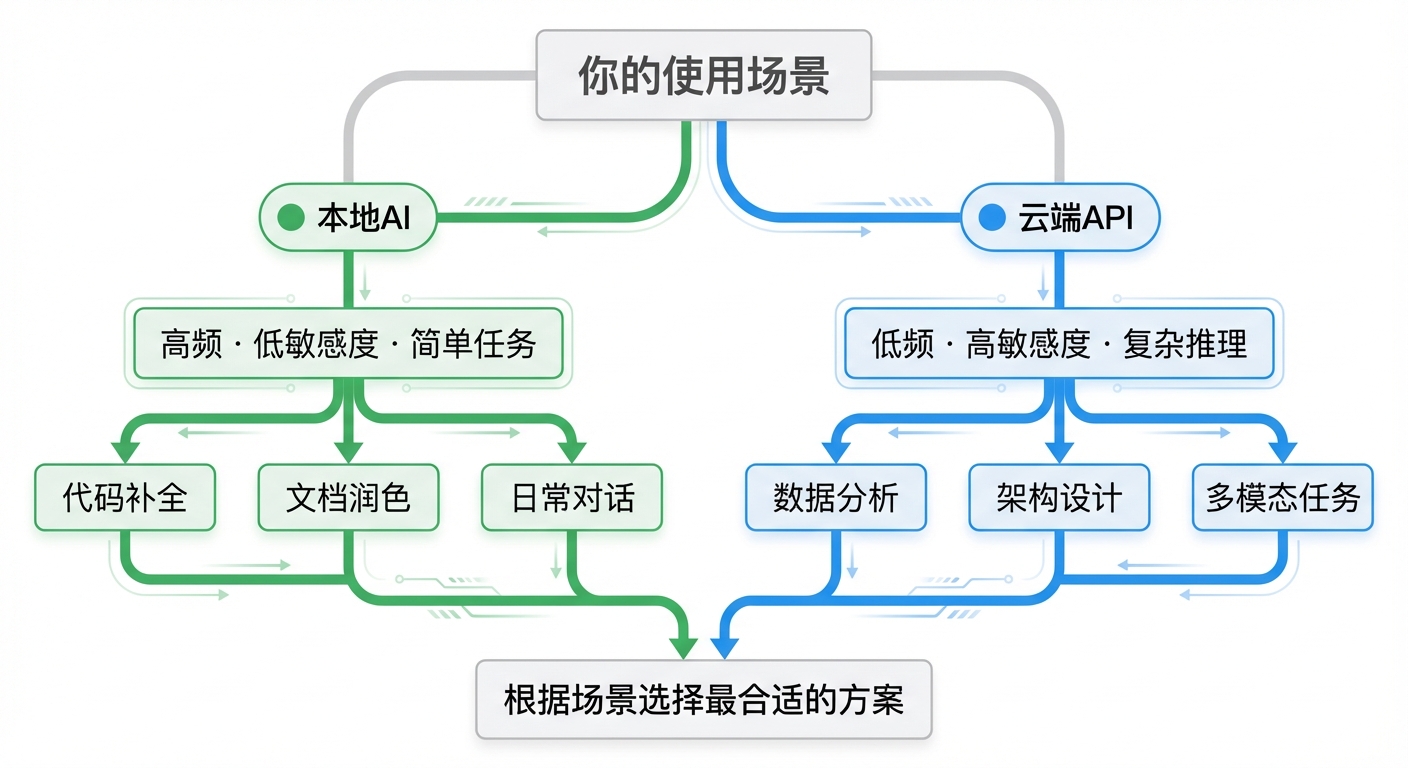
经过以上分析,我的建议是:不要二选一,而是混合部署。
决策框架
根据使用场景,选择对应的方案:
- 高频 · 低敏感度 · 简单任务 → 本地AI(代码补全、文档润色、日常对话)
- 低频 · 高敏感度 · 复杂推理 → 云端API(数据分析、架构设计、多模态任务)

具体推荐方案
方案A:个人开发者(轻度使用)
- 推荐:100% 云端API
- 理由:硬件投入不划算,维护成本高
- 工具:Claude Code、Cursor、ChatGPT
方案B:个人开发者(重度使用)
- 推荐:本地AI为主 + 云端为辅
- 配置:RTX 4090 / Mac Studio + Claude API备用
- 分工:日常任务用本地,复杂任务用Claude Opus
方案C:小团队(3-5人)
- 推荐:混合部署
- 配置:1台本地服务器(团队共享) + 云端API配额
- 分工:代码生成、文档处理用本地,核心业务逻辑用云端
方案D:企业用户
- 推荐:私有化部署 + 云端兜底
- 配置:自建GPU服务器 / 使用阿里云、AWS的GPU实例
- 合规:敏感数据本地处理,非敏感任务云端处理
本地AI快速上手
如果你决定尝试本地AI,这里是2026年1月的推荐工具:
| 工具 | 特点 | 适用人群 |
|---|---|---|
| Ollama | 命令行工具,一键部署 | 开发者 |
| LM Studio | 图形界面,易于使用 | 非技术用户 |
| Text-Generation-WebUI | 功能最强大,可定制性强 | 高级用户 |
| Jan | 跨平台,支持多模型 | Mac/Windows用户 |
推荐入门模型(2026年1月):
- Qwen 2.5 7B:中文能力最强,综合性能好
- Llama 3.1 8B:英文任务首选,社区支持广
- DeepSeek Coder 7B:代码任务专用,表现优异
- GLM 4 9B:智谱AI开源,中英双语平衡
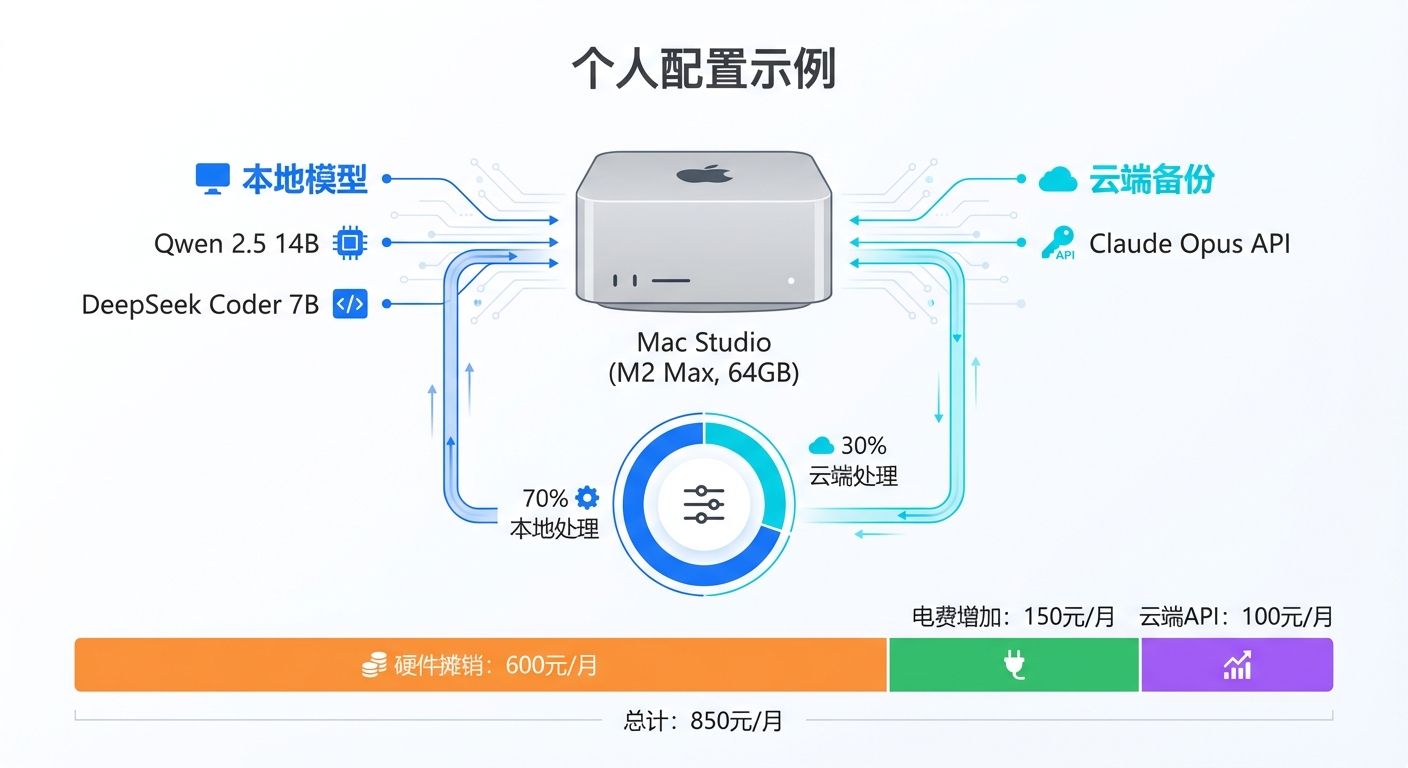
我的个人选择
作为一个AI领域的实践者,我的配置是:
- 主力设备:Mac Studio (M2 Max, 64GB统一内存)
- 本地模型:Qwen 2.5 14B + DeepSeek Coder 7B
- 云端备份:Claude Opus API(每月约100元)
- 使用分配:
- 70%的任务:本地AI处理(代码生成、文档总结、日常对话)
- 30%的任务:云端处理(复杂推理、多模态任务、紧急需求)
这套配置的月均成本:
- 硬件摊销(按3年计算):约600元
- 电费增加:约150元
- 云端API:约100元
- 总计:850元/月
如果全部使用云端API,按我的使用量,月成本至少要1500元。
所以我每年省下约7800元,硬件投入在2年内回本。
2026年的趋势预测
最后,让我对2026年做几个预测:
- 硬件门槛会降低:NPU、推理专用芯片会普及,千元级设备也能跑7B模型
- 模型差距会缩小:开源模型的推理能力将持续追赶,GPT-4级别的能力可能在2026年底开源实现
- 混合方案成主流:90%的重度用户会采用"本地+云端"的混合方案
- 工具体验会提升:Ollama、LM Studio等工具会变得更傻瓜化,非技术用户也能轻松上手
结语
“本地AI之年"这个说法,既不完全正确,也不完全错误。
真相是:2026年不会是本地AI取代云端AI的一年,而是混合部署成为主流共识的一年。
你不需要在"本地"和"云端"之间做出非此即彼的选择。真正聪明的做法是:了解自己的需求,计算自己的成本,选择最适合自己的方案。
希望这篇文章能帮你做出明智的决定。
参考资料:
- Reddit - Why I finally ditched the Cloud and moved to Local LLMs in 2026
- Reddit - Top open LLM for consumers, start of 2026
作者声明:本文基于作者个人使用经验,不同场景下结论可能不同。建议读者根据自己的实际需求做出选择。