
如果你最近一直在用 Claude Code、Cursor 或各种 Agent(智能体)工具,大概率会有一个熟悉的感觉:Agent 已经不再只是“回答问题”的聊天机器人,它开始真正介入工作了。
它会读代码、写评审意见、整理工单、草拟合同、修改文档、跑脚本,有时候还会把结果交给你确认。你点了同意,或者改了几句,任务就算继续往前走。
但这里有个很实际的问题:两个月后,如果有人问“当时 Agent 到底写了什么?你为什么改?谁批准的?依据是什么?”你还能讲清楚吗?
很多团队现在讲不清楚。
因为这些信息通常散落在聊天记录、应用日志、工单评论、代码提交、Slack 线程和某个人的脑子里。出了问题再回头查,往往不是审计,而是考古。
CHAP(Collaborative Human-Agent Protocol,协作式人类与智能体协议)想解决的就是这个问题。它不是一个让模型更聪明的提示词框架,也不是另一个 Agent 编排工具。它更像是在问:如果人类和 Agent 真的要长期一起做事,我们是不是需要一套协作协议?

为什么只靠 Prompt 不够了
过去两年,很多关于 Agent 的讨论都卡在三个关键词上:模型、工具调用、工作流。
模型要更强,工具要更多,工作流要能跑更久。这个方向当然没错,但它默认了一个前提:只要 Agent 能把事情做完,系统就算成功。
真实工作不是这样。
真实工作里,Agent 给出的结果很少会被人原封不动接受。更常见的是:它写了一个初稿,人类改掉其中一段;它标记了一个风险,人类认为是误报;它建议批准一个流程,人类要求补充依据;它完成了一个任务,但下一位同事要接着处理。
这些“人类介入”的瞬间,恰恰是协作中最有价值的信息。
问题是,今天大多数 Agent 应用并不会认真保存这些信息。它们可能保存最终答案,却不保存人类为什么覆盖了 Agent 的判断;可能保存聊天历史,却不把修改、理由、权限和任务状态做成可查询的数据;可能有日志,但日志是给工程师排错看的,不是给团队复盘协作看的。
所以,Prompt(提示词)解决的是“怎么让 Agent 这一次表现好一点”。CHAP 关心的是另一个层面:当 Agent 在组织里反复参与工作,协作过程本身如何留下结构化痕迹。
这就是它和普通提示词技巧的分水岭。
CHAP 到底想记录什么
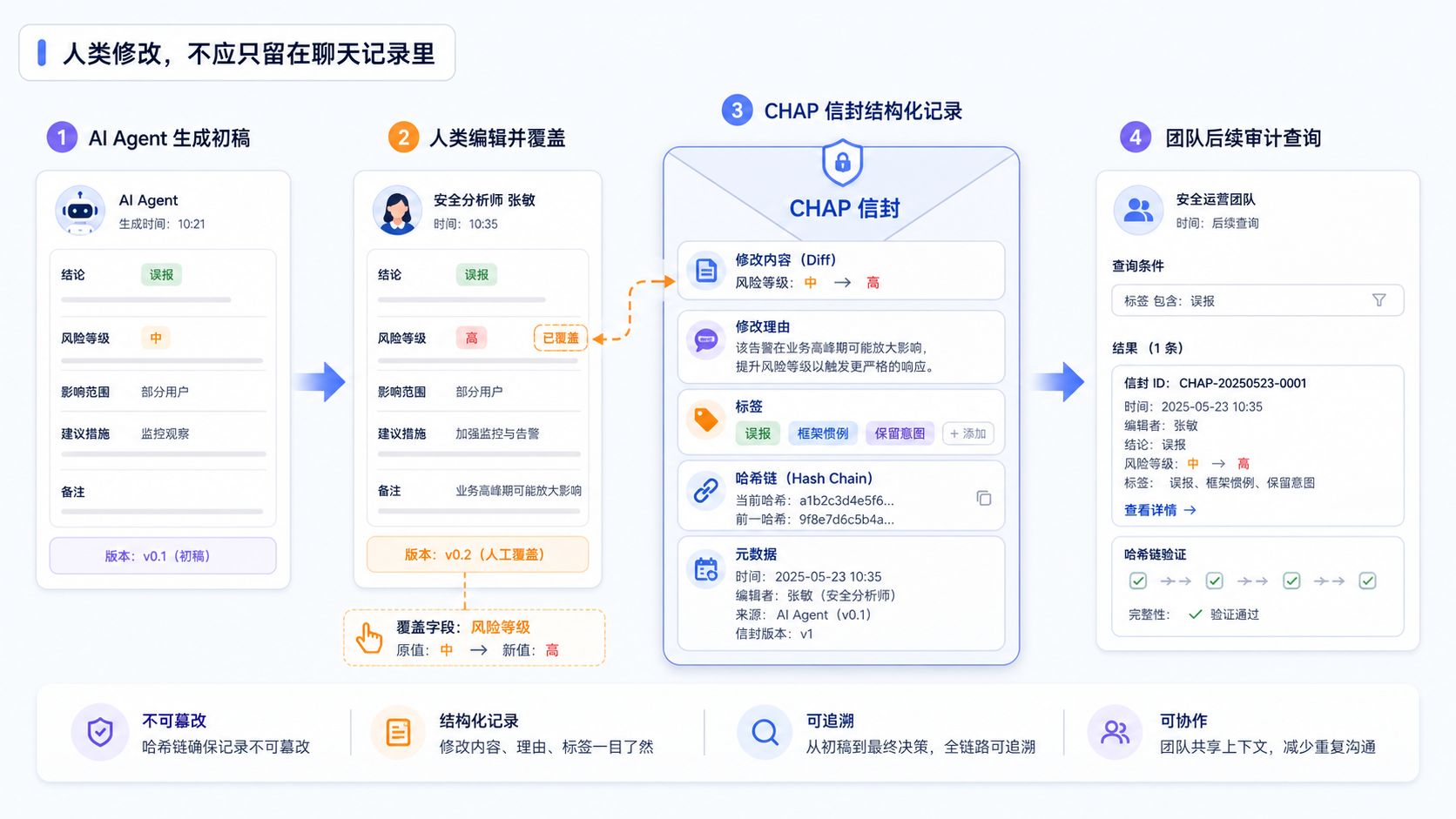
按 CHAP 项目的描述,它把人和 Agent 之间的协作放进一种可以查询、回放和验证的 envelope(信封)里。
这个说法听起来有点工程化,但可以用一个很普通的代码评审场景理解。
假设 Cursor 或 Claude Code 帮你审一个 Pull Request。它指出某段代码有风险,严重级别是 warning。你看完之后觉得它误判了,因为这是框架约定,不是 bug。于是你把 severity 从 warning 改成 info,并写了一句理由:“这是框架惯例,不是缺陷。”
在普通系统里,这件事可能只留下一个最终评论,或者留在某段聊天记录里。CHAP 希望它变成一条结构化记录:
- Agent 创建了什么任务
- Agent 产出了什么 artefact(产物)
- 人类改了哪里
- 修改是否保留了 Agent 原本意图
- 人类给出的理由是什么
- 这次覆盖属于哪类标签,比如 false-positive(误报)或 framework-pattern-misread(框架模式误读)
- 这条记录如何通过 hash(哈希)接到上一条记录之后
这背后的重点不是“格式漂亮”。重点是,三个月后你可以回头看:Agent 在哪些目录最容易误判?哪些评审意见总被人类降级?哪些 prompt 应该被改?哪些任务需要更明确的上下文?
这类数据如果靠人工标注,成本很高。但如果它来自日常工作中的批准、修改和拒绝,就会自然沉淀下来。
这也是 CHAP 最值得关注的地方:它把“人类纠正 Agent”从一次性的互动,变成了可积累的监督数据。
协作协议要解决四件事
我不认为 CHAP 现在就一定会成为行业标准。它还很早期,GitHub 仓库也只是一个公开草案和参考实现。但它提出的问题非常准确。
如果未来团队里有多个 Agent 和多个人共同工作,至少有四件事不能继续靠聊天记录凑合。
第一是上下文交接。
Agent 做完一个任务之后,下一个人或下一个 Agent 需要知道的不只是“结果是什么”,还包括“为什么这么做”“有哪些假设”“哪些地方被人类改过”。没有交接结构,长链路 Agent 很容易在下一步重新踩坑。
第二是权限边界。
人类批准、拒绝、覆盖 Agent 结果时,这些动作本身需要被记录。尤其在金融、法律、医疗、制造这类场景里,“是谁批准的”有时候和“结果是什么”同样重要。
第三是任务状态。
Agent 应用里最混乱的地方,往往不是执行,而是状态。一个任务到底是草稿、待审、已覆盖、已批准、已撤回,不能只藏在 UI 里。状态如果没有协议层表达,就很难跨工具流转。
第四是责任追踪。
这里的责任不是为了甩锅,而是为了复盘。Agent 的输出、人类的覆盖、系统的执行、后续的影响,要能被串起来。否则你很难判断问题出在模型、提示词、上下文、工具权限,还是人类审批流程。
这四件事,都是团队协作里本来就存在的问题。只不过 Agent 加入之后,它们被放大了。
它和 MCP、A2A 不是一类东西
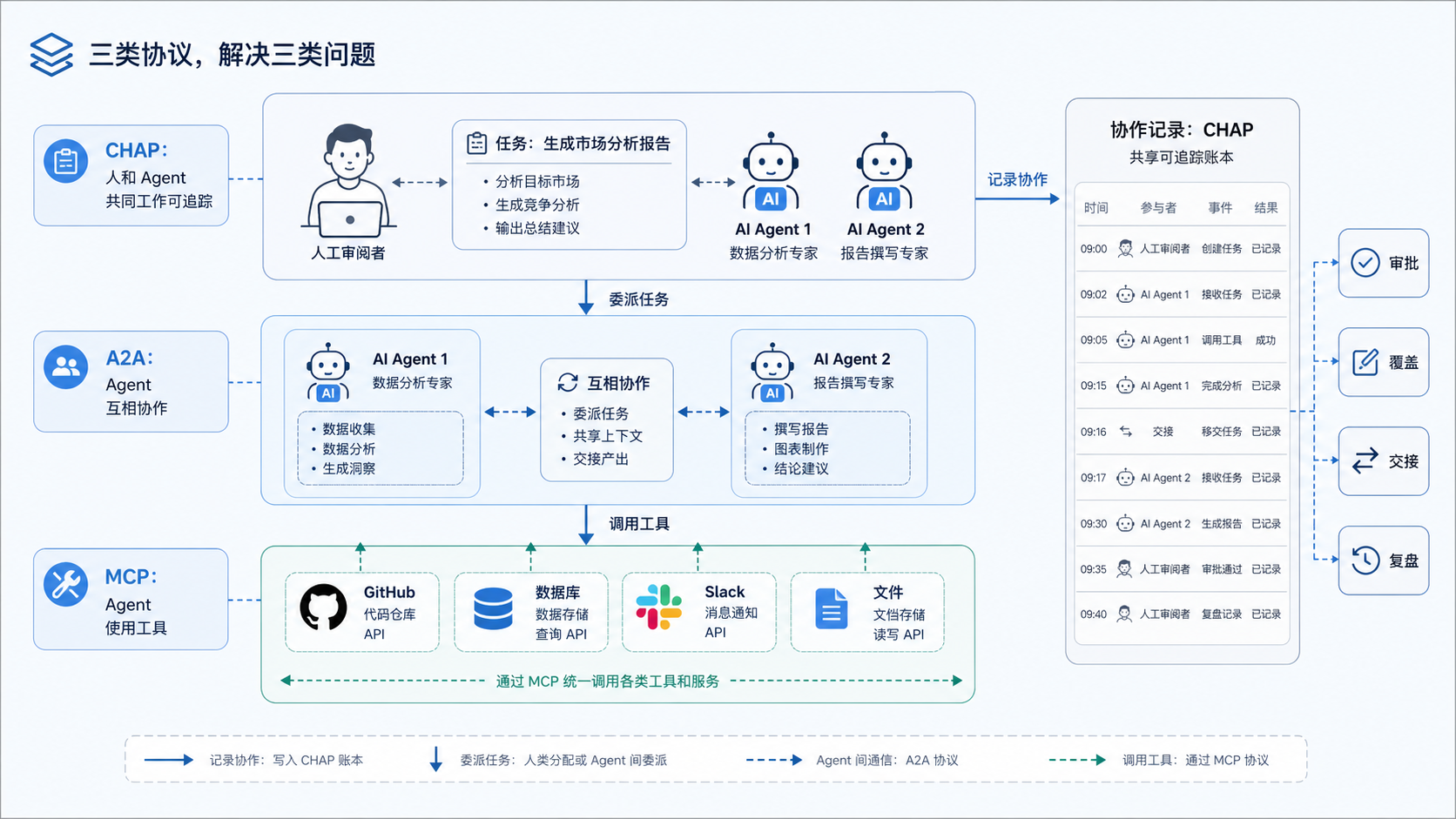
很多人看到“协议”两个字,会下意识把 CHAP 和 MCP(Model Context Protocol,模型上下文协议)、A2A(Agent-to-Agent,智能体间通信协议)放在一起比较。
更准确的关系可能是:MCP 解决 Agent 怎么使用工具,A2A 解决 Agent 怎么和其他 Agent 通信,CHAP 试图解决人和 Agent 做同一件事时,协作过程如何被记录和验证。
举个例子,一个 Agent 可以通过 MCP 调用 GitHub、Slack、数据库或内部系统;也可以通过 A2A 把任务交给另一个 Agent;但当它把结果交给人类审批,人类修改后继续推进,这个“共同工作”的过程需要另一种表达。
CHAP 项目自己也没有把它描述成 MCP 或 A2A 的替代品。它更像是贴在旁边的一层协作账本:工具怎么调用、Agent 怎么互相说话,可以由别的协议负责;人和 Agent 之间发生了什么,CHAP 来记录。
这个位置很微妙,也很重要。
因为 Agent 真正进入企业之后,最难的往往不是“能不能调工具”。工具调用会越来越标准化。更难的是:企业愿不愿意相信这个 Agent 参与了一个真实流程,出了问题能不能解释,审核时能不能还原,当人离职或日志过期后还能不能追溯。
这就不是单次模型调用能解决的问题了。
Claude Tag 之后,真正的问题是协作
最近围绕 Agent Identity(智能体身份)和 Claude Tag 的讨论,核心是给 Agent 一个可识别的身份:它是谁,代表哪个组织,拥有什么权限,能访问哪些资源。
这是必要的。没有身份,Agent 就很难进入严肃系统。
但只有身份还不够。
一个员工有工牌,不代表公司就知道他每次决策的依据。一个 Agent 有身份,也不代表团队就能理解它和人类之间的协作过程。
所以,身份更像是准入问题:你是谁,你能进哪里,你能做什么。CHAP 关心的是协作过程:你做了什么,人类怎么改,为什么批准,后续如何追踪。
这两件事会一起出现。先有身份,才有权限边界;有了权限边界,协作记录才有意义。否则所有记录都只是一堆没有主体的日志。
换句话说,Agent Identity 让 Agent 进入组织,Human-Agent Protocol(人类与智能体协议)让组织看懂 Agent 参与工作的全过程。
对开发者真正有用的启发
即使你完全不打算采用 CHAP,这个项目也给 Agent 应用开发者提了一个醒:不要只设计“调用模型”的接口,要设计“协作”的接口。
很多 Agent 产品的早期版本长这样:用户输入任务,模型执行,工具调用,返回结果。这个闭环适合 demo,也适合个人效率工具。但一旦进入团队场景,问题会马上变多。
你需要让用户能覆盖 Agent 的判断,而不是只能重新提示一遍。你需要记录覆盖理由,而不是只保存最终文本。你需要给修改打标签,而不是把所有人工干预都混成“用户编辑”。你需要能回放一次任务链,而不是只看最后一个输出。
这些设计看起来不性感,也不如“更强模型”“更多工具”容易传播。但真正跑过长期 Agent 工作流的人会知道,系统最后卡住的经常就是这些地方。
因为 Agent 不是一次性脚本。它越像同事,就越需要像同事一样接受交接、审查、复盘和约束。
现在别急着神化 CHAP
需要说清楚的是,CHAP 现在还只是早期项目。按公开仓库说明,它目前是 0.2 版本的 public draft(公开草案),提供 TypeScript 和 Python 参考实现、conformance harness(一致性测试工具)、MCP server transport(MCP 服务端传输)和 A2A server transport(A2A 服务端传输)等内容。
这并不等于它已经被广泛采用,也不等于它一定会变成事实标准。
更合理的看法是:CHAP 是一个早期信号。它说明 Agent 行业的讨论正在从“怎样让 Agent 完成任务”,转向“怎样让 Agent 在组织里可审计、可交接、可复盘地完成任务”。
这一步迟早会发生。
当 Agent 只是帮你改一段脚本,聊天记录够用了。当 Agent 开始参与合同审查、客户工单、代码评审、财务审批、药品生产记录,聊天记录就不够了。你需要知道每一步是谁做的,谁改的,为什么改,改完之后影响了什么。
也许最终胜出的协议不叫 CHAP,也许会由更大的平台推动,也许会被并入某个企业 Agent 标准。但“协作需要协议化”这件事本身,很难再绕过去。
结尾:Prompt 负责一次回答,协议负责长期协作
过去我们谈 Prompt Engineering(提示词工程),本质是在优化一次模型响应。后来谈 Context Engineering(上下文工程),是在优化模型看到的信息结构。现在 CHAP 这类项目把问题又往外推了一层:当模型、工具、人类、权限和任务状态混在一起时,整个协作过程该怎么被组织起来。
Prompt 解决“这次怎么说”。Context 解决“基于什么说”。Protocol(协议)解决“这件事如何被多人、多 Agent、多个系统共同承认”。
这三者不是互相替代,而是层级不同。
个人使用 Agent 时,好的 Prompt 和上下文可能已经足够。团队使用 Agent 时,你会开始需要任务状态、审批记录和修改理由。企业使用 Agent 时,这些东西必须变成可查询、可审计、可迁移的结构,而不是散落在聊天窗口里的片段。
所以 CHAP 最有价值的地方,不在于它今天是否成熟,而在于它把一个被忽略的问题摆到了桌面上:AI Agent 要成为真正的协作者,不能只会执行命令,还要能留下协作痕迹。
参考来源
以上来源主要用于观察 CHAP 的公开项目说明、设计目标和参考实现状态,不等同于对其生产可用性或行业采纳程度的独立验证。