今天整理选题时,看到一个挺有意思的 X 线索:有人在真实项目里把 Claude Code 和 GPT / Codex 放到同一个编码流程里用。大概思路是,Claude 负责看整体方向、约束改动范围,GPT 或 Codex 负责把具体代码写出来。
单看这条推文,当然不能说明什么行业趋势。它热度也不算大,不是那种一夜刷屏的爆款。但它刚好和另外几件事撞到了一起:OpenAI 在强调 Codex 要进入各种角色和工作流,还专门写了一篇 Harness engineering,讲他们怎么让 Codex 在内部项目里承担大规模开发;Reddit 上又有一堆人在讨论 Claude 的成本和用法。放在一起看,我觉得它反而戳中了 AI 编程里一个更真实的问题:我们是不是快要不再问“哪个模型最强”,而是开始问“这个活儿该交给哪个模型,以及要给它什么样的工作环境”?
以前我们很容易把 AI 编程理解成单模型问题。选一个最强模型,塞进 IDE 或命令行里,让它读需求、改代码、跑测试、修错误,最好一路把 PR 也交出来。
刚开始这么想很正常。毕竟过去两年模型升级太快,大家的直觉都是:只要模型再强一点,上下文再大一点,Agent 再自动一点,编程这件事就能被一个“万能助手”吃掉。
但真正用久了会发现,写代码不是一种能力,而是一堆能力混在一起。读项目结构是一回事,判断模块边界是一回事,补样板代码是一回事,修测试又是另一回事。一个模型很擅长长上下文和整体判断,不代表它每次写局部实现都最快;一个模型生成代码很顺,也不代表它适合决定系统应该怎么拆。
所以“Claude 负责架构,GPT 负责编码”这句话虽然有点粗糙,但它背后的变化值得聊:AI 编程可能正在从单兵作战,变成一个小型模型团队。
先别急着写代码
我自己用 AI 编程时,越来越不喜欢一上来就让模型改文件。
一个需求丢进去,模型立刻开始写,看起来很爽,实际上风险很高。因为代码一旦生成出来,人很容易被它带着走。它新建了一个文件,你就开始思考这个文件怎么补;它抽了一个 helper,你就开始接受这个抽象;它把状态放进某个组件,你就顺着这个方向修 bug。
问题是,第一步如果错了,后面越勤快,返工越大。
复杂一点的需求,真正值钱的是前 10 分钟:它应该进哪个模块?现有代码有没有类似模式?哪些地方不能碰?有没有更小的改法?测试应该覆盖什么?这些问题没有想清楚,后面写得再快也只是加速撞墙。
这也是为什么我觉得 Claude 更适合先站在前面。不是因为它“不会写代码”,而是 Claude Code 这种命令行代理形态,天然更适合读仓库、看上下文、做计划、设边界。让它先把系统结构看一遍,给出一个改动方案,再决定要不要动手,会稳很多。
这里要强调一下边界:我说的是 Claude Code 这个工作流里的体验,不是说所有 Claude 模型在所有场景里都天然适合做架构师。模型、工具权限、上下文质量、项目复杂度都会影响结果。把它说成“Claude 天生负责架构”就太玄学了。
更准确的说法是:在今天这批工具里,Claude Code 很适合承担“先把方向看清楚”的角色。
写代码这件事,反而可以交出去
等方向定下来以后,事情就变了。
比如你已经知道要改哪两个文件,要保持现有 API 不变,要补一个空状态测试,要把某个重复逻辑抽成函数。这时候再让模型继续讨论架构,反而有点浪费。
这种边界清楚、反馈明确的任务,GPT / Codex 往往很合适。它可以很快生成实现,补齐样板,改一批相似代码。错了也比较容易抓,因为范围小、测试能跑、diff 能看。
这就像真实团队里,tech lead 不一定要亲手写完所有业务代码。方向定了以后,让更擅长执行的人快速推进,再把结果拿回来 review,效率通常更高。
所以多模型分工的关键,不是给每个模型贴一个永久标签,而是把任务拆到合适的颗粒度。架构判断需要慢一点,局部实现可以快一点;需求边界需要保守一点,样板代码可以激进一点;上线前审查需要挑刺,写第一版实现时则可以先跑起来。
不同阶段对“好模型”的定义本来就不一样。
单模型工作流的问题
单模型当然还能用,而且很多时候足够好。写脚本、修报错、补一个函数、解释一段代码,没必要搞什么模型编排。你让一个强模型从头到尾做完,可能就是最省事的。
但任务一长,单模型的性格会被放大。
偏谨慎的模型,会不断问你要不要确认;偏激进的模型,会越改越多;偏局部最优的模型,会把小函数写得很漂亮,却忽略项目原来的风格。更麻烦的是,让同一个模型先设计、再实现、再审查,很容易变成它在审查自己的假设。
它当然能发现拼写、类型、边界条件之类的问题。但对“这个方向是不是一开始就不该这么做”,独立视角会更有价值。
多模型协作的一个好处,就是天然引入了不同错误模式。Claude 给方案,GPT 写实现,再让 Claude 或另一个模型看 diff,这比一个模型全程自说自话更接近真实工程流程。
不过这也不是灵丹妙药。多个模型如果没有共同上下文,只会互相误会。Claude 说“保持 API 不变”,GPT 如果没看到现有接口细节,照样可能改飞。GPT 写完代码,Claude 如果只看到摘要看不到完整 diff,review 也会变成空谈。
所以多模型协作真正难的不是“同时调用几个模型”,而是怎么把上下文、约束和验收标准传清楚。
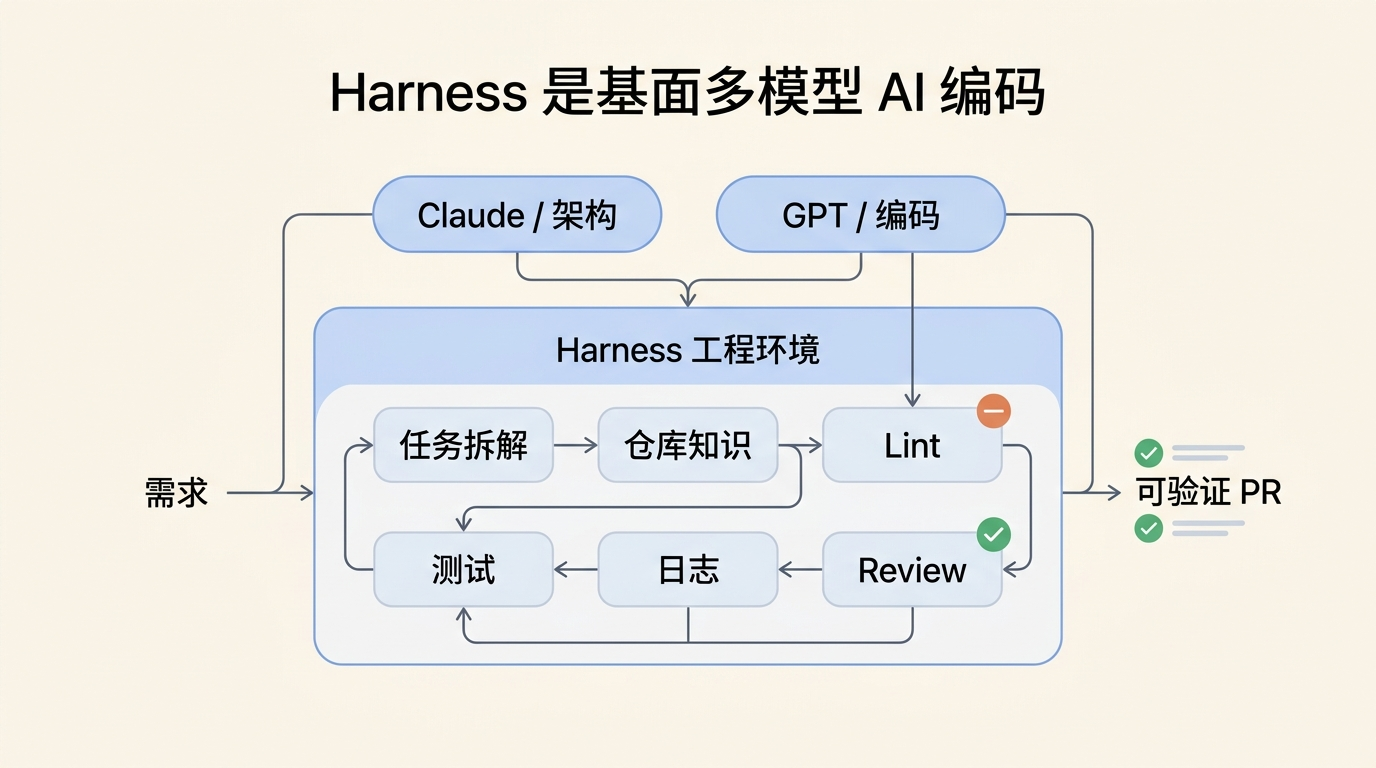
Harness 才是多模型分工的底座
这里就要说到 Harness。
OpenAI 那篇 Harness engineering 里,最值得注意的其实不是“Codex 写了多少行代码”,而是他们反复强调的一点:人类工程师的工作,正在从亲手写代码,变成设计环境、指定意图、搭反馈循环。
这句话放到多模型分工里也一样成立。你不能只是说“Claude 做架构,GPT 写代码”,然后把两个聊天窗口来回复制。真正能跑起来的工作流,需要一个 Harness 把它们接住。
所谓 Harness,我理解得很朴素:它不是某个神秘框架,而是一套让 Agent 能稳定工作的工程环境。里面至少包括几件事:任务怎么拆,模型能看到哪些资料,代码怎么跑,测试怎么反馈,日志怎么暴露,review 怎么触发,失败以后怎么回滚或重试。
OpenAI 的做法里有几个点很值得借鉴。
比如他们不是把所有规则塞进一个巨大的 AGENTS.md,而是把它做成目录入口,真正的架构文档、执行计划、质量标准、产品约束放在仓库里的结构化文档中。这样 Agent 先看到地图,再按需要去读细节,而不是一上来被一本 1000 页手册砸晕。
再比如,他们会把应用本身变得“对 Agent 可读”。UI 能通过浏览器工具验证,日志和指标能被查询,测试和 lint 能把错误直接暴露给 Agent。这样模型不是凭感觉说“我修好了”,而是能启动应用、复现问题、观察结果、再继续改。
还有一点我觉得特别关键:他们强调用机械规则约束架构和品味。依赖方向、文件大小、结构化日志、命名约定、数据边界,这些东西不能只靠口头提醒。能写成 lint 就写成 lint,能变成测试就变成测试。因为 Agent 最怕的是“差不多就行”的隐性标准,它需要可执行的反馈。
所以,多模型分工不是把几个模型拼在一起就完了。没有 Harness,Claude 的架构建议会丢,GPT 的实现会跑偏,review 也只能停留在嘴上。有了 Harness,不同模型才有同一套事实来源和反馈回路。
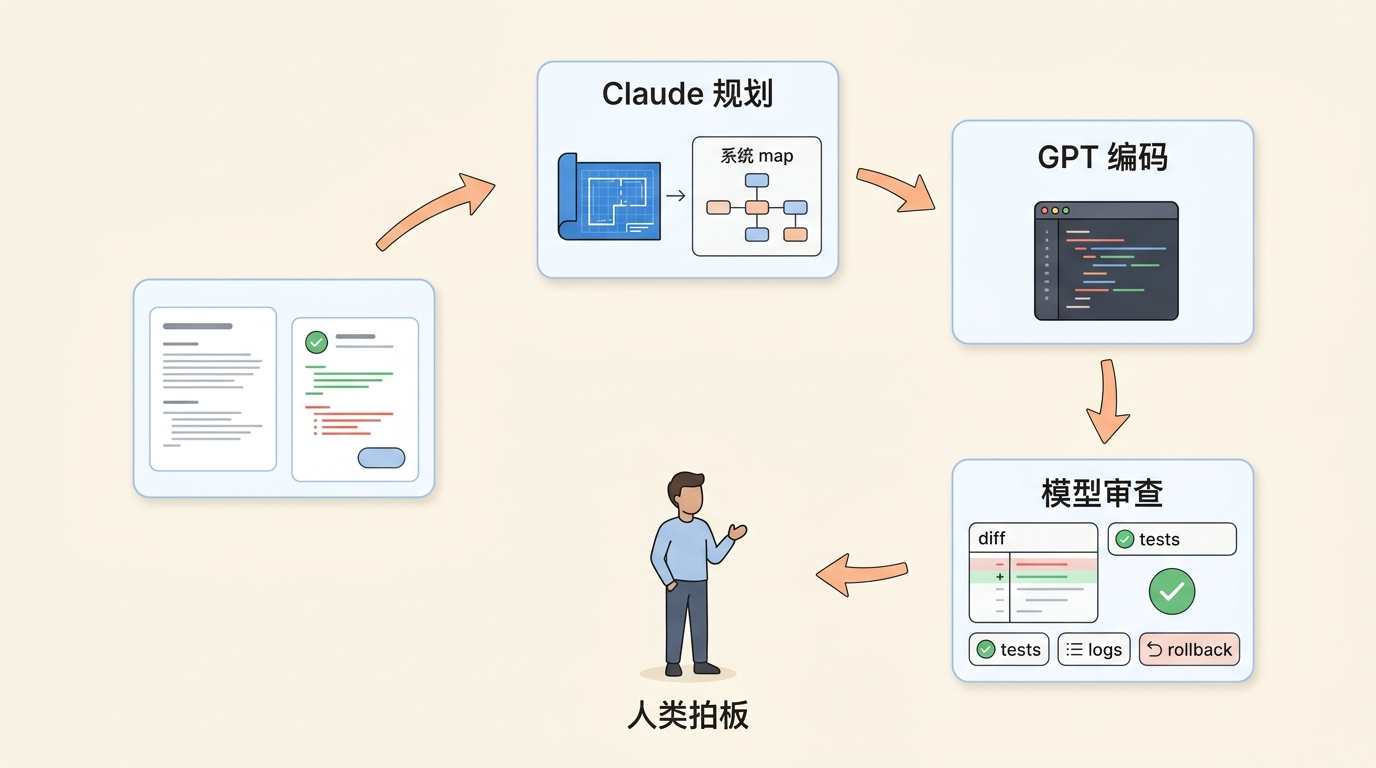
一个我觉得可用的流程
如果把这个思路落到个人开发者的日常工作里,我会尽量保持简单。
第一步,只让 Claude 看项目和需求,不急着写代码。让它说明:应该改哪里,为什么改这里,有没有类似实现,最小改动是什么,哪些风险要注意。这个阶段的产物最好是一份计划,而不是一堆新文件。
这里最好顺手把计划写进仓库,而不是留在聊天记录里。哪怕只是一个很短的 Markdown,也比散落在对话里强。Agent 看不到的东西,对它来说就等于不存在;下一轮换成 GPT / Codex 执行时,如果计划没有变成可读文件,它只能靠你转述。
第二步,把计划拆成小任务。比如“只改这个组件”“补这个 service”“新增这两个测试”“不要改现有接口”。这些任务可以交给 GPT / Codex 做。要求越具体,模型越不容易发散。
第三步,把实际 diff 拿回来审。这里不要只问“有没有 bug”,而要问更工程化的问题:有没有破坏项目约定?有没有过度抽象?有没有隐性状态重复?有没有更小的改法?测试是不是只覆盖了快乐路径?
如果有条件,review 不应该只靠模型读代码。把测试、lint、启动日志、浏览器截图、关键指标这些反馈接进来,效果会完全不同。Harness 的意义就在这里:它把“我觉得可以”变成“我跑过了、看到了、验证过了”。
第四步,人自己拍板。AI 可以写得很快,也可以审得很细,但产品取舍、风险接受、上线责任还是人的事。尤其是涉及权限、数据、付费、删除、迁移这些操作,不能因为是模型建议就直接放行。
这个流程看起来比“让一个模型全自动完成”麻烦一点。但我觉得它更接近可持续的 AI 编程。很多时候,慢在前面一点,后面会少很多返工。
成本也是原因之一
这次选题里,Reddit 上关于 Claude 费用的讨论也很热。这个背景不能忽略。
如果所有任务都用最强、最贵、最会思考的模型来做,体验当然好,但账单也会很真实。尤其是长上下文读仓库、反复跑工具、多轮修复,这些都是容易烧 token 的场景。
多模型分工某种程度上也是成本工程。
该用强模型判断方向时就用强模型。方向定了以后,一些局部实现、格式调整、批量修改,就可以交给更快或更便宜的模型。最后再把关键 diff 拿回来做高质量审查。
这和人类团队分工很像。不是每个任务都要最资深的人亲自做,但关键节点必须有人兜住。
当然,省钱不能变成瞎省。比如架构方向、权限边界、安全逻辑、数据迁移这些地方,如果为了省一点模型费用让弱模型硬做,最后出问题的成本可能更高。多模型工作流真正要学的是“把钱花在关键判断上”,而不是无脑降级。
工具会把这种分工藏起来
现在手动做多模型协作还挺笨。一个窗口问 Claude,一个窗口开 Codex,再把输出复制来复制去。上下文容易丢,格式也乱,人还要在中间当搬运工。
但我不觉得这种状态会持续太久。
更合理的形态,是工具层把角色封装好。你发起一个任务,它先用适合规划的模型读项目,再把小任务派给适合实现的模型,最后用审查模型看 diff。用户不一定知道背后调用了几个模型,只会看到任务经过了计划、实现、验证几个阶段。
到那时,我们讨论的对象可能就不是 Claude、GPT、Gemini 某个品牌,而是 planner、coder、reviewer、tester 这些角色。模型供应商变成后端能力,开发工具负责调度。
这有点像云计算。早期大家爱聊服务器配置,后来更关心服务怎么编排、故障怎么恢复、资源怎么弹性伸缩。AI 编程也可能经历类似变化:从模型参数竞争,走向模型能力编排。
但别把它想得太完美
多模型分工有吸引力,但它也会制造新麻烦。
最直接的是责任边界。Claude 说这个方案可行,GPT 按方案写了,另一个模型 review 时又说不建议这么做,最后听谁的?如果没有明确规则,多模型协作很容易变成几个 AI 在你面前开会。
还有上下文问题。每多一个模型,就多一次信息转述。转述就会丢细节。原始需求里的一个限制、项目里的一个约定、测试里的一个隐含假设,都可能在传递中消失。
再就是延迟。一个任务如果要规划、实现、审查、再修复,质量可能提高,但响应时间也会变长。不是所有事情都值得这么做。小改动、小脚本、小 bug,用单模型一次性处理就好。
所以我不觉得“多模型”本身值得崇拜。真正有价值的是三个东西:角色清楚、上下文稳定、验证明确。少了这三个,模型越多越乱。
程序员会变成什么?
如果这个趋势继续下去,程序员的角色会更像调度者,但不是那种脱离技术的管理者。
你还是得懂代码。不懂代码,就看不懂 diff,也判断不了模型是不是把项目带偏。你还得懂架构,因为任务怎么拆、边界怎么定、哪些地方不能碰,这些不是模型自动替你负责的。
只是工作重心会变。以前重点是“我能不能把代码写出来”。后来变成“我能不能让 AI 帮我更快写出来”。再往后,可能会变成“我能不能把任务交给合适的模型,并设计出可靠的验收方式”。
这其实更考验工程能力。会写提示词只是很小一部分。真正难的是把需求拆清楚,把约束写明白,把反馈闭环建起来,把 AI 产出的东西收进一个可维护的系统里。
不会用 AI 的程序员会吃亏,只会让 AI 写代码的程序员也会遇到瓶颈。更有优势的,可能是能把 AI 当成一个工程团队来调度的人。
最后说两句
“Claude 负责架构,GPT 负责编码”不应该被理解成固定公式。今天这个组合好用,明天也可能换成 Gemini、本地模型、专用代码模型,甚至同一个模型的不同配置。
真正的新常态,不是某两个模型品牌绑定在一起,而是按角色使用模型。
一个模型负责看方向,一个模型负责写实现,一个模型负责挑错,一个模型负责跑测试。人不再只是和一个聊天框对话,而是在管理一组能力不同、脾气也不同的 AI。
这听起来更复杂,但也更接近软件工程本来的样子。编程从来不只是敲代码,它还包括判断、取舍、协作和验证。AI 让代码生成变快以后,这些原本就重要的东西,反而会变得更重要。
参考资料
- X:Matt Rogish 关于 Claude Code 与 GPT / Codex 分工协作的推文
- OpenAI:Codex for every role, tool, and workflow
- OpenAI:Harness engineering: leveraging Codex in an agent-first world
- Claude:Introducing dynamic workflows in Claude Code
- Reddit:How can we reduce costs?
- YouTube:Ruflo - Multi-Agent AI Harness for Claude Code & Codex