
过去的一年, 我一直在使用 GitHub Copilot 作为代码助手, 它提供了补全、问答等功能, 付费订阅 10 美元 / 月.
说实话这个价格并不算贵, 但最近 Copilot 对问答范围进行了限制, 导致很多与开发相关的问题无法得到解答.
后续我也尝试了 Codium AI, 响应速度不尽人意.
最近发现了一个开源的代码助手 Continue, 支持调用本地和云端的模型, 包括 Cloudflare 的 worker AI.
介绍
Continue 本质是个帮你向大模型发起请求的客户端.
当你编写代码的时候, 它会获取代码的上下文, 向模型发起请求, 获取结果后处理等待你的命令 (tab), 再拼接到代码中去.
本地部署
本地部署可以使用 Ollama 或 lmstudio.
这是两个非常方便的大模型集成工具, 同时支持 Mac、windows 以及 Linux, 帮助你快速在本地运行大模型.
这里我选择在 Mac 上运行 Ollama, 在官网 Ollama 可以下载到安装包, 安装过程中记得勾选命令行工具.
Ollama ollama. Com
Get up and running with large language models.

配置要求
配置要求取决于你要使用的模型, 这里推荐 llama 3.
Llama 3 是 meta 开源的模型, 也是目前最强的开源模型, 可以获得比较好的补全效果.
模型有两个变体, 8 B 需要至少 16 g 的内存和 8 g 的显存, 70 B 则需要 64 g 以上的内存.
默认运行的 8 B 版本即可满足正常需要.
运行模型
安装完成后进入 terminal, 输入以下命令获取 llama 3 模型:
|
|
模型拉取完成后就会自动运行.
测试用中文让他编写一个 python 版的 hello-world.
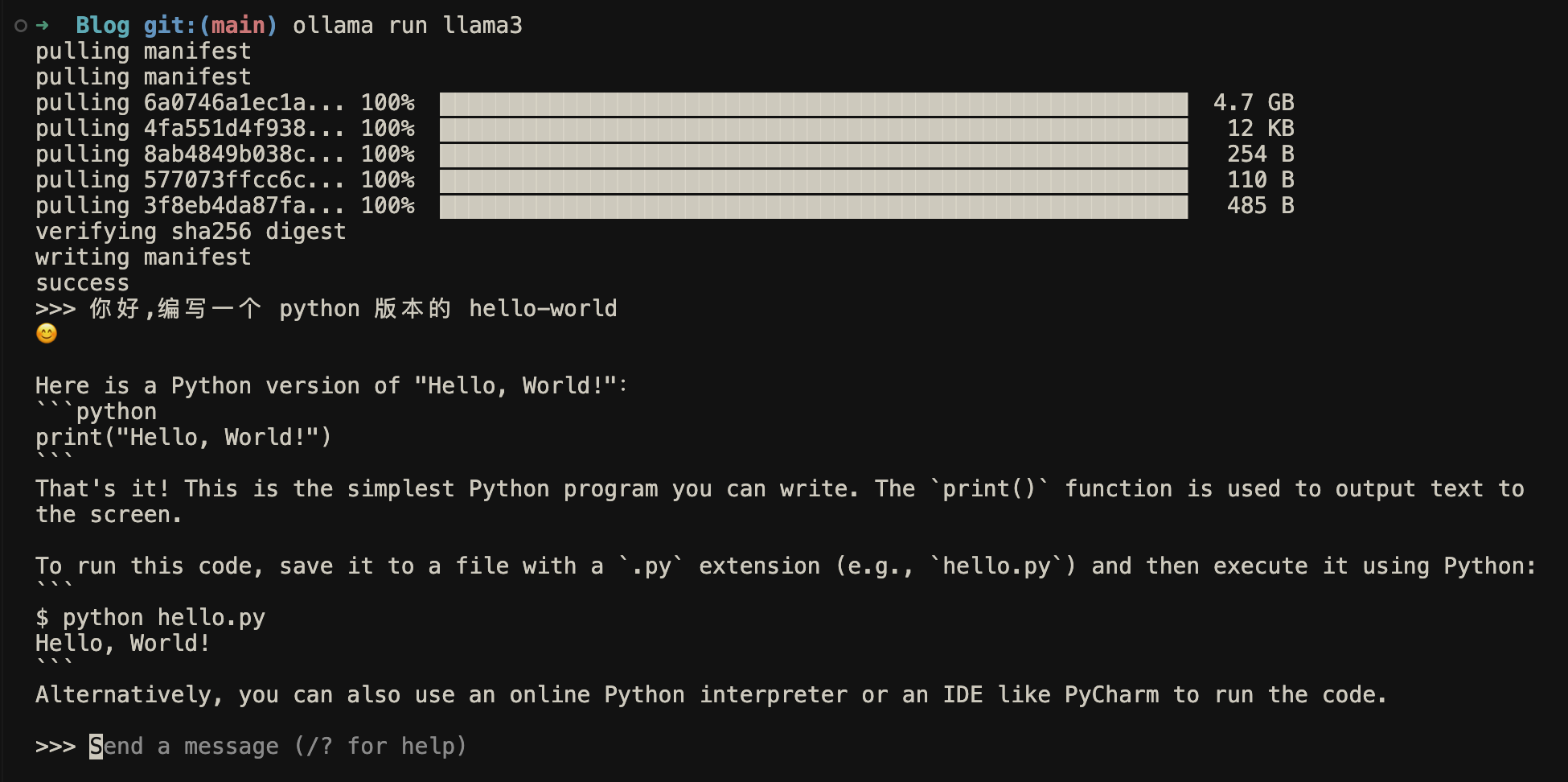
输入 /bye 可以退出运行.
配置 Continue 插件
安装完成左侧边栏会展示 Continue 的对话框:
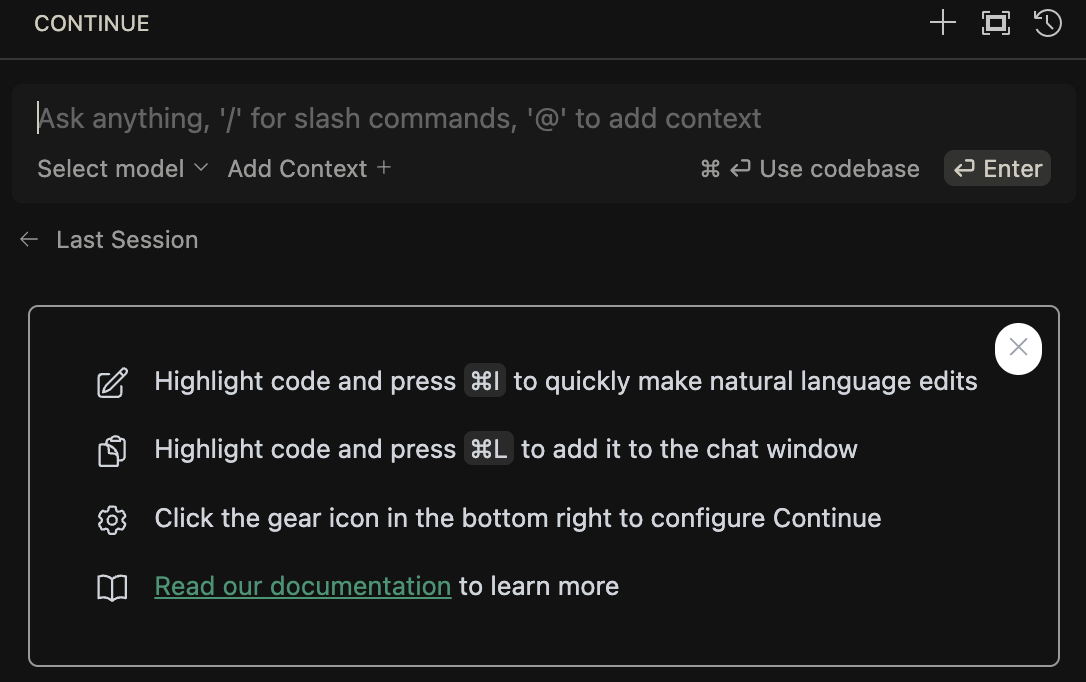
这个时候是无法对话的, 因为还没有选择模型, 点击 Select model -> Add Model, 向下拉, 找到:
然后再选择第一个 Autodetect 选项:
返回对话, 选择 Ollama 选项:
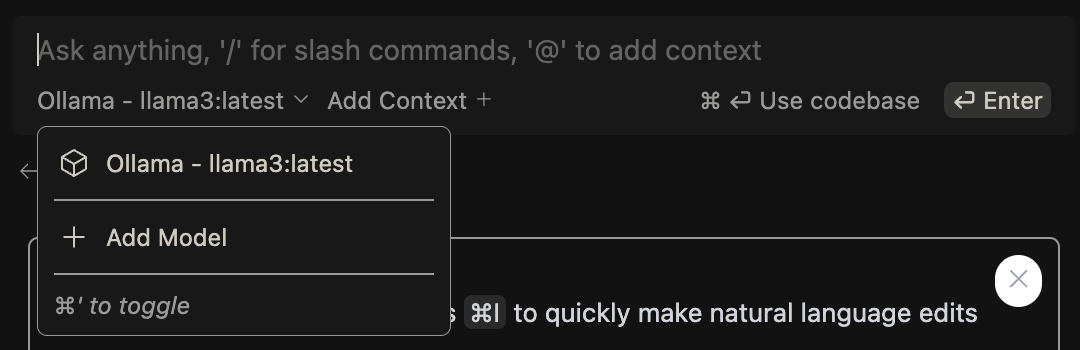
确保你的模型正在后台运行, 接下来就可以开始对话了.
自动补全设置
虽然现在已经可以完成对话, 但还是无法补全.

因为补全默认使用的是 Starcoder2 3b 模型, Starcoder 是一个针对代码场景针对性强化的模型.
你可以使用以下命令启动该模型.
|
|
模型启动后就可以触发补全.
如果你的机器性能不足以同时运行两个模型, 你也可以设置补全也使用 llama3:
在插件侧边栏的角落, 找到这个小齿轮图标
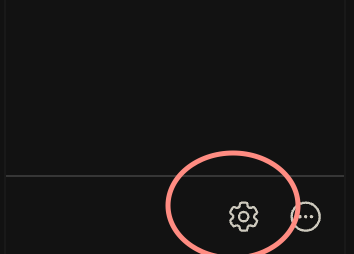
点击就会进入配置文件 (也可以打开~/. Continue/config. Json), 将 tabAutocompleteModel 字段的两个高亮行的值修改为 llama3 即可.
|
|
如果你希望补全 markdown 之类的的文本文件, 那我建议使用 llama 3 进行补全
Cloudflare worker AI
有一些轻薄本机型不能在本地运行大模型, 也可以使用 Cloudflare worker 的 AI 模型.
Cloudflare 提供了免费额度, 不过是以 神经元 作为单位, 可以在这个页面查看估算.
每日的免费额度大体相当于 500 次调用, 每次 100 个入参字符和 500 个返回字符, 足以应对正常的开发场景.
然后打开配置文件, 增加一个 models 字段值, 并修改 tabAutocompleteModel 字段.
|
|
修改 accountId 为你自己的账户 id, apiKey 是你刚刚保存的 key 值.
账户 id 获取比较麻烦. 你必须要有一个 Cloudflare 下的域名或者一个 Worker, 具体可以参照官方文档和这两个页面:
model 字段的值可以自行修改, 不同的模型需要的算力不同, 对 神经元 的计费方式也会有影响.
如果你发现免费额度不足以覆盖, 可以修改为低一级的模型.
点击链接可以看到完整的模型列表:
Models | Cloudflare Workers AI docs developers. Cloudflare. Com
Browse our entire catalog of models:
总结
Llama 3 有不错的对话效果, 但是速度比较慢, 代码补全也比较笨.
Starcoder 2 速度要快得多, 补全效果也更好, 但对文本的处理能力偏弱.
个人推荐使用 Cloudflare 的 llama 3 模型进行对话, 本地运行 starcoder 2 进行补全, 是比较完美的解决方案.