
Google 发 Gemma 4 12B,我第一眼看到的不是“又一个 12B 开放模型”。
本地模型这件事,已经没那么稀奇了。过去两年,很多人都在 Ollama、LM Studio、llama.cpp、MLX 里跑过各种 7B、14B、32B 模型。能跑起来当然很开心,但跑起来以后,大多数时候还是回到一个聊天框:问一句,答一句;贴一段代码,解释一段;让它写点东西,再复制出来用。
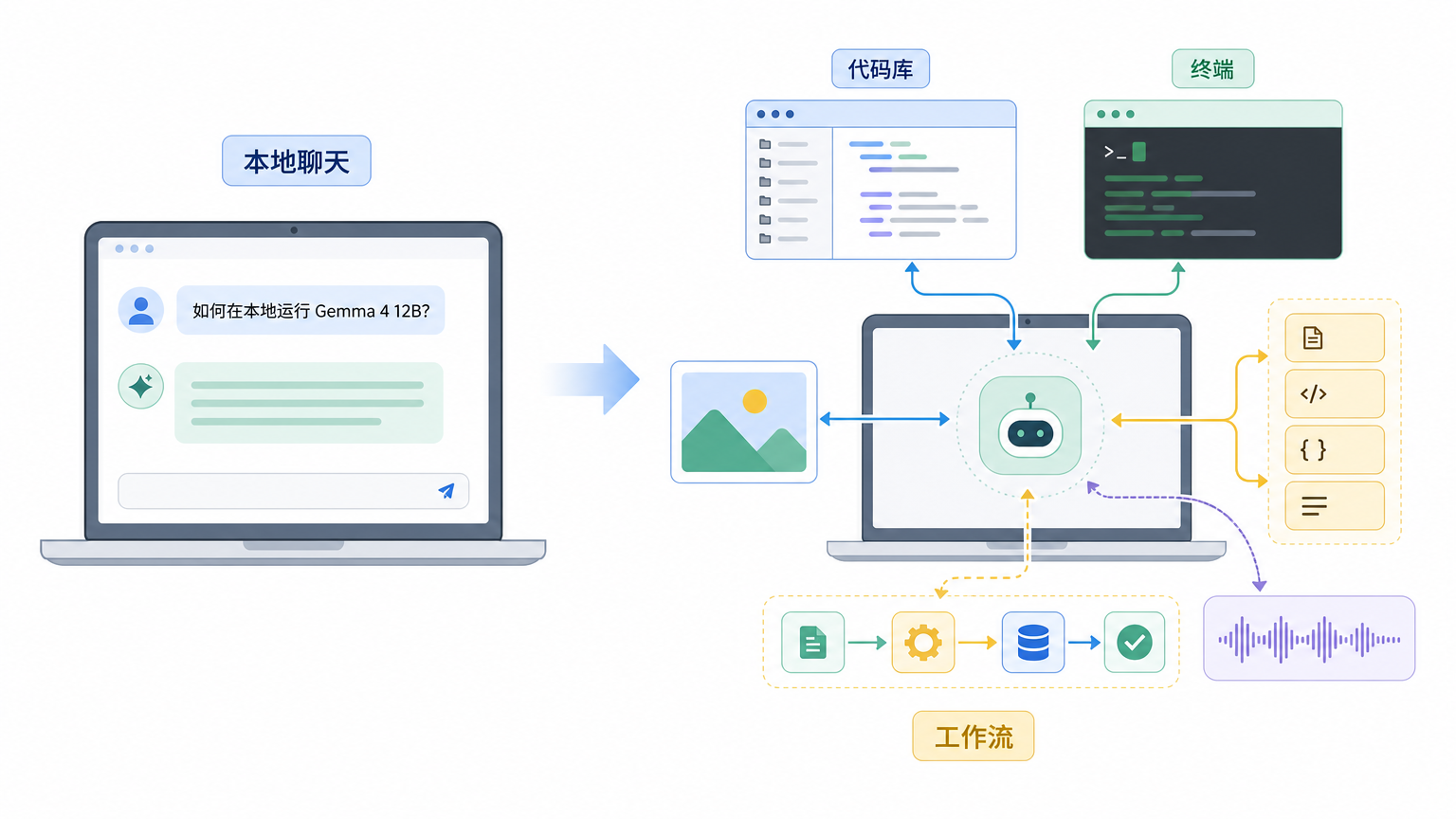
Gemma 4 12B 这次不太一样的地方,是 Google 很明确地把它放进了“本地 agentic workflows”这个语境。
按官方介绍,它是一个中等规模、多模态、开放模型,可以在 16GB VRAM 或统一内存设备上本地运行。它支持推理、编码、多模态输入,也可以通过 LiteRT-LM 启动本地 OpenAI-compatible API server。Google Developers Blog 另一篇文章的标题更直接:把 Gemma 4 12B 带到笔记本上,解锁本地智能体工作流。
我觉得这里的关键词不是 12B,也不是多模态,而是“工作流”。
过去讨论本地 AI,常问的是:显存够不够?速度怎么样?中文行不行?现在可以多问一句:它能不能接进开发工具、代码库、终端、文件系统和本地数据,变成一个真正能帮你做事的本地 Agent?
Gemma 4 12B 的意义就在这里。它不太可能替代云端最强模型,但它让“本地模型”往前走了一步:从本地聊天框,走向本地智能体运行时。
本地 AI 以前常常停在聊天框
以前搭本地模型,目标很朴素:先跑起来。
装 Ollama,拉一个模型,终端里输入一句话,看到它回复,事情就成功了一半。如果再接进 Open WebUI 或 LM Studio,有一个像样的聊天界面,就更有成就感。
这当然有用。隐私更好,成本可控,断网也能用。对个人知识库、代码解释、简单写作、本地资料总结来说,本地模型一直有吸引力。
但它的短板也很明显:很多本地模型最后只是一个“本地 ChatGPT”。
你问,它答;你贴一段代码,它解释;你给一个需求,它生成一段建议。它像一个助手,但还不像一个真正参与工作流的执行者。
进入工作流,需要多几层东西。模型要能被工具稳定调用,工具要有标准接口,上下文要能从代码库、文件、终端或浏览器里进来,结果要能被验证,失败后要能重试或交还给人。
所以 Gemma 4 12B 这次值得关注,不只是因为它是一个新模型。Google 同时给出了 LiteRT-LM、本地 OpenAI-compatible server、Google AI Edge Gallery、Gemma Skills Repository 这些线索。它们合在一起,指向的不是单个模型,而是一套本地优先的 Agent 工作流。
Gemma 4 12B 带来的几个变化
按 Google 官方介绍,Gemma 4 12B 是一个 unified、encoder-free 的多模态模型。它介于更小的边缘模型和更大的 26B MoE 模型之间,主打在日常笔记本上运行。
我会把它的变化拆成四点看。
第一,它把门槛压到了普通高配电脑能尝试的范围。Google 提到 16GB VRAM 或统一内存设备。这个要求不算低,但也没有高到只属于服务器。一台 16GB 显存的游戏本,或者统一内存足够的 Apple Silicon 设备,都可以开始试。
第二,它不是纯文本模型。官方提到它支持视觉与音频输入,是 Gemma 4 系列里首个支持原生音频输入的中等规模模型。对本地 Agent 来说,这个点很有想象空间。一个本地工具可以看截图、读图表、处理录音、分析代码,再把结果写回本地文件。
第三,它被明确放在 coding 和 agentic workflows 场景里。Google DeepMind 的 Gemma 页面把 12B、26B、31B 这一组定位为个人电脑和工作站上的本地智能,用于高级推理、IDE、编码助手和智能体工作流。
第四,接入路径更标准。Ollama 可以直接跑 gemma4:12b,LiteRT-LM 可以启动 OpenAI-compatible server,官方还提到 Continue、Aider、OpenCode、Hermes 等工具可以指向本地 endpoint。
这就把问题从“我能不能和它聊天”,变成了“我的开发工具能不能把它当成本地模型服务来用”。
先降温:它不是云端大模型的替代品
这里要先说清楚,Gemma 4 12B 很有意思,但它不是 Claude、Gemini Pro、GPT 这类云端 frontier model 的替代品。
12B 仍然是 12B。它适合本地代码解释、小范围重构、日志分析、文档整理、轻量 Agent 流程、隐私敏感资料处理。它不适合把一个大型项目完整交给它自动规划、开发、测试、上线,也不适合需要极高推理稳定性的任务。
更现实的用法是分层。
日常小任务、本地资料、低风险代码分析,可以交给 Gemma 4 12B 这类本地模型。复杂架构决策、关键生产代码、需要强推理和高可靠性的任务,仍然交给云端强模型。
本地模型的价值,不是“替代一切”。它更像是把大量原本不值得调用云端模型的任务吃下来。它离你更近,不按 token 计费,也更适合放进本地工作流里反复调用。
路线一:先用 Ollama 跑起来
如果只是想先试试 Gemma 4 12B,Ollama 是最省事的路线。
1. 安装 Ollama
macOS / Linux 可以用官方安装脚本:
|
|
Windows 直接去 Ollama 官网下载安装包:
|
|
安装完成后检查版本:
|
|
2. 拉取并运行 Gemma 4 12B
12B 版本可以这样运行:
|
|
如果你只想用默认版本,也可以:
|
|
Ollama 页面列出的常用标签包括:
|
|
其中 gemma4:12b 页面标注大小约 7.6GB,上下文为 128K,支持 Text/Image。实际体验还要看你的显存、内存、系统和模型标签。别只看“能跑”,代码工作流里上下文长度、响应速度和稳定性都很关键。
3. 启动 Ollama 服务并测试 API
Ollama 安装后通常会自动运行本地服务。如果需要手动启动:
|
|
默认服务地址是:
|
|
可以用 curl 测一下本地 API:
|
|
如果能看到返回,说明模型服务已经能被本地程序调用。
4. 需要时设置上下文长度
做代码任务时,上下文窗口会影响体验。Aider 文档里提到可以通过环境变量启动 Ollama:
|
|
Windows PowerShell 当前会话可以这样写:
|
|
如果你的机器内存比较紧,不要一上来就把上下文拉得很大。上下文越长,prefill 越慢,内存压力也越高。先从 8K 或 16K 这种比较保守的设置试起,通常更稳。
路线二:把 Gemma 4 12B 接进 Aider
Aider 是一个不错的测试场景。它不是单纯聊天,而是能读取项目文件、提出修改、生成 diff。你可以很快感受到本地模型到底能不能参与代码工作流。
1. 安装 Aider
Aider 官方推荐的安装方式:
|
|
然后进入你的项目目录:
|
|
2. 设置 Ollama 地址
macOS / Linux:
|
|
Windows CMD:
|
|
Windows PowerShell 当前会话:
|
|
3. 启动 Aider 使用 Gemma 4 12B
先确保 Ollama 已经有模型:
|
|
然后启动 Aider:
|
|
Aider 文档建议 Ollama 聊天模型使用 ollama_chat/<model> 这种形式。进入以后,不要一上来就让它改一堆文件。可以先给一个只读任务:
|
|
确认它能正确读项目,再尝试小改动:
|
|
本地模型做代码任务时,最好先让它读、解释、列计划,再让它动手。这个节奏比直接“帮我改完”慢一点,但翻车少很多。
路线三:用 LiteRT-LM 跑 OpenAI-compatible server
Ollama 适合快速上手,LiteRT-LM 更接近 Google 这次官方强调的本地 agentic workflow 路线。
Google Developers Blog 里给出的核心命令是:
|
|
文章里的示例服务地址是:
|
|
可以用 curl 验证:
|
|
这里有个小坑要提前说。写这篇文章时,我只能从 Google Developers Blog 找到 import、serve 和 curl 示例,但 LiteRT-LM CLI 文档页本身只明确写了支持 uvx、uv、pip 安装,没有在可抓取内容里给出完整安装命令。所以你真要部署,最好打开 LiteRT-LM 官方安装说明或项目仓库,确认包名、Python 版本和平台要求后再装。
一旦 litert-lm serve 跑起来,它的意义就很大。很多工具并不关心背后是云端 OpenAI、Ollama,还是本地 LiteRT-LM。只要它提供 OpenAI-compatible endpoint,你就可以把 Aider、Continue、OpenCode、Hermes 这类工具指向本地服务。
这一步,才是“本地模型”变成“本地 Agent runtime”的关键。
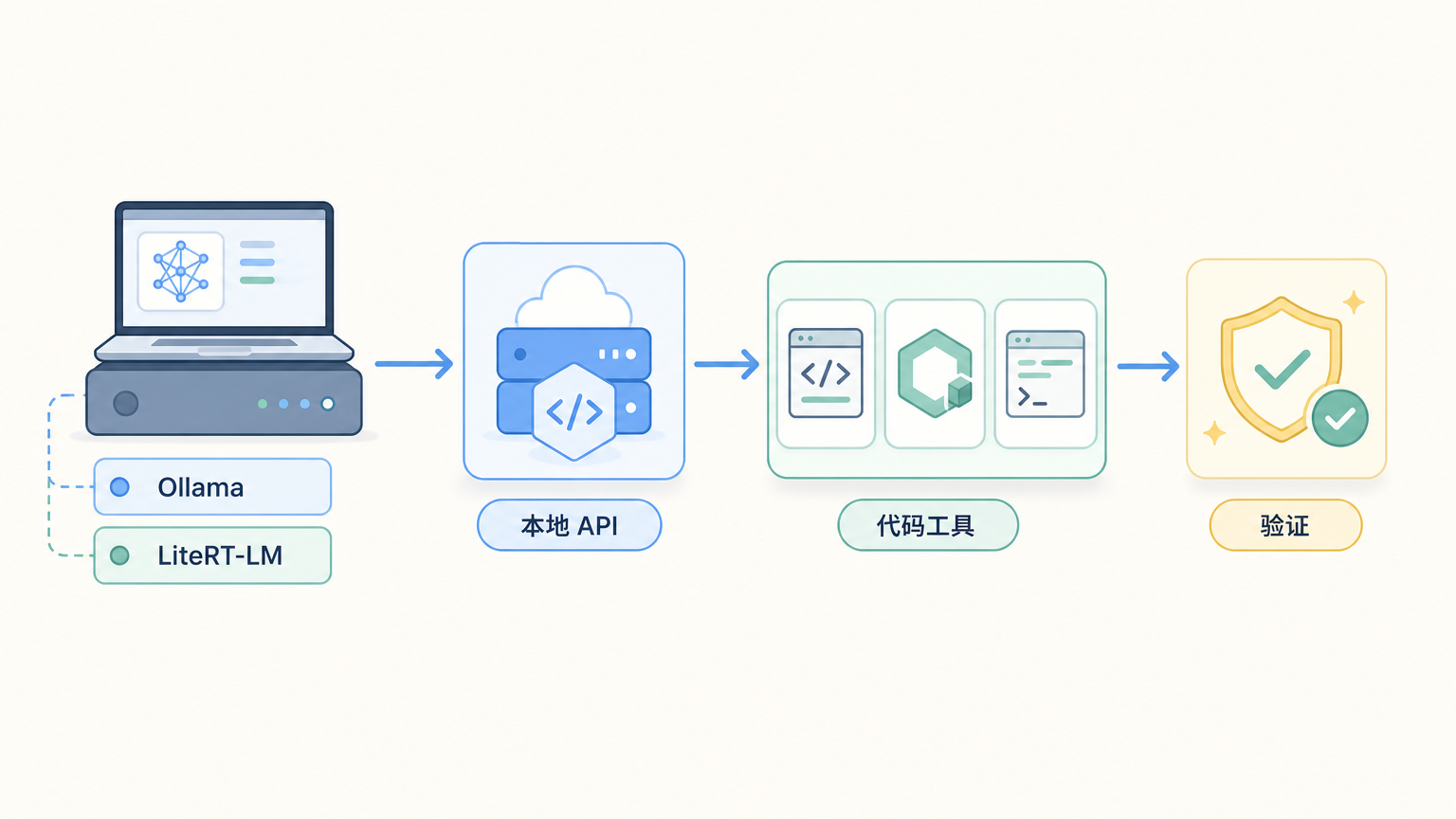
接入 OpenAI-compatible 工具时怎么填
不同工具的配置文件不一样,但核心信息通常就几个:
|
|
如果走 Ollama,通常是:
|
|
如果工具要求 OpenAI 风格 endpoint,而你用 LiteRT-LM,就优先试:
|
|
如果工具原生支持 Ollama,那就优先用 Ollama provider,少一层兼容转换。
这里不要死记配置。更稳的做法是先用 curl 确认本地服务可用,再去工具里填 endpoint。否则你很难判断问题出在模型、服务、端口、模型名,还是工具配置。
我建议这样开始用本地 Agent
如果你想用 Gemma 4 12B 做本地智能体,不建议第一天就让它自动改整个项目。
比较稳的起步方式是这样:先只让它读项目,让它总结目录结构、技术栈、入口文件、测试命令和潜在风险。这个阶段不要修改文件。
然后让它做小范围解释,比如解释某个模块为什么这样设计,某个报错可能来自哪里,某段代码有哪些边界条件。
再下一步,让它生成计划。要求它列出准备修改的文件、改动范围、不改哪些东西、如何验证。
最后才让它改一个低风险文件,比如 README、小工具函数、测试用例、配置注释。改完以后接入验证。能跑测试就跑测试,能跑 lint 就跑 lint,前端功能最好打开页面检查。没有验证,就不要让它说“完成”。
这个流程比一句话让 AI 改代码慢一点,但更适合本地模型。12B 模型不是不能做事,只是更需要清楚边界和短反馈。
本地 Agent 真正好用,不是因为模型突然无所不能,而是你给它安排了更适合它的任务形状。
Windows、macOS 和显存注意事项
Gemma 4 12B 官方说可以在 16GB VRAM 或统一内存设备上运行,但这不等于所有 16GB 机器都能流畅跑所有场景。
如果你是 Windows + NVIDIA GPU,优先试 Ollama 或 LM Studio。它们对入门最友好,遇到问题也更容易排查。
如果你是 Apple Silicon,统一内存越大越好。Google AI Edge Gallery 和 LiteRT-LM 对 macOS 的本地体验更值得关注。Ollama 的 MLX 标签也可以试,但不同标签支持的输入模态和性能可能有差异。
如果你只有 16GB 系统内存,没有独立 GPU,就不要对 12B 的速度抱太高期待。可以先试 E2B/E4B,或者选择更小、更偏边缘的模型。
如果你要做代码 Agent,显存只是一个条件。磁盘、CPU、内存、上下文长度、工具调用频率,都会影响体验。尤其是长上下文代码任务,本地模型慢不是 bug,而是成本从云端账单转移到了你的机器时间上。
什么时候用本地,什么时候用云端
Gemma 4 12B 更适合放在“第一层智能”里。比如本地代码库解释、README 和脚本修改、日志分析、隐私敏感资料总结、低风险测试生成、本地数据分析脚本草稿,以及一些会反复调用的小型 Agent 工作流。
它不太适合大型架构重构、高风险生产代码自动修改、复杂多文件长期自主开发,或者需要极强推理稳定性的设计决策。涉及外部副作用和安全审查的任务,也不要轻易交给本地模型自动做。
这样分工,本地 AI 才不会变成云端 AI 的低配替代。它会变成一个新的工作流层:便宜、快速、隐私友好,负责那些离你最近、最频繁、最适合本地处理的任务。
本地 AI 的下一站,是本地工作系统
Gemma 4 12B 这次最有价值的地方,不是让我们多了一个可以下载的模型。
它让本地 AI 的讨论从“模型能不能跑”,转向“工作流能不能跑”。
当你能在笔记本上启动一个 OpenAI-compatible server,把 Aider、Continue、OpenCode、Hermes 之类工具接进来,再让模型读本地文件、生成代码、跑脚本、处理图片或音频,本地 AI 就不再只是一个聊天窗口。
它开始像一个本地工作系统。
当然,这个系统还不会完美。12B 模型有能力边界,本地推理有性能限制,多模态和工具调用也需要更成熟的 harness。但方向已经很清楚:未来的个人电脑,不只是运行应用,也会运行自己的本地智能体。
云端模型负责最难的问题,本地模型负责离你最近、最频繁、最隐私的那部分工作。
这才是 Gemma 4 12B 真正值得关注的地方。
不是因为它让本地 AI 第一次能跑。
而是因为它让本地 AI 开始更像一个可以接入工具、执行任务、参与工作流的 Agent runtime。