先把边界说清楚:这篇文章基于「Kimi K2.7 Code 编程模型已上线 Kimi Code、API 开放平台」的公开摘要,以及当天 YouTube、X 上出现的一些早期评测和接入讨论。里面提到的「代码基准提升 21.8%」「平均 token 消耗减少 30%」「智能体自主执行能力提升约一成」「价格与 K2.6 持平」,我会按公开传播口径来讨论,不把它们当作已经被充分复现的结论。
即便如此,Kimi K2.7 Code 还是值得写。
它有意思的地方,不只是国产编程模型又刷了一轮分数,而是它把一个平时不太好讲清楚的问题摆到了桌面上:Agent(智能体)到底贵在哪里?
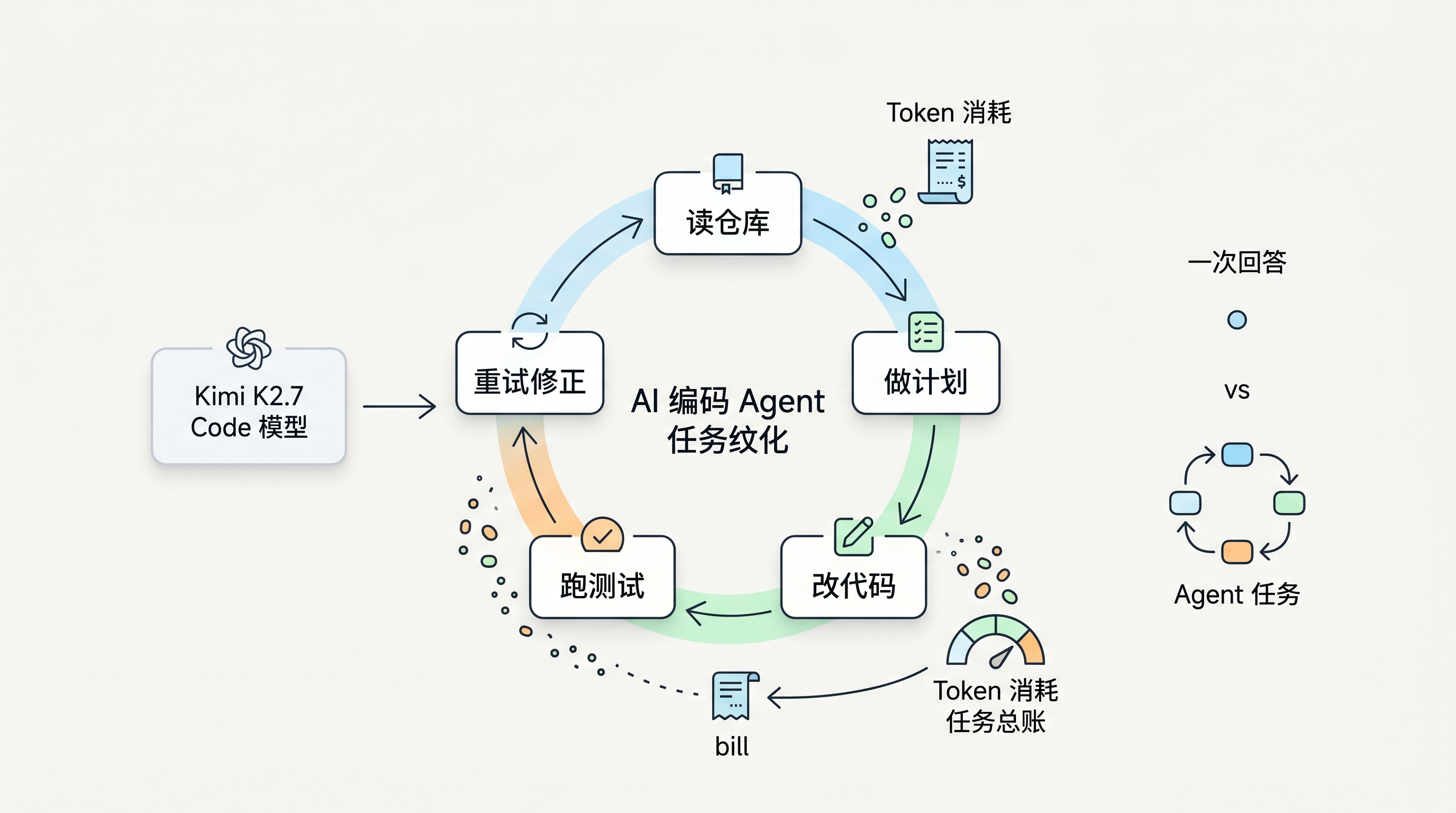
过去聊 AI 编程,大家很容易盯着 benchmark(基准测试)。哪个模型 SWE-bench 更高,哪个模型一次能修更多 bug,哪个模型上下文更长。这些指标当然有用,但它们解释不了全部问题。真实的编程 Agent 不是回答一次就结束,它会读仓库、查依赖、写文件、跑测试、看报错,再回来改第二轮、第三轮。
钱通常就是在这些来回里烧掉的。
Kimi K2.7 Code 这次真正值得看的,是它开始把「模型能不能写代码」往后推了一步,去碰「同一个任务能不能更便宜地跑完」。
编程模型开始进入「值不值得跑」阶段
如果只是让模型补一个函数、解释一段代码,贵一点其实没那么明显。一次调用,多花几分钱,很多人不会专门算。
Agent 场景不一样。
你让它修一个线上 bug,它可能先读十几个文件;你让它迁移一个模块,它会搜索、修改、跑测试、根据失败结果继续改;你让它做一次代码审查,它可能要同时理解 diff、项目规范和历史实现。每一步都要吃 token(词元),每一次走错路都会带来更多上下文和更多重试。
所以「平均 token 消耗减少 30%」这种说法,放在普通聊天模型里只是优化项,放在 Agent 产品里就很敏感。因为 Agent 的成本不是一问一答,而是一串动作的总账。
这也是为什么我觉得 AI 编程正在进入一个新阶段:以前大家问「这个模型会不会写」,现在开始问「这个模型值不值得让它长时间跑」。
这两个问题差别很大。
前者看能力上限,后者看任务总成本。一个模型可以很聪明,但如果每次任务都要读太多、想太久、改太散、重试太多,它就很难变成高频工具。开发者可能会在关键任务上用它,但不会放心让它每天自动跑几十个小任务。
有些步骤,不值得用最贵的思考
AI 公司发布编程模型时,通常会强调更强推理、更长上下文、更好的代码能力。这个方向没错,但在真实工程任务里,不是每一步都需要最高强度的推理。
查找某个配置项,不需要深思熟虑。按既定格式改几个字段,不需要长篇计划。读取测试报错并定位到显眼的拼写错误,也不一定需要最强模型上场。
真正需要模型认真想的,通常是这些地方:为什么这个测试一直失败,改一个模块会不会影响另一个模块,需求里哪些地方互相冲突,某个技术方案后面会不会变成维护债。
这就带来一个很实际的问题:如果一个 Agent 每一步都用同样的「重模式」工作,它看起来很认真,账单也会很认真。
Kimi K2.7 Code 这类更新可以从这个角度理解。模型能力提升是一方面,更关键的是它能不能少走弯路。比如少读无关文件,少生成没有必要的长计划,少在上下文里堆旧信息,少因为工具调用不稳而反复重来。
最后省下来的不只是 API 费用,而是使用频率。
工具便宜到一定程度,用户才会把它从「偶尔用一次」变成「默认让它先跑一遍」。这两个状态,对产品来说完全不是一回事。
价格不变,反而更值得看
选题素材里提到,Kimi K2.7 Code 的价格与 K2.6 持平。这个说法如果属实,比单纯降价更有意思。
降价当然能制造话题,但降价也容易被看成短期竞争。今天你降,明天别人也可以降。价格不变的情况下,如果代码能力、token 消耗、Agent 自主执行能力都有改善,等于是在同一单价下提高了「任务吞吐量」。
个人开发者会感受到的是:同样预算能多跑几轮。工具厂商看到的是:同样订阅价格下,后台能承载更多自动化任务。企业更关心的是:AI 编程能不能从少数高价值场景,下沉到更多重复、琐碎、但确实耗人的工程环节。
国内 AI Coding(AI 编程)生态尤其需要这件事。
Claude Code、Cursor、Codex 已经把开发者教育得差不多了。大家知道 AI 可以读仓库、改代码、跑命令,也知道长任务 Agent 确实能省时间。真正拦在很多团队面前的,往往不是「我不懂这个概念」,而是「它跑起来贵不贵、稳不稳、出了问题好不好收拾」。
如果国产模型能在这些地方持续逼近,它不需要马上全面超过 Claude。只要在一部分场景里做到效果够用、成本可控,就有机会进入日常工作流。
国产编程模型未必要复制 Claude Code
讨论国产编程模型时,很容易把目标说成「做一个中国版 Claude Code」。这当然是一条路,但未必是唯一的路。
Claude Code 强在整套体验:终端入口、文件系统、工具调用、持续执行、权限确认、上下文管理,这些东西组合在一起,才形成了顺滑的工作流。单靠一个模型,很难复制这种体验。
国产模型更现实的切口,可能是先把一批工程任务的单位成本打下来。
很多任务并不性感,但数量很大:代码搜索、依赖梳理、测试失败归类、文档同步、批量重命名、简单迁移、重复性代码审查。它们不一定需要模型每一步都表现得像架构师,但需要便宜、稳定、能并发,最好还能被测试和规则约束住。
在这些场景里,用户不追求一次惊艳的回答。他们关心的是:能不能持续跑,跑错了能不能发现,跑一晚上账单会不会失控。
这也是国产编程模型真正能卷的地方。不是在发布会上证明「我也很强」,而是在真实工作流里证明「我可以承担一部分经常发生的工程劳动」。
Agent 的成本,不只是 API 单价
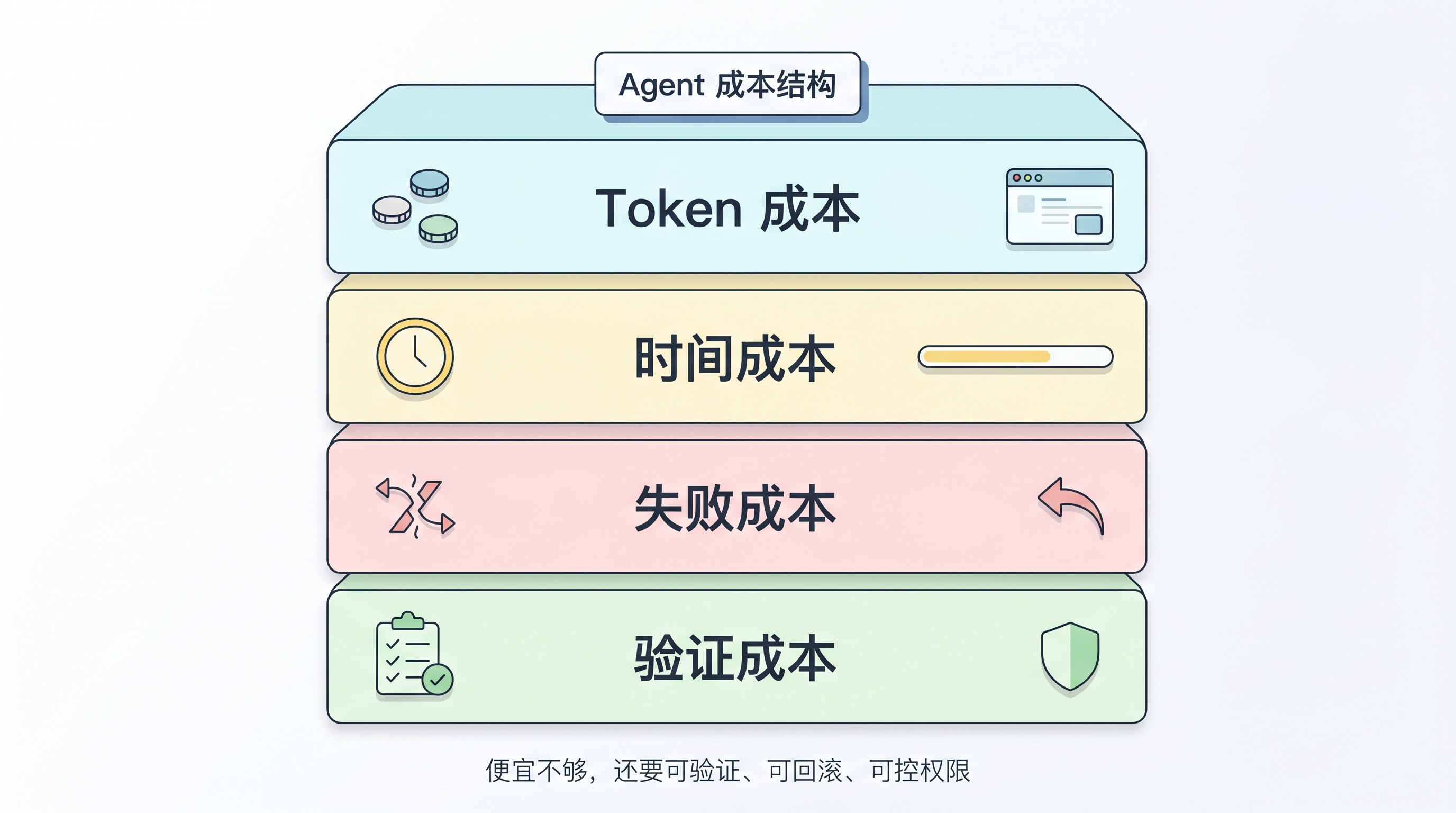
如果把 Agent 的账拆开,它至少有四层。
第一层是 token 成本。上下文越长,输出越啰嗦,重试越多,成本越高。K2.7 Code 里「平均 token 消耗减少」这个指标之所以值得看,就在这里。
第二层是时间成本。模型输出慢,工具调用慢,任务整体就慢。交互式编程里,速度不是锦上添花,它会直接影响用户愿不愿意把任务交给 Agent。
第三层是失败成本。Agent 做错一次,不只是浪费一次调用。它可能改坏代码、污染上下文、引入一堆无关 diff,最后还要人类花时间回滚和检查。长程任务里更稳定,本质上是在减少这种隐性成本。
第四层是验证成本。越自动化,越需要测试、日志、评估器和人工确认兜底。没有验证的低价 Agent,很可能只是把 API 成本转移成维护成本。
所以便宜本身不是答案。真正有用的是,在可验证、可回滚、权限可控的前提下,把单位任务成本降下来。
开发者以后会更像在做模型路由
对个人开发者来说,Kimi K2.7 Code 这类模型短期内未必是「替换谁」。更可能的变化是,多一个可以放进自动化链路里的底层选项。
以后常见的用法可能会更分层:高风险架构判断交给最强模型,重复性工程任务交给成本更低的编程模型,最后用测试、lint、code review 和人工确认兜底。
这会把 AI 编程从「选一个工具」变成「设计一条路由」。同一个 Agent 里,不同步骤可以调用不同模型;同一个团队里,不同任务可以设置不同预算;同一个产品里,也可以按任务风险、上下文长度、用户等级动态切换模型。
国内开发者会更早感受到这件事。只要国产模型的 API、工具调用、上下文能力和 IDE/CLI 生态继续补齐,它很可能先进入内部工具、低风险自动化、私有化部署和中文代码库场景。
它不需要一夜之间替代谁。更现实的路径是,慢慢把一批任务从「必须用最贵模型」变成「用便宜模型也够」。
真正的竞争,会发生在账单里
Kimi K2.7 Code 这次更新,如果按常规新闻写,很容易写成:分数提高了,token 降低了,Agent 能力增强了,API 上线了。
但我更在意的是另一个变化:国产编程模型开始把经济性放到台前。
Agent 负责执行任务,成本结构决定它能执行多少任务。模型提供能力,运行时把能力组织成流程。只要这几件事没有接好,AI 编程就容易停留在演示和尝鲜;一旦接好,它才可能变成团队每天都会用的工程基础设施。
所以 Kimi K2.7 Code 的重点,不是它今天有没有打败某个海外模型,而是它把问题改了一点。
以前大家问:这个模型会不会写代码?
现在更该问:它能不能让 Agent 以足够低、足够稳、足够可控的成本,持续完成工程任务?
如果这个答案慢慢变成可以,国产编程模型卷到的就不只是 benchmark,而是 AI 编程真正的成本底盘。
参考来源
- Kimi K2.7 Code 官方信息:Kimi API 开放平台 与 Kimi K2.7 Code Agent 接入文档。
- 早期评测与接入讨论:Afterfeel AI 的 Kimi K2.7 Code 更新视频、Fahd Mirza 的 Kimi K2.7 Code + Hermes Agent 视频。
- X 传播线索:AI/ML API 关于 Kimi-K2.7-Code 接入的讨论,见
https://x.com/aimlapi/status/2065521473570369837。
以上来源主要用于观察产品发布口径和早期社区反馈。文中关于 Agent 成本结构的分析,是基于这些信息做的产业判断,不等同于对模型能力的独立基准测试。