
前言
目前各大主流浏览器都会自带书签同步功能,无论是 PC 端还是移动端,只要登录一下账号就能轻松访问自己收藏的书签,可以说保存书签的成本越来越低。但是随着收藏内容的增多,使用书签的成本反而会直线上升。
因为最近在少数派上看到了几篇网络书签的相关文章,就也想和大家分享一下目前我自己使用的一套书签方案。因为经常查各种资料,所以收藏的书签很多很杂,数量上应该有几千个,直接导致传统的浏览器收藏夹基本没法用,最后只能选了自建网络书签服务这条路,在用过许多开源方案后选择了 Linkding 和 Trilium 相结合的方案。如果你的书签数量较少,或是不具备自建服务的条件的话,本篇文章可能对你意义不大,大家可以酌情阅读。
因为文章中用到的 Linkding 和 Trilium 都属于自建服务,每个人喜欢的安装方式可能都有差别,网上相关的安装教程多如牛毛,所以我在文中并不会介绍相关内容,而是专注于使用经验方面的分享。当然,安装的话我建议直接根据我下文中给出的官方文档中的步骤进行,以免网上中文教程版本滞后。
传统书签收藏的痛点
查找困难
查找困难是传统浏览器书签收藏系统最大的痛点,究其本质我个人归纳为可用于查找的信息维度过少。少到什么程度呢,你可以试试导出自己浏览器的书签,一般会得到一个 html 文件,以 Edge 浏览器为例,通常一条书签记录会包含如下字段:
| 名称 | 含义 |
| folder | 所在文件夹名称(可多层) |
| href | 书签记录的网址 |
| add_date | 保存书签的时间戳(部分浏览器并不支持书签按时间排序) |
| icon | 书签图标(对搜索而言为无效信息) |
| title | 书签名称 |
看着有五个字段,但实际常被用于搜索的也就两条,文件夹名称和书签名称。从使用的角度来说,三层文件夹应该是普通人能接受的极限了(我自己只能接受一层文件夹)。单单靠少量的文件夹分类的话肯定是不现实的,因为当书签量级上来之后,单个文件夹中的书签数量不可避免地会增加,依旧会面临翻找困难的情况。这时候想要提高查找速度就必定要用到搜索,文件夹层级有限的情况下就只能在书签名称上做文章,较为可行的方法就是在书签名称的最后加关键词,加的越多越详细,后期搜索到的可能性就越高。理论上每次添加书签时都严格按照提前规划好的文件夹层级以及关键词命名规则的话,最后也能得到一份高度可用的收藏夹。
整理困难
但这就引申出其另一个痛点,整理困难。首先第一个困难就是文件夹的分类,事物的联系具有多样性,每一个书签指向的内容都不是非此即彼的,很难归纳出一个所有人通用的文件夹分层结构,最多在你长时间的使用中逐渐妥协为一个相对适合你自己使用的框架。但即便如此,你也总会遇到许多让你纠结其归属的书签,为了方便使用可能某一个书签需要同时在多个文件层级中保存。除了文件夹更需要费脑筋的是书签的命名,直接用默认的网页名称固然方便,但搜索的时候就难免力不从心。
浏览网页的时候看到感兴趣的内容随手点一下地址栏旁的收藏按钮,这应该是很多人使用收藏夹的本能,每次加个书签都深思熟虑其文件夹归属和详尽的关键词命名未免过于严苛,流程繁琐不说,更重要的是可能会打断自己的思路,长时间下来定期整理总是逃不掉的。这时候就不得不品味浏览器收藏夹那简陋的多选和拖拽移动功能了,少量使用体验完美,量大就是折磨了。如果追求高可用性,可能还需要单独修改每个书签的名称,光是想想就够头疼的。
快照
接下来的痛点严格来说算是我个人的痛点,和浏览器中的收藏夹系统本身无关,属于我希望它有但是它没有的功能。首当其冲的就是快照功能,虽然这个功能可以通过安装浏览器插件的形式轻松实现,但是插件保存的快照终究是另外存放的,需要自己手动保存不说,后期想与书签对上还免不了一番折腾,便利性上终究差点意思。
多端同步
最后一个痛点则是多端同步,虽然开篇就说了目前的浏览器都支持多端同步,但是很尴尬的一点就是,我在各个平台上使用的浏览器并不相同,电脑上还好说,直接用 Edge 就行,但是手机、平板之类的移动设备就比较麻烦了,可能会存在多个浏览器混用的情况,这时候依托于浏览器账户的收藏夹同步功能就捉襟见肘了。
网络书签服务:Linkding
Linkding 是目前为止我用下来最好用的开源网络书签服务,基本解决了我上面提到的四个痛点。不过这个服务有几个比较明显的缺点,没法接受的话就不用看下去了。
- 操作界面只有英文。当然,中文书签是支持的,只是设置、按钮等只有英文。我不太清楚有没有大佬封装过中文的镜像,暂时没有查找过。不过其实对使用的影响几乎没有,总共也就那么几个单词,并没有什么太高的门槛。
- 部分服务,类似书签图标等需要使用魔法或是自行配置相关参数。核心功能其实都是服务器本地运行的,不使用魔法体感下来影响不大。
- 默认界面比较朴实,基本就是一堆网页元素的简单堆积。理论上如果你懂 css 的话可以在设置中自定义 css 语句来修改显示效果,想要花里胡哨也是可以实现的。
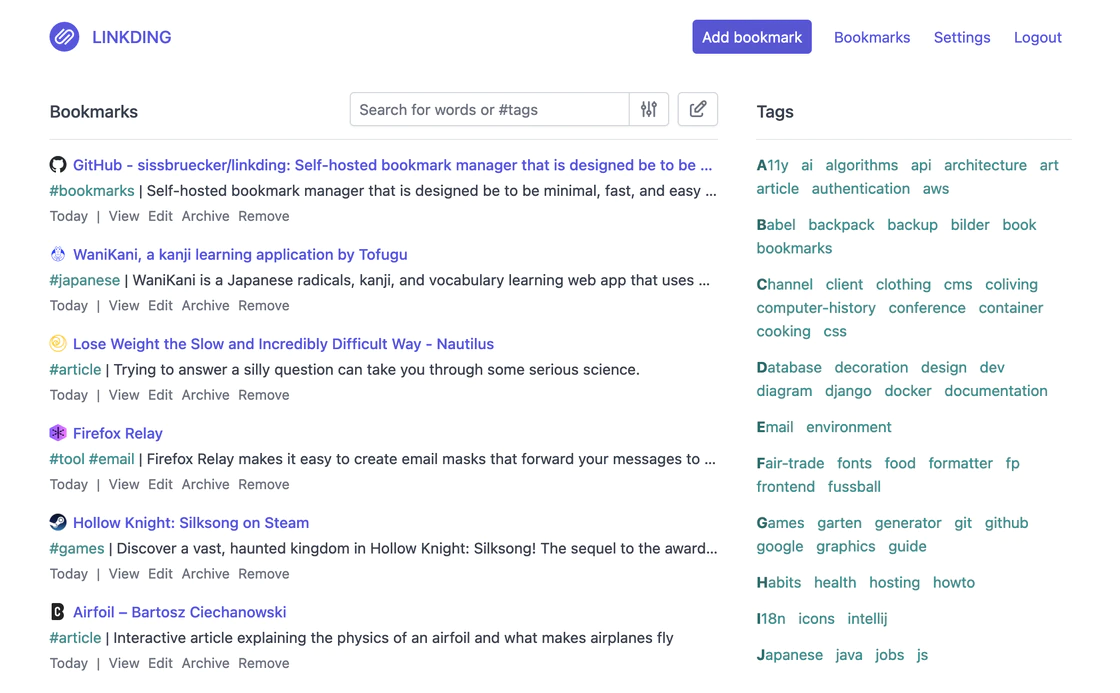
标签系统
概念介绍
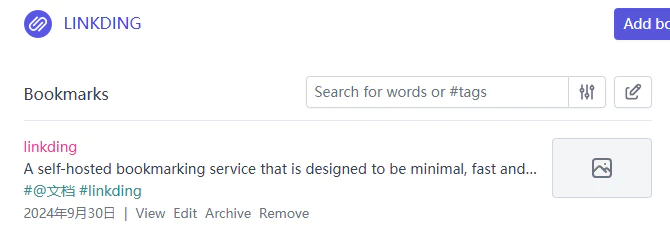
先说一下 Linkding 最核心的标签(Tag)系统,与传统的文件夹系统不同,标签系统更加自由和发散。文件夹系统是线性的,一个书签只能从属于一个文件夹,一个子文件夹只能从属于一个父文件夹;而标签系统则是多对多的关系,一个书签可以同时拥有无数个标签,各个标签之间都是同级的,互相之间没有从属关系。
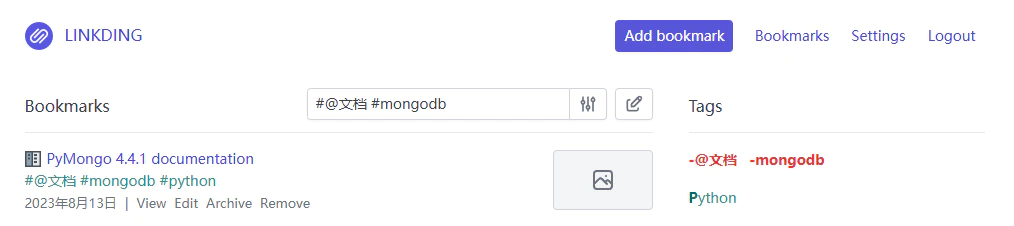
 乍一看好像区别不大,但实际使用时却是天壤之别。举一个简单的例子,假如我需要在书签收藏中找到 PyMongo 的官方文档,那在 Linkding 中只需要先点击「@文档」标签,再点击「mongodb」标签,就能轻松筛选出所有符合的结果。对于经常需要比对同一类型资料,或是「模糊搜索」的用户可谓是神器。
乍一看好像区别不大,但实际使用时却是天壤之别。举一个简单的例子,假如我需要在书签收藏中找到 PyMongo 的官方文档,那在 Linkding 中只需要先点击「@文档」标签,再点击「mongodb」标签,就能轻松筛选出所有符合的结果。对于经常需要比对同一类型资料,或是「模糊搜索」的用户可谓是神器。
使用技巧
之前提到过 Linkding 界面只支持英文,这一点对其标签的排列顺序其实也存在着影响。观察 Tags 这一列就能发现,标签是按照其首字母分行排列的,对于英文标签这样排列非常合理,但是如果使用全中文标签的话就会遇到一个问题,那就是所有中文开头的标签都会被归类到同一行。
这个特性对中文标签来说非常致命,毕竟所有标签挤在一行想要快速找出其中一个的难度就会大大提高。不过解决的方法非常简单,就是根据每个中文标签开头字符的拼音为其添加一个首字母,类似「x 下载」这样的形式。进一步地,我们可以利用其排列特性来实现一些别的需求,比如说对于常用链接可以添加一个「! 常用」的标签,这样该标签就会默认出现在标签区域的第一行。
 标签机制因为其灵活性,刚开始使用的时候可能会有点无所适从,不知从何处入手,收藏的时候可能还会产生一些不必要的纠结,比如这个词要不要设置成标签等。这些其实都是正常情况,我刚开始用的时候也是这样,主要是怕用的久了之后杂乱的标签和之前的文件夹一样难以整理。作为一个长期使用过的用户,我给出两条参考建议:
标签机制因为其灵活性,刚开始使用的时候可能会有点无所适从,不知从何处入手,收藏的时候可能还会产生一些不必要的纠结,比如这个词要不要设置成标签等。这些其实都是正常情况,我刚开始用的时候也是这样,主要是怕用的久了之后杂乱的标签和之前的文件夹一样难以整理。作为一个长期使用过的用户,我给出两条参考建议:
- 每个链接都要分配一个大类,比如可以根据其功能分成「@工具」「@论坛」「@娱乐」等,这些大类不必一次整理清楚,可以想到什么就写什么,不过为了和其他标签形成区分,推荐以「@」开头。当某一天你觉得无论是什么链接都能划分到这些大类之后,就可以开始尝试将它们合并精简,最终将大类个数控制在个位数即可。这些大类标签其实充当着传统书签系统中的一级文件夹的角色,如果你平常就有整理书签文件夹的习惯,可以直接把这些文件夹的名称套用过来。
- 除了大类标签外,每一个链接都尽可能地将所有其涉及的特征点作为标签加上去。加标签的时候不需要有任何的顾虑,所有你脑海中当时跳出来的词汇都可以作为标签加上去,多多益善。你加的标签越多,后续使用的时候找起来就越简单,唯一要注意的是同义词不要重复出现,能复用标签时就尽量不要再创建一个新的类似标签。
书签结构
概念介绍
默认安装参数下,Linkding 的数据库使用的是 SQLite,所以书签数据是以「. Sqlite 3」后缀的文件格式保存的。只要用 SQLiteStudio 之类的软件打开就能查看和修改其中的数据。
我们可以先看一下 Linkding 中书签的所有字段:
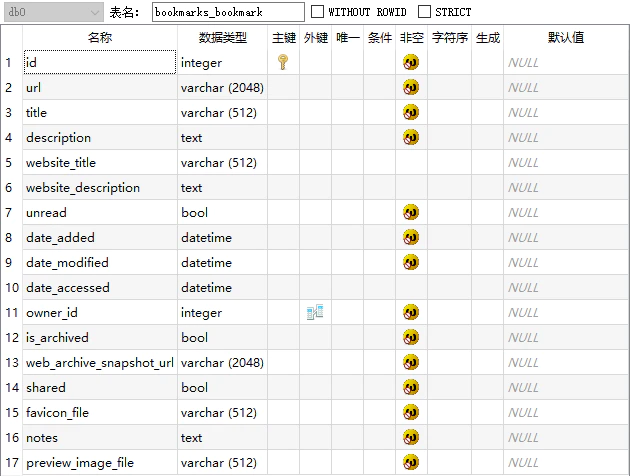
| 名称 | 含义 |
| id | 书签主键 |
| url | 书签记录的网址 |
| title | 书签名称 |
| description | 书签介绍 |
| website_title | 网页默认名称 |
| website_description | 网页默认介绍 |
| unread | 是否标为待阅读 |
| is_archived | 是否标为已归档(即不常用书签或失效书签) |
| web_archive_snapshot_url | Internet Archive 中该网页的快照地址 |
| favicon_file | 图标文件保存地址 |
| notes | 关于该书签的笔记(支持 Markdown 语法) |
| preview_image_file | 预览图片保存地址 |
| tags | 标签与书签的对应关系在一张单独的关系表中,上图中并没有体现 |
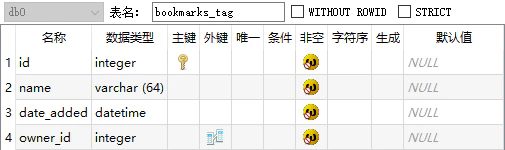
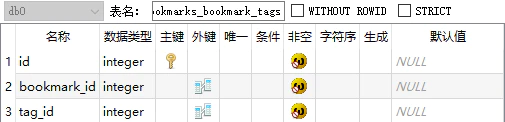
与标签相关的字段比较简单,就一张标签信息表和标签 - 书签多对多关系表。
常用的几个书签属性在使用浏览器插件收藏网页的时候就可以直接编辑。
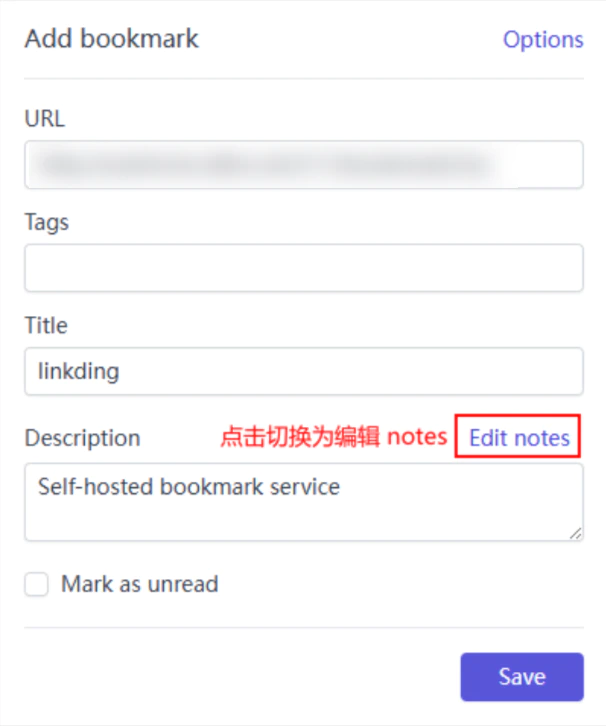
与传统书签系统中可怜的两三个搜索维度相比,Linkding 明显领先太多了,表格中出现的字段内容基本都可以作为搜索元素来进行查找。也就是说,无论是标题、介绍,还是笔记中出现的文本都可以作为关键词来检索,在保持标题简单明了的前提下依旧可以获得远超传统书签的搜索维度。
使用技巧
因为书签的特征不再只有标题这一个维度,所以保存书签时一般不需要修改网页默认的名称,就算要修改也建议将其修改得更加简洁明了。为了便于后续搜索或再阅读,description 以及 notes 需要作为修改的重点。大部分情况下 description 可以使用网页默认描述,要手动编辑的话也尽量用客观的语句描述其实际内容。而 notes 则可以自由一点,并且其本身支持 Markdown 语法,显示效果也会好很多。以我自己为例给大家一些参考,某些知识类的文章可能要点就那么几句话或是几行代码,没什么单独开篇笔记收藏的必要,就可以直接写在 notes 中;找到合适的素材时可以在 notes 中记录下该素材的用法或当时的灵感思路等。总结一下就是三点:
- title:简洁明了,一般保持默认即可。
- description:客观描述网页内容,一般保持默认即可。
- notes:记录网页中的核心知识点、收藏的理由、灵感思路等,一般留空即可。
Unread 和 is_archived 这两个字段很好理解,前者就是很多浏览器自带的待阅读功能,后者则是归档功能,就是把已经失效或是长时间不会再用到的书签隐藏到一个单独的分类中。两者都可以通过首页的 Bookmarks 按钮快速切换,各自都有其独立的分区。
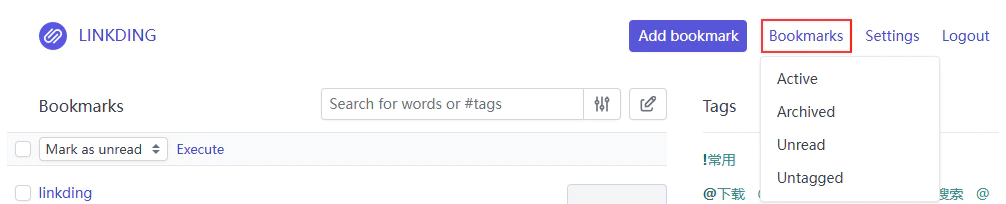 归档这个功能我很喜欢,相较于直接把失效书签删除,把它们关小黑屋总有一种一朝一日它们还能重见天日的错觉。反正也不占什么空间,留着当个念想总是好的。
归档这个功能我很喜欢,相较于直接把失效书签删除,把它们关小黑屋总有一种一朝一日它们还能重见天日的错觉。反正也不占什么空间,留着当个念想总是好的。
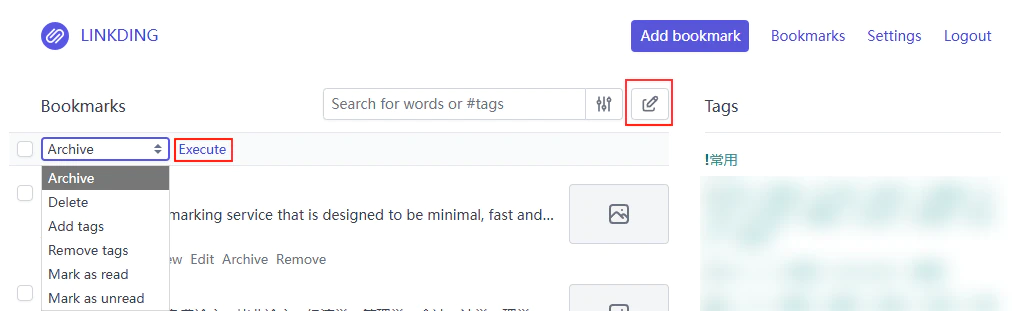
相较于归档,待阅读的花样就多一点。我一般不把它作为待阅读列表使用,而是更接近近期常用的概念,或者说是素材库,把搜索出来也许会用的书签统一标为待阅读。Linkding 的批处理功能是相当优秀的,如下图所示,归档、删除、增加标签、移除标签、标记为已读、标记为未读,这六个核心功能都支持批处理操作,效率远超浏览器收藏夹。
拓展
上面提到过的三张表 bookmarks_bookmark、bookmarks_tag、bookmarks_bookmark_tags 是 Linkding 中最核心的数据表,它们都在 Linkding 数据文件夹的 db. Sqlite 3 这一数据库文件中。因为该文件中数据都是公开的,没有加密一说,操作空间就很大了。
 Linkding 虽然自带导出书签为 html 文件的功能,但是因为其本身并没有文件夹的概念,所以使用其导出的文件导入到 Edge 浏览器就会存在水土不服的情况。我的服务器有一次宕机之后系统出了点问题,但书签每天都要用,就写了个 python 脚本将其按照特定的要求导出为 Edge 可识别的 html 文件应急。具体的导出要求是以「@」开头的标签为文件夹,将所有书签分类放置在其中,同时将每个书签的标签汇总后添加到书签名称的最后。脚本用起来非常简单,与 db. Sqlite 3 文件放置在同一目录下运行即可。
Linkding 虽然自带导出书签为 html 文件的功能,但是因为其本身并没有文件夹的概念,所以使用其导出的文件导入到 Edge 浏览器就会存在水土不服的情况。我的服务器有一次宕机之后系统出了点问题,但书签每天都要用,就写了个 python 脚本将其按照特定的要求导出为 Edge 可识别的 html 文件应急。具体的导出要求是以「@」开头的标签为文件夹,将所有书签分类放置在其中,同时将每个书签的标签汇总后添加到书签名称的最后。脚本用起来非常简单,与 db. Sqlite 3 文件放置在同一目录下运行即可。
这里给出这个案例有多方面的考虑,一是向大家展示一下 Linkding 这种用单个数据库文件存储数据对于个人用户的便利性,因为需要备份的数据就那么几个,甚至以后 Linkding 不再维护,用户依旧可以很轻松地转移到任何其他平台;二是给大家提供另一种 Linkding 的使用思路,可以将其作为单纯的整理工具,使用其强大的批处理界面以及优秀的数据库结构来整理汇总自己的书签,最后导出到更常使用的平台。
|
|
快照
以书签系统为核心的网络书签服务其实有很多,有不少甚至在颜值上吊打 Linkding,但最后还是 Linkding 获得了我的青睐,很关键的一点就是它提供的双重快照系统。
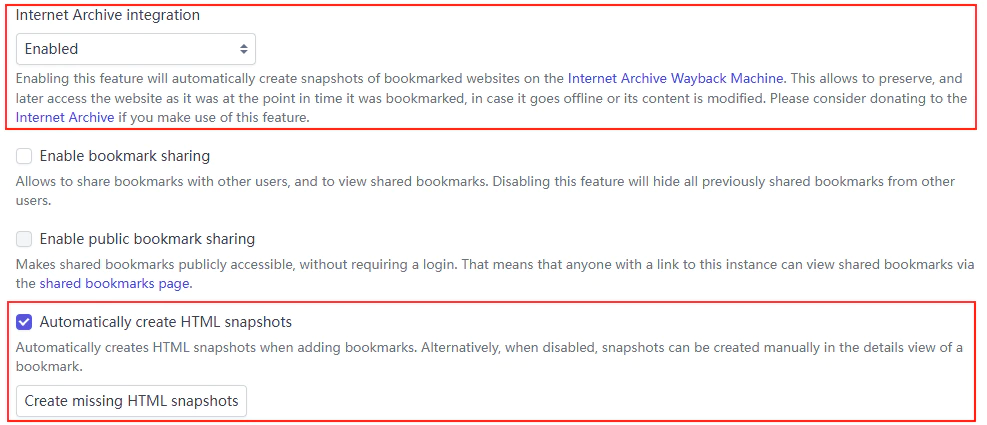 上面那个 Internet Archive 是一个在线服务,开启后服务器会调用该网站的 API 接口将你收藏的网址链接提交上去,然后该网站就会抓取该时刻书签网址上的内容进行保存。Internet Archive 是一个很有名的非营利性数字图书馆,保存着互联网上不计其数的网页内容,有兴趣的可以去了解捐赠一波。
上面那个 Internet Archive 是一个在线服务,开启后服务器会调用该网站的 API 接口将你收藏的网址链接提交上去,然后该网站就会抓取该时刻书签网址上的内容进行保存。Internet Archive 是一个很有名的非营利性数字图书馆,保存着互联网上不计其数的网页内容,有兴趣的可以去了解捐赠一波。
当然,这个快照的局限性非常大,我一般不作为主力使用。首先,想要正常访问 Internet Archive 的话需要使用一点魔法;其次它的抓取对于一些需要登录才能访问相关数据的网站基本没用,就国内互联网这个环境,很多抓取都没有意义。
下面这个快照则是纯正的本地快照,不过该功能只有特定版本的 Docker 镜像才会开启,安装时最好选择 latest-plus 版本。该功能开启后服务器会自动抓取书签的网页内容,和 Internet Archive 类似,需要登录验证的网页同样会抓取失败。
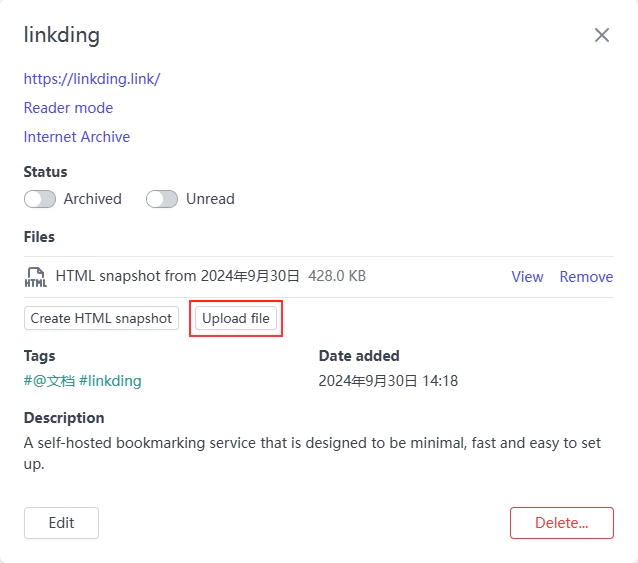
 不过这个是有解决办法的,因为 Linkding 同时提供了手动上传文件作为快照的备选方案。点开书签的详情页,会有一个「Upload file」的按钮,点击即可上传本地文件。这里对于文件的格式没有任何要求,但还是推荐上传可以用浏览器直接打开的 pdf、txt、html 等格式,不然点击浏览按钮后会直接对该文件进行下载。对于文章类的网页推荐直接 Ctrl+P 打印为 pdf 上传,其他网页则推荐使用浏览器插件打包为单个 html 文件后上传。
不过这个是有解决办法的,因为 Linkding 同时提供了手动上传文件作为快照的备选方案。点开书签的详情页,会有一个「Upload file」的按钮,点击即可上传本地文件。这里对于文件的格式没有任何要求,但还是推荐上传可以用浏览器直接打开的 pdf、txt、html 等格式,不然点击浏览按钮后会直接对该文件进行下载。对于文章类的网页推荐直接 Ctrl+P 打印为 pdf 上传,其他网页则推荐使用浏览器插件打包为单个 html 文件后上传。
 对于一些比较重要的文章其实我个人会更加倾向于直接全文收藏到 Trilium 笔记中,算是对网页快照的一个补强,具体内容会在 Trilium 章节中详细介绍。
对于一些比较重要的文章其实我个人会更加倾向于直接全文收藏到 Trilium 笔记中,算是对网页快照的一个补强,具体内容会在 Trilium 章节中详细介绍。
其他
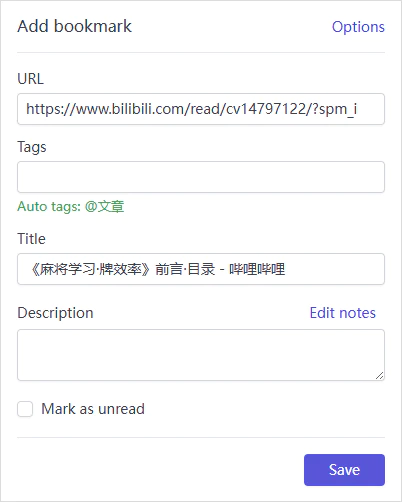
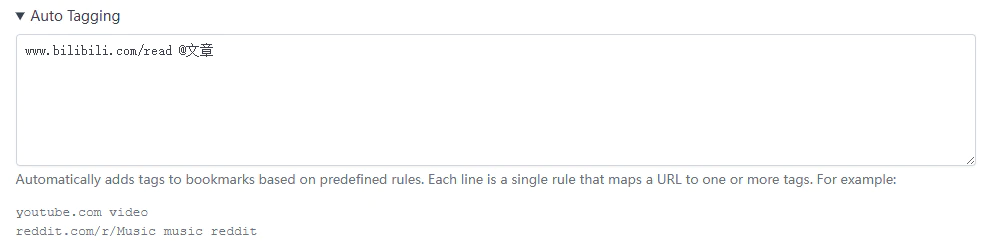
Linkding 设置里面还有两个可能会用到的功能,这里给大家介绍一下。首先是 Auto Tagging,顾名思义,就是可以根据你预设的规则在收藏书签时自动为其加上某些标签,这里以哔哩哔哩的专栏为例。
另一个是 Custom CSS,自定义页面的 CSS,也就是可以更改页面布局。这个需要一点专业知识才能玩转,普通用户可以试着改改字体大小颜色等,比如说把书签颜色改成猛男粉。
最后提一下手机端如何收藏书签的问题,无论是安卓还是 iOS 都有类似 PC 端浏览器插件的实现方式,具体参考官方指南。
个人笔记服务:Trilium
Trilium 是一个可以多端同步的笔记软件。市面上开源的笔记软件其实很多,Trilium 应该算是比较小众的,主要是功能太多,没有耐心很难体会到它的妙处。我其实只能算是它的初级用户,只会一些比较简单的操作,许多高级特性都没有尝试过。Trilium 的功能完全可以单独胜任个人数据库构建的重任,但下文中我只会简单介绍一个与书签相关的特性。
之前介绍过 Linkding 的快照功能,里面说了一些特殊情况下的网页备份方法,但对于图文类的文章我其实很少使用其手动上传功能。主要原因是我个人更加喜欢用 Markdown 的格式来记录图文数据,于知识记录而言,pdf 和 html 终究是不够纯粹和方便。
将网页转化为纯粹的图文数据这一需求曾经困扰过我很久,我尝试过很多不同的开源项目或浏览器插件,结果都不尽如人意,总是会存在一些小问题,直到偶然尝试了一下 Trilium 的浏览器插件这一问题才算是落下帷幕。
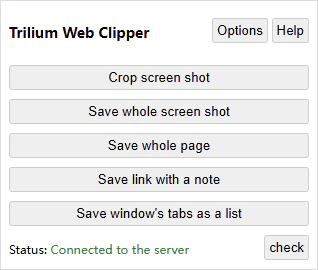 插件上有一个选项是「Save whole page」,可以直接把当前网页上的图文保存为一篇本地笔记,识别率相当高,基本不需要修改就可以得到一篇排版正确的笔记,不过它只会保存文章的主体或是帖子的主楼,也就是说评论和跟帖并不会被保存下来。绝大部分博客类的网站都能完美适配,部分站点可能会存在图片无法显示的问题,不想一张张图片手动复制粘贴的话可以参照 Linkding 快照部分讲解的方法。
插件上有一个选项是「Save whole page」,可以直接把当前网页上的图文保存为一篇本地笔记,识别率相当高,基本不需要修改就可以得到一篇排版正确的笔记,不过它只会保存文章的主体或是帖子的主楼,也就是说评论和跟帖并不会被保存下来。绝大部分博客类的网站都能完美适配,部分站点可能会存在图片无法显示的问题,不想一张张图片手动复制粘贴的话可以参照 Linkding 快照部分讲解的方法。
这项功能完美补全了 Linkding 在待阅读方面的短板。我目前对于一篇有价值的网页文章的基本操作流程就是先用 Linkding 的浏览器插件保存书签,然后使用 Trilium 的浏览器插件保存图文到笔记系统。保存书签是为了方便后续深入阅读时可以随时查看有价值的评论或跟帖,保存图文则是将其作为待阅读的素材,后续阅读时可以很方便的删改整理为自己的笔记。
插件上另一个常用的选项是「Save windows’ tabs as a list」,可以将当前浏览器窗口中所有 Tab 页的网页链接以列表的形式保存到笔记中,设计这个功能的人绝对是懂工作的,后续想要回到同样的工作场景只需要打开对应笔记点击列表中的链接就能完美复原浏览器状态。
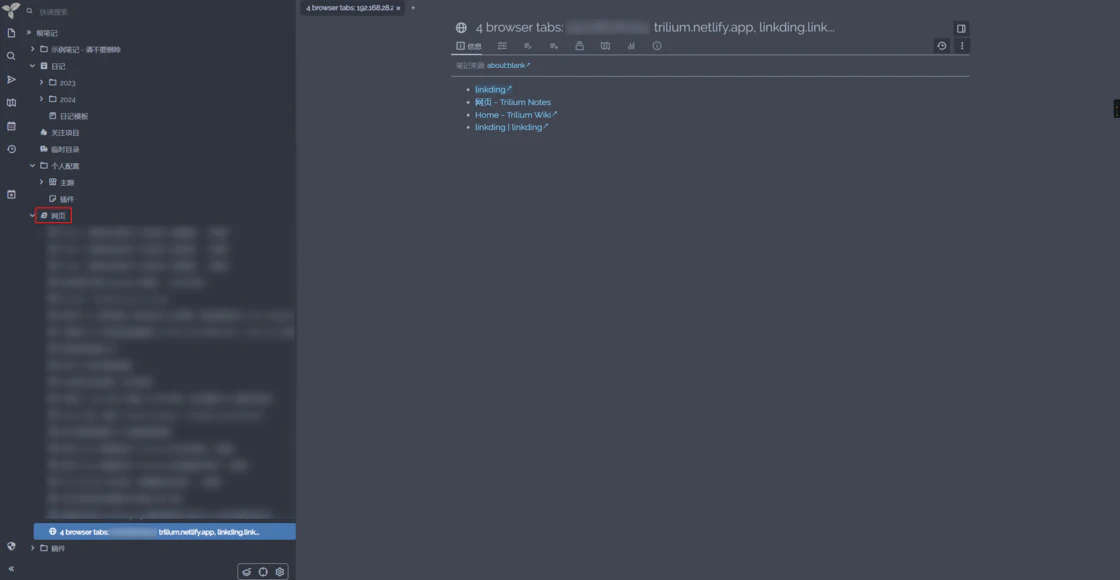 这可以算是一个额外的专项任务收藏夹,可以将一些日常工作场景下会打开的链接提前收藏好,需要用到时就能快速开始该场景下的工作,结合上文中我提到过的使用 Linkding 的 unread 列表来作为近期任务工作区,可以极大的提高工作效率。
这可以算是一个额外的专项任务收藏夹,可以将一些日常工作场景下会打开的链接提前收藏好,需要用到时就能快速开始该场景下的工作,结合上文中我提到过的使用 Linkding 的 unread 列表来作为近期任务工作区,可以极大的提高工作效率。
后记
Linkding 和 Trilium 这种本地服务最重要的就是保证数据安全,如果想要使用我的这套方案请务必设置好服务器数据的定期备份,数据一旦丢失,想要再次补全的代价实在过于高昂,请务必慎重。