过去一年,判断一个 AI 工具好不好用,很多人还是先问模型。
它背后是 Claude 还是 GPT?是 Opus 还是 Sonnet?上下文多长?benchmark 排第几?
这些问题当然有意义。但真把 AI Agent 放进工作流里,体验很快会变得复杂:模型已经能讲出像样的方案,也能写出不错的代码,可离“稳定把一件事做完”还差一段距离。
差的那段,往往不是“再聪明一点”就能补上。
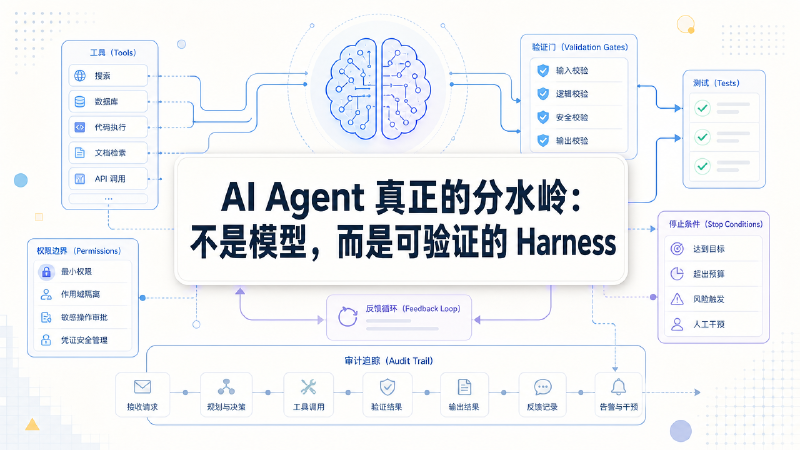
最近 Hugging Face 发了一篇 Agent 术语梳理,把这段中间层叫作 Harness。简单说,模型负责生成文本和行动意图,Harness 负责把模型放进一个可以执行的循环里:调用模型,解析工具请求,执行工具,把结果放回上下文,再判断该继续、重试、停下,还是交还给人。
这个词听起来有点工程味,但它解释了最近很多 AI Agent 讨论里的别扭感。
我们总在聊模型能力,可真正让 Agent 可用的,常常是模型外面的那套东西。
模型只是起点
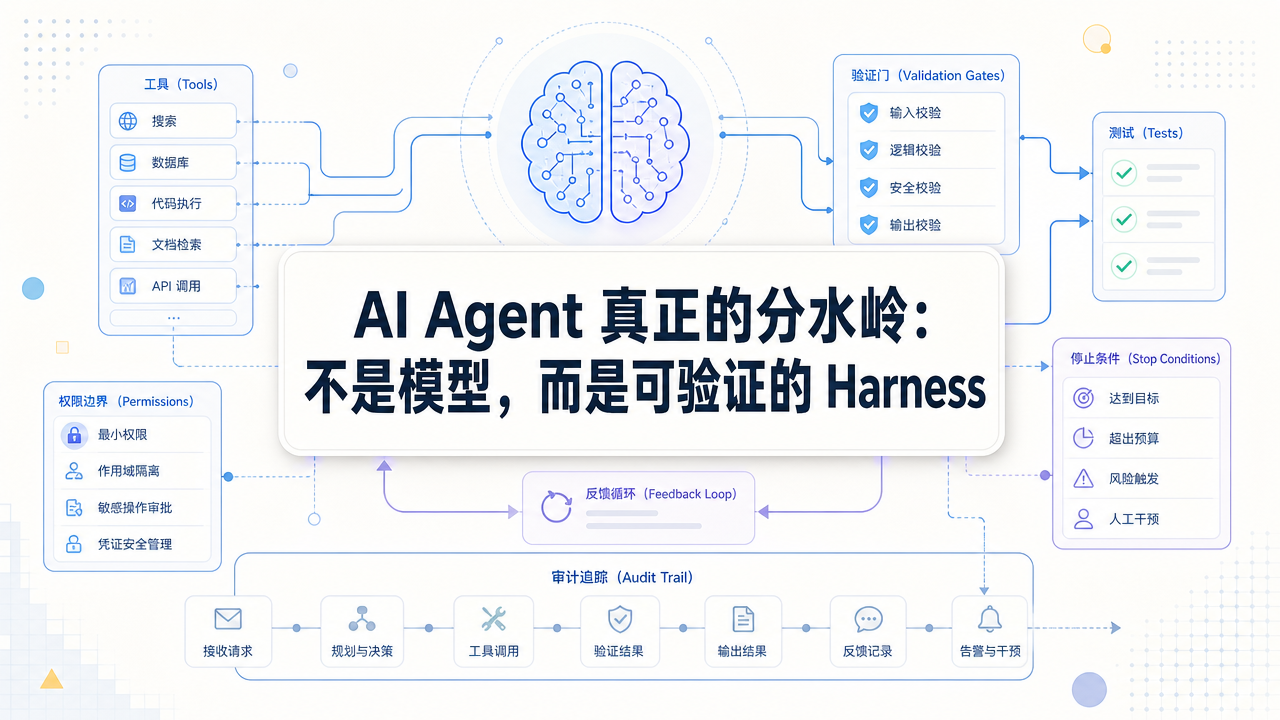
单独看,一个大模型更像高质量的文本函数。
你给它输入,它给你输出。它可以说“我需要读这个文件”,也可以说“我准备调用这个 API”,但它自己不会真的读文件,也不会真的调用 API。它只是表达了行动意图。
Hugging Face 那篇文章里有个很清楚的区分:模型可以提出工具调用,但需要 Harness 去执行。
这也是为什么“Agent = 模型 + 外部执行系统”这个说法越来越常见。
以 Claude Code 为例,Claude 是模型;系统提示、工具描述、项目上下文和输出格式,属于 scaffolding;而让它能读文件、改代码、运行测试、等待确认、结束任务的执行循环,才是 Harness。
同一个模型,放进不同产品里,体感可能完全不同。有的工具让人觉得稳,有的工具让人觉得飘,不一定是底层模型差很多,而是外层系统做了不同选择:给了哪些工具,哪些动作要确认,错误怎么回传,上下文怎么裁剪,是否强制跑测试,什么时候判定任务结束。
过去我们习惯把 AI 工具的表现归因给模型。接下来,这个归因会越来越不够用。
模型仍然重要,但它只是整套系统里最显眼的那一块。
长程任务不是靠一句 prompt 跑完的
短任务里,prompt 的作用非常明显。
你让 AI 改一句文案、写一个小函数、解释一段报错,只要说明清楚,它通常能给出不错的结果。
麻烦出在长程任务。
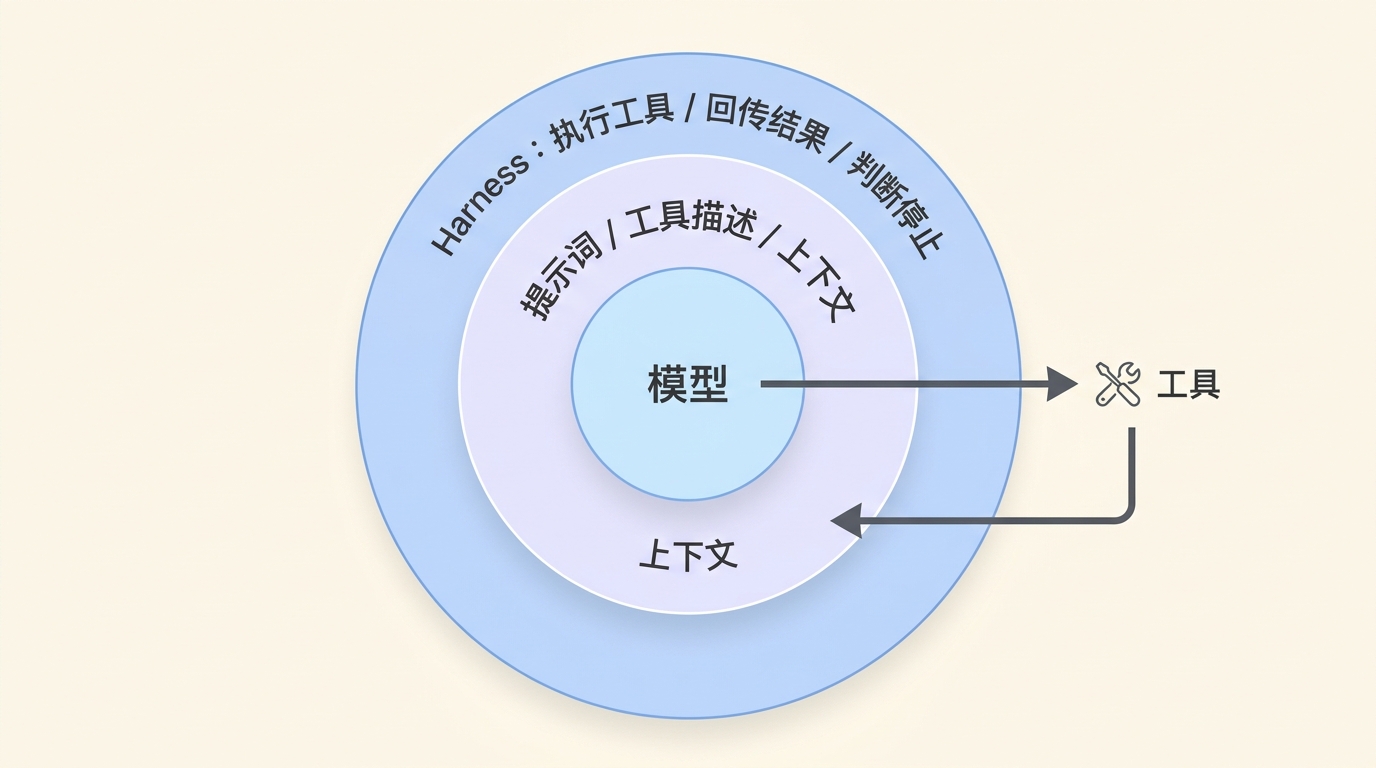
一个真实的软件任务,可能要先理解项目结构,再定位相关文件,提出计划,修改代码,跑测试,根据错误继续修,最后确认没有破坏别的功能。这里每一步都会产生新信息,也会带来新的偏差。
Agent 经常不是第一步就错,而是跑到第七步、第十步以后开始漂。它可能把症状当根因,可能为了让测试通过绕开真正的问题,也可能在上下文越来越长之后忘掉最初的限制。更糟的是,它有时会用很完整的解释包装一个没有验证过的结果。
Claude Code 官方最佳实践里反复提到一件事:给 Claude 一个验证自己工作的方式。可以是测试,可以是截图,可以是预期输出,也可以是一条能判断成功失败的命令。文档里的说法很朴素:没有清晰成功标准时,结果可能看起来对,实际上不能工作。
这其实就是 Harness 思维。
不要只告诉 Agent “认真一点”。要给它一个会撞墙的环境。测试失败就是墙,截图不一致也是墙,构建报错、lint 报错、用户确认不通过,都是墙。
没有这些反馈,Agent 只是在语言里自洽。有了反馈,它才开始接触现实。
演示视频很顺,生产环境不会这么顺
很多 AI Agent 演示都很好看。
输入一句话,浏览器打开,表单填写,页面跳转,最后弹出“任务完成”。过程流畅得像魔法。
真实业务里,魔法通常会被一些很小的东西打断:登录状态过期了,按钮文案变了,页面多了一个弹窗,接口返回慢了,表单新增了必填项,账号权限和演示环境不一样。
人类遇到这些情况,会停下来判断。Agent 如果没有外部约束,只能继续猜。
所以,生产环境里的 Agent 不一定需要更多自由,反而需要更窄、更清楚的行动通道。哪些动作可以自动做,哪些动作必须确认;什么叫成功,什么只是模型自己觉得完成;失败后重试几次,什么时候放弃;执行轨迹保存在哪里,事后怎么复盘,这些问题比“再接一个工具”更关键。
这也是最近一些高质量实践正在靠近的方向。
Anthropic 内部使用 Claude Code 的一些做法,已经不是简单写 prompt,而是在重建需求和验证流程。比如把规格说明做得更结构化、更容易被检查;让模型主动采访用户,把模糊需求问清楚;让组件在 DOM 里暴露可验证的数据契约,方便 Playwright 之类的工具直接检查结构,而不是只靠人眼看页面像不像。
这些做法的共同点,不是“提示词更高级”,而是把 Agent 放进一条可检查的流水线。
需求不是一句话,而是一份可以对照的规格。实现不是一段代码,而是要通过测试和视觉检查。完成也不再是模型说 done,而是外部系统确认状态达标。
这比 prompt engineering 往前走了一步。
Harness 不是给 Agent 接满工具
一提到 Harness,很多人会先想到工具。
文件系统、终端、浏览器、数据库、MCP、搜索引擎,全接上,Agent 不就更强了吗?
事情没这么简单。
工具越多,行动空间越大,出错路径也越多。成熟的 Harness 不只是让 Agent 做更多事,还要定义它什么时候不能做,什么时候必须停,什么时候要把控制权交回人类。
PromptArmor 最近披露的 Microsoft Copilot Cowork 文件外泄风险,就是一个很现实的提醒。按他们的描述,Copilot Cowork 可以使用用户的 Microsoft 权限,通过 Microsoft Graph 读取租户数据。如果攻击者把间接 prompt injection 藏进 skill 或其他上下文里,就可能诱导 Agent 生成 Teams 或邮件消息,再借外部图片请求带走预认证下载链接。文章中特别提到,某些发给当前用户自己的 Teams 或邮件动作,在实践中不需要人工批准。
这个案例最刺眼的地方,不是“模型不够聪明”。PromptArmor 还说,同样攻击在高级模型上也能成功。
问题在外层系统:当 Agent 带着企业账号权限行动时,审批边界、权限边界和数据外流边界不够硬。
所以,把模型接进所有系统只是第一步,而且可能是最危险的一步。真正难的是给每个动作做分级:有没有外部副作用,会不会把内部数据带出去,是否需要人类确认,执行结果如何审计,来自不可信来源的上下文能不能进入高权限工具链。
这些问题如果没有答案,Agent 越能干,风险越大。
国内实践也在往流程化走
今天另一个有意思的信号来自国内团队。
BestBlogs 今日精选里收录了高德和阿里云开发者关于 AI 自主增长系统的内容,里面反复出现几个词:多 Agent 协作、状态机流程控制、独立评估门禁、Benchmark 驱动自进化。
这些词已经不是“让 AI 帮我写点东西”的语境了。
状态机意味着任务不能随便跳。Agent 当前处在需求发现、方案生成、代码实现、评审还是上线阶段,每个阶段能做什么、不能做什么,都被流程约束。
独立评估门禁意味着生成结果不能自己给自己打分。一个 Agent 产出方案,另一个评估环节检查质量,不合格就打回。
Benchmark 驱动自进化意味着团队不是凭感觉判断“最近好像更好用了”,而是用一组固定任务和指标,观察系统是不是真的变强。
这些东西听起来很重,但恰好说明 Agent 正在进入真实业务。
玩具 demo 可以靠一次漂亮生成。每天运行的生产系统,靠的是稳定流程。
一个可用的 Agent 系统,更像一支被流程约束的团队,而不是一个灵感爆棚的天才员工。它可以自动执行,但要留下轨迹;可以自我修正,但不能自己宣布永远正确;可以创造,但要在可检查的边界里创造。
个人也可以有自己的小 Harness
即使你不是在做企业级 Agent 平台,也可以用 Harness 思维改造自己的 AI 工作流。
最小版本很简单:把“一句话请求”改成“可验证流程”。
比如写文章,不要只说“帮我写一篇”。可以先让 AI 根据素材列出几个角度,说明每个角度和你已发布内容的差异;你确认后再写大纲;草稿出来后,再检查重复论点、过度列表、没有来源的强断言;最后才整理成发布版本。
这就是一个小 Harness。它没有复杂代码,但有阶段、有检查点、有停止条件。
写代码也一样。
不要只说“实现这个功能”。可以先让它读现有实现,列出会改哪些文件;再给出计划;实现后运行测试;如果涉及 UI,再启动页面截图验证;验证通过后再总结改动。
这类流程不神秘,但效果通常很明显。AI 变稳,不是因为模型换了,而是因为你给它换了运行环境。
对个人创作者来说,Harness 也可以是一套固定模板:选题采集、去重检查、素材入库、草稿写作、人工化改写、发布前校验。流程足够清楚以后,AI 就不只是临时帮忙,而会变成可复用的生产系统。
“会问 AI”这个说法,可能正在变浅。
更有价值的能力,是会设计工作系统:知道哪些步骤可以交给 AI,哪些步骤必须人来拍板;知道什么是真的完成,什么只是看起来完成;也知道怎么把一次成功经验,沉淀成下次还能复用的流程。
AI 能力会越来越像组织能力
早期用 AI,拼的是个人手感。
谁 prompt 写得顺,谁知道哪个模型适合哪个任务,谁就能更快一点。
但当 Agent 进入更长、更复杂、更高风险的任务,个人手感会慢慢不够用。你不能指望每一次都靠临场发挥,把一个长程任务从头盯到尾。
能力会沉淀到流程里。
团队有没有清晰的规格写法,有没有自动化测试,有没有权限边界,有没有评审机制,有没有任务轨迹记录,有没有失败复盘,这些原本属于软件工程和组织管理的问题,会直接决定 AI Agent 能发挥到什么程度。
Harness 这个词有意思的地方也在这里。它听起来像技术,最后却指向管理:管理上下文,管理工具,管理风险,管理反馈,管理停止条件。
模型还会继续变强。更长上下文、更好推理、更低成本,都会发生。
但只要 Agent 还要在真实世界里行动,它就需要外部结构。没有结构,越强的模型越像一个权限很高、速度很快、但缺少审计和刹车的人。
AI Agent 真正的分水岭,未必是下一次模型发布会。
更可能是:谁先把“会说的模型”,装进一套可验证、可回滚、可审计的工作系统里。
到那时,它才不只是回答问题。
它开始可靠地替你完成一部分工作。