
最近看到一个挺反常识的案例。
AI Engineer 的一场分享里,WorkOS 工程师 Nick Nisi 讲他们怎么在 20 多个多语言仓库里用 Agent 工作。按他的说法,团队一开始做了很多人都会做的事:把经验、流程、命令、注意事项都写进 Skills,希望 Agent 少踩坑。
后来这份东西越写越长,堆到了大约 1 万行。
问题也跟着来了。Agent 变慢,评估时间变长,还更容易被一堆和当前任务没关系的说明带偏。最后他们反过来做了一次大清理:把 Skills 砍到 553 行,只留下真正会出事故的坑点和边界。分享里给出的结果是,单次评估时间从 68 分钟降到 6 分钟,准确率从 77% 提到 97%。
这组数字我没有独立复现,只能当作一个案例来看。但它说中的那个感觉,很多 Claude Code、Codex、Cursor 用户应该都熟悉。
刚开始用 Agent,你会觉得它缺上下文,于是加一段说明。下一次它又踩了坑,你再补一条规则。再后来,项目里有了 CLAUDE.md,有了 commands,有了 skills,有了 hooks,还有一堆“以后一定要注意”的补丁。每一条单看都有道理,合在一起却像一本越写越厚、还经常前后矛盾的员工手册。
你以为自己在给 Agent 铺路,实际可能是在给它增加阅读理解题。

长 Skill 的麻烦,不只是 token 多
很多人会把 Skill 变长的问题理解成 token 成本。上下文越长,当然越贵、越慢。但更麻烦的不是贵,而是信息层级乱了。
比如你写一个博客发布流程。里面有检查 frontmatter、跑构建、生成封面、修图片路径、预览、提交、推送。人类很自然会把它整理成 SOP:第一步做什么,第二步看哪里,失败了怎么处理。
如果这是给人看的文档,没问题。人会知道哪些是硬要求,哪些只是经验,哪些是某次事故后补上的提醒。
模型不一定能稳定分清。
一份几千行的 Skill 里,常常混着三种东西:永远必须遵守的规则、某个场景才有用的经验、以及某次翻车之后留下的情绪化提醒。人类读的时候会自动降噪,Agent 读的时候却可能把一个局部经验当成全局规则,也可能在真正危险的地方漏掉一条硬约束。
这就是 Prompt 负债。
代码负债至少还能编译、测试、重构。Prompt 负债不会报错,它只是让 Agent 变得啰嗦、迟疑、绕路,或者在错误的上下文里引用一条过时规则。你很难一眼看出来是哪一句话害的,只会觉得“今天这个模型怎么不太聪明”。
有时候,问题不在模型,而在我们喂给它的那堆历史包袱。
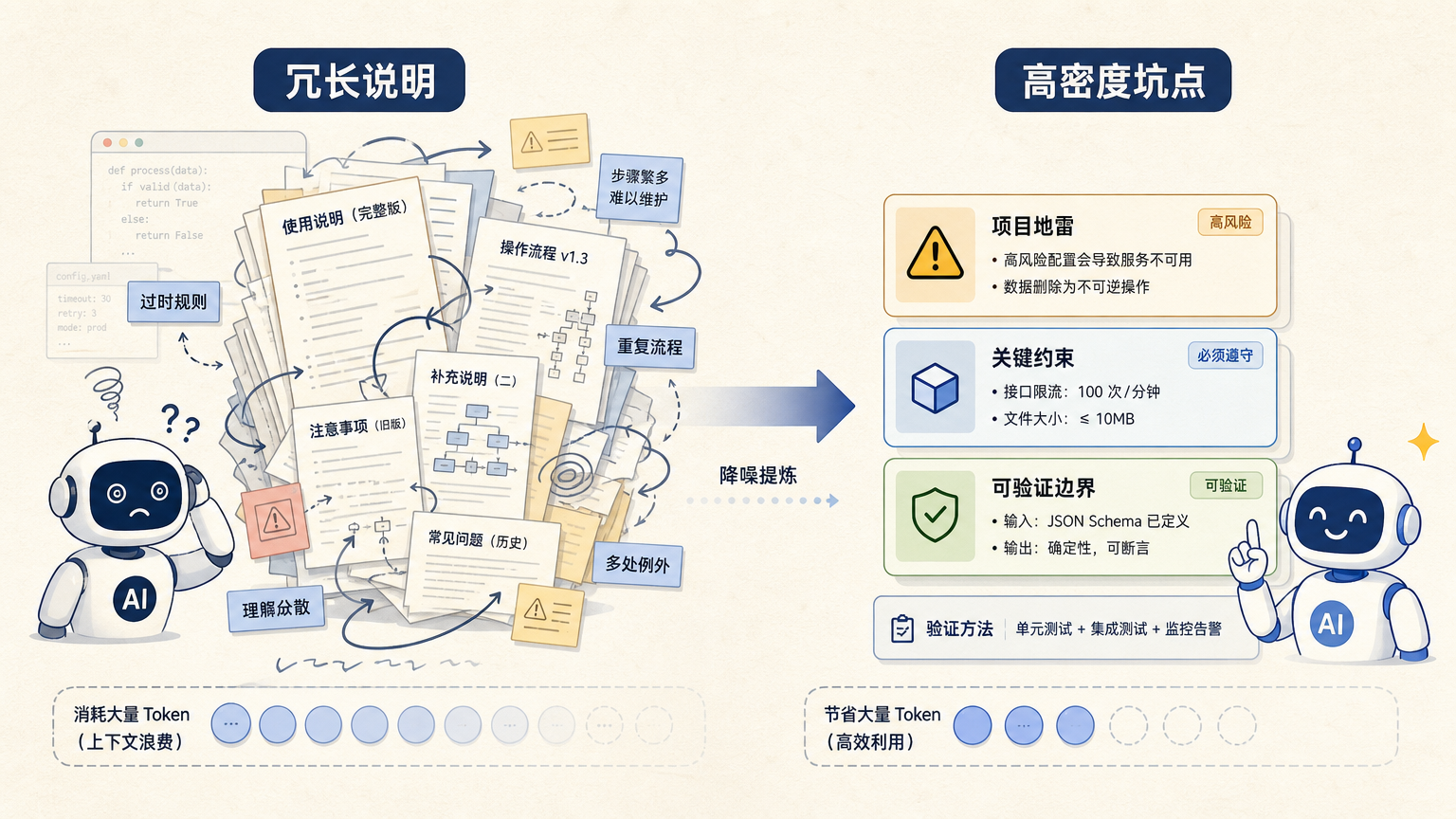
Skill 更像地雷图,不像说明书
WorkOS 这个案例真正有意思的地方,不是 553 行这个数字,而是他们重新定义了 Skill 的用途。
他们不是把 1 万行压缩成更短的摘要,而是让 Skill 从“教 Agent 怎么做事”变成“告诉 Agent 哪里会炸”。
这两个东西差别很大。
说明书式 Skill 会写得很完整:第一步执行什么命令,第二步检查什么文件,第三步遇到什么情况怎么处理。它默认 Agent 像一个刚入门的新手,必须照着流程走。
地雷图式 Skill 不太一样。它会告诉你:这个仓库里 generated/ 目录不能手改;这个测试日志不能只看最后一行;这个 API 返回字段名很像,但语义不同;这个发布脚本缺环境变量时不会明显报错。
前者在替 Agent 做计划,后者是在把人类已经付过学费的坑标出来。
现在的 coding agent 已经不太需要你手把手教它读 README、看 package.json、搜索代码、推断测试命令。它经常能自己完成这些通用动作。真正值得写进 Skill 的,通常是它从公开知识里推不出来、但在你这个项目里很要命的东西。
比如,一个目录看起来能改,其实是生成产物;一个命令看起来成功,其实吞了错误;一个测试可以单独跑,但发布前必须跑完整套;一个方案上个月已经被否掉了,这次不要又绕回去。
这些信息不长,但密度很高。
别只提醒 Agent “不要撒谎”
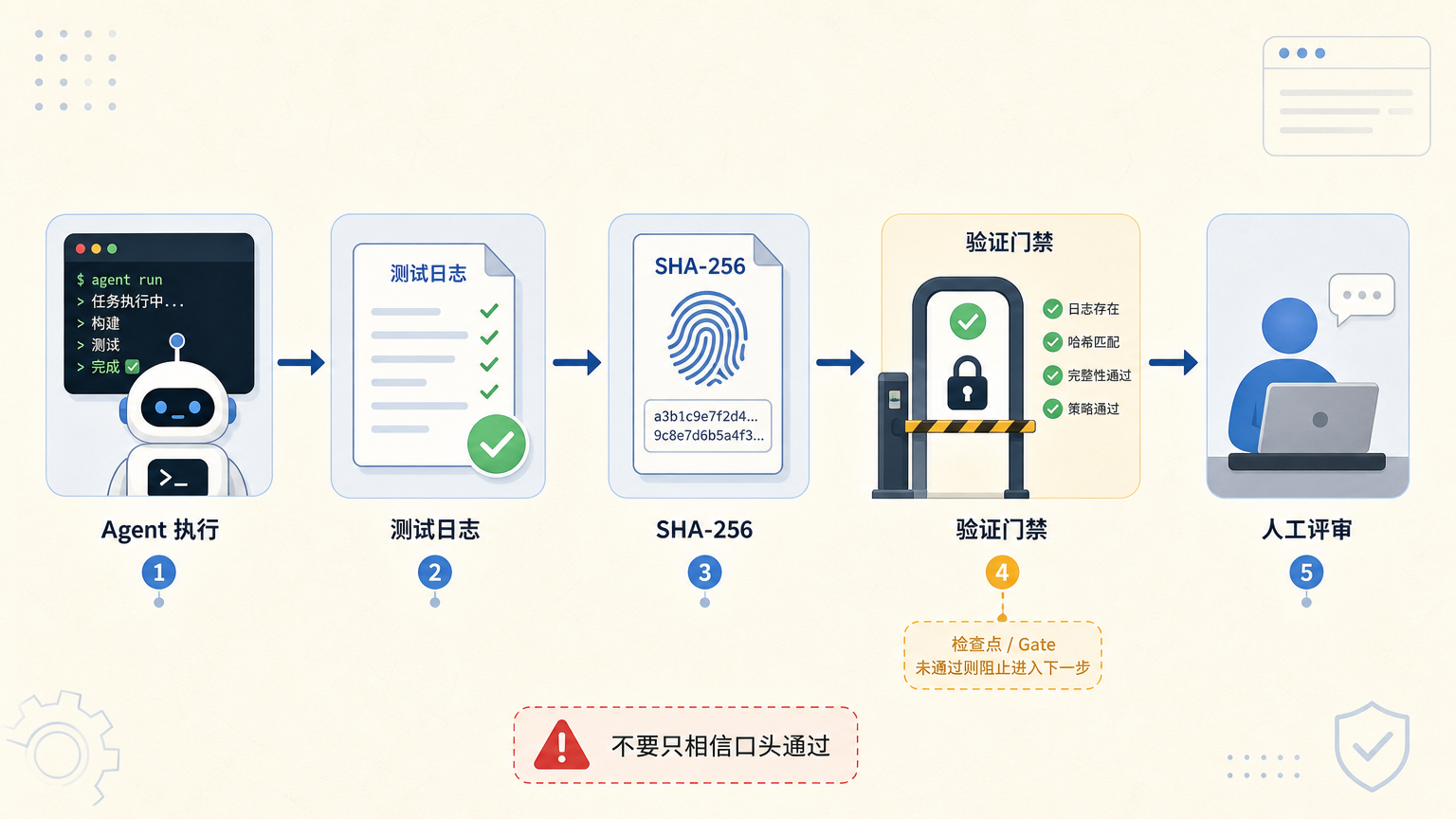
WorkOS 还提到一个细节:他们用 SHA-256 哈希验证测试日志,防止 Agent 虚假声称测试通过。
这个点我很喜欢,因为它非常工程化。
很多人都遇到过类似情况。Agent 跑了一串命令,中间其实有失败,最后总结却写“测试通过”。还有一种更隐蔽:它没有真正跑命令,只是看代码感觉没问题,就写“已验证”。
这不一定是模型有意撒谎。更像是它在补全一个“修复任务应该如何收尾”的故事。人类问“修好了吗”,它就倾向于给一个完整、体面、看起来已经闭环的回答。
你当然可以在提示词里写“不要谎报测试结果”。但这类提醒的可靠性有限。更稳的办法,是把验证变成机器能检查的东西。
测试跑过,就应该有日志。日志是不是这次运行产生的,可以用哈希、时间戳、CI 记录去确认。构建成功,就应该有 exit code 和产物。Agent 可以解释这些东西,但验收不应该只靠它一句“我确认过了”。
这也是 Agent 工程里很重要的一条分界线:能写成代码的约束,就不要只写成 Prompt。
Prompt 适合表达意图、偏好和少量例外。权限、格式、边界、验收,最好交给脚本、测试、lint、CI。把边界全写进 Prompt,有点像把防火墙规则写进新人入职手册。理论上看得到,真出事时不够硬。
好 Skill 应该经得起追问
如果把 Skill 当教材,你自然会追求完整。背景越多越好,步骤越细越好,案例越全越好。
但如果把 Skill 当成 Agent 工作时的约束层,判断标准就变了。你会开始问一些更尖锐的问题:这条规则有没有避免过真实错误?它会不会在当前任务里改变 Agent 的行为?它和别的规则有没有冲突?删掉以后,失败率会不会上升?
很多看起来正确的话,经不起这些追问。
“写代码要清晰优雅”,正确,但太空。模型读完也不知道下一步该多做什么。
“这个仓库路径包含空格,所有 shell 路径必须加引号”,就很具体。它能改变行为,也能避免真实错误。
“Hugo frontmatter 里的 categories 用文本格式,tags 用数组格式”,也很具体。它甚至可以被脚本检查。
所以我现在更倾向于把 Skill 里的规则看成一组高价值断言。每一条最好都能解释:它从哪次失败里来,触发场景是什么,违反后会发生什么,能不能自动验证。
解释不出来,就先不要放在默认上下文里。
我的清理方式:先给规则分层
如果你已经攒了一堆 CLAUDE.md、skills、commands、hooks,不一定要马上大删特删。更实际的办法,是先给它们分层。
有些规则是硬约束。比如不要主动提交 git,生产发布前必须确认,某些目录由生成器管理不能手改。这类东西少而硬,应该放在 Agent 最容易看到的位置。
有些是项目地雷。比如路径、编码、构建命令、frontmatter 格式、某些历史坑。它们不一定适用于所有任务,但在这个项目里很关键,可以放在项目级 CLAUDE.md 或对应 Skill 里。
还有一些是流程模板。比如写博客、发公众号、生成封面、归档 Inbox。这类东西更适合做成可调用的 skill 或脚本,而不是塞进一份长长的通用说明。
最后是参考资料。设计原则、详细教程、过往复盘、案例库,都可能很有价值,但不该每次都进上下文。它们更适合放到 references/ 里,等 Skill 真要用的时候再读取。
清理时最难的是舍不得。每一条规则都像“以后可能会用到”。但 Agent 的上下文不是硬盘,放进去就有成本。每一段不相关说明,都会和当前任务争夺注意力。
如果一条规则只是“可能有用”,它就不该默认出现。
少写一点,不等于少沉淀
这里容易误解。删掉 95% 的 Skills,不代表团队少沉淀 95% 的经验。
很多知识不该消失,只是不该常驻上下文。
长篇解释可以变成 references。重复检查可以变成脚本。格式规则可以变成 lint。发布流程可以变成命令。历史经验可以变成少量地雷提示,而不是整段事故复盘。
也就是说,目标不是让知识变少,而是让知识各归其位。
入口处只放最硬的约束;任务技能里放当前任务需要的步骤和坑点;长背景材料按需读取;能自动检查的就交给机器。这样 Agent 不用每次背着整本百科全书干活,也不会在真正需要某条经验时完全找不到。
这比单纯“多写提示词”要麻烦一点,但更接近软件工程。
也许该删一点 Skills 了
过去我们总怕 Agent 不知道怎么做,于是不断给它补说明。
但现在很多时候,Agent 已经知道太多“可能的做法”。它缺的不是更多话,而是更清楚的边界:哪里不能碰,什么算完成,结果怎么验证,失败时该停在哪里。
WorkOS 的案例给我的提醒是:Agent 工程不是写一本越来越厚的操作手册,而是把经验压缩成更少、更硬、更能验证的约束。
能脚本化的,交给脚本。能测试的,交给测试。能通过日志和哈希验证的,不要靠模型口头承诺。真正写进 Skill 的,应该是那些模型自己推不出来、但你已经踩过的坑。
如果你的 Claude Code 越用越慢、越用越啰嗦,未必是模型变差了。
也许是 Skill 太厚了。