说明:这篇文章基于 Reddit r/ClaudeAI 里一条关于 “Reviewing AI-generated pull requests in 2026” 的社区讨论,以及 YouTube、X 上近期围绕 Claude Code、AI coding workflow 的公开内容整理而成。Reddit 赞数、评论数和社交媒体热度只代表社区讨论强度,不等同于行业统计。本文重点讨论工程流程变化,不评价某个具体 AI 编程工具的能力上限。
过去一年,AI 编程工具的主叙事一直很直接:它到底能不能写代码?
从 Cursor 到 Claude Code,从 Codex CLI 到各种 agentic coding 工具,大家最容易被吸引的都是那种演示:输入一句需求,工具读项目、改文件、跑测试,最后给你一个看起来能用的功能。
这个阶段很像早期看自动驾驶视频。车能自己跑起来,已经足够让人兴奋。
但一旦你真的把它放进日常工作,问题就会变得没那么浪漫。AI 能写代码以后,团队最先感受到的未必是“开发速度翻倍”,而是另一个更麻烦的变化:代码来得太快了,没人有足够时间判断它该不该进主干。
Reddit r/ClaudeAI 最近有一条帖子叫 “Reviewing AI-generated pull requests in 2026”,获得了约 2700 个赞和 80 多条评论。这个标题很准确。社区讨论的重点已经不是“AI 能不能写”,而是“AI 写完以后,人类怎么审”。
我觉得这才是 AI 编程真正进入工程现场的标志。
代码产量上来了,review 会先堵住
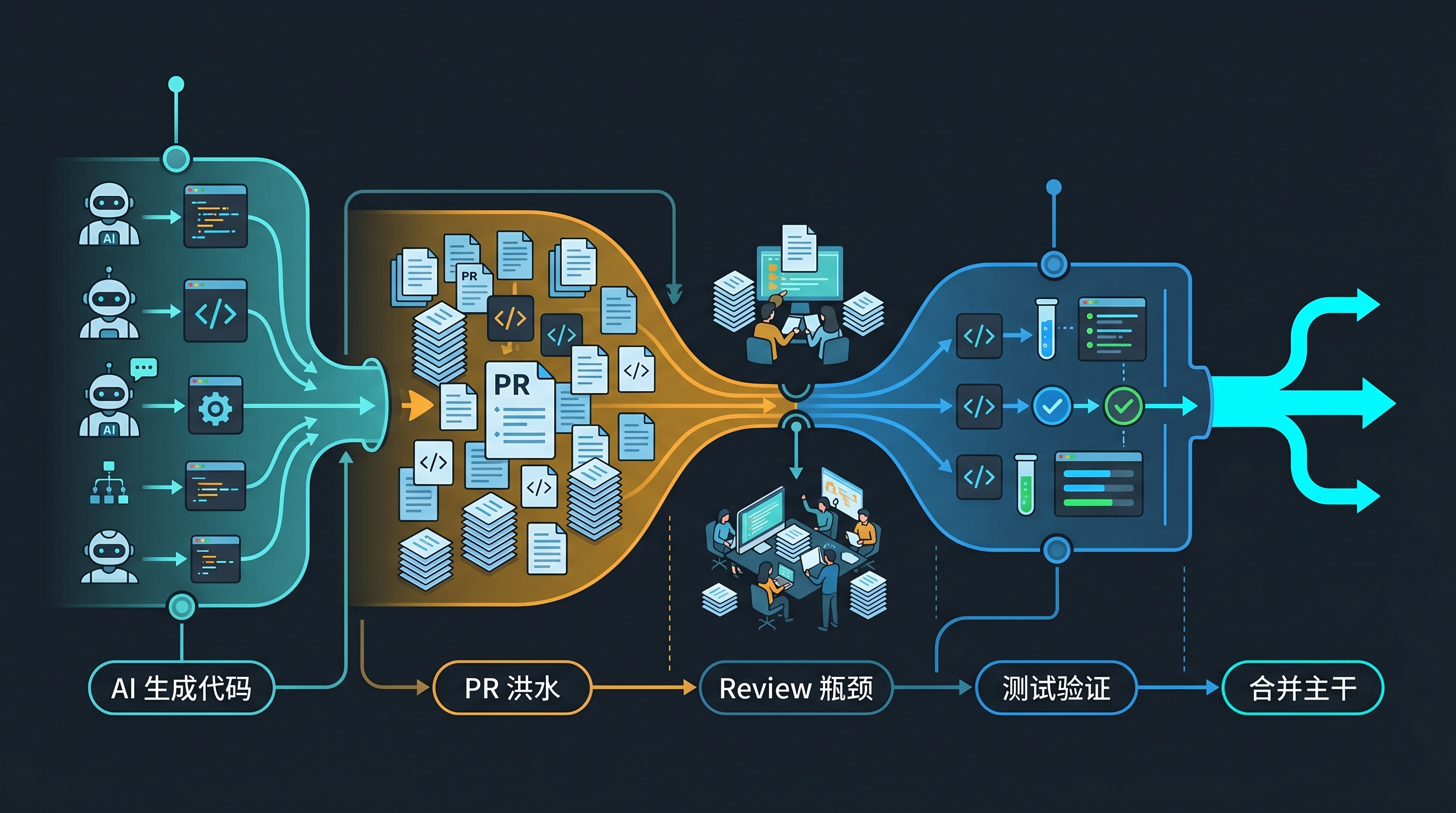
传统软件团队里,写代码和审代码之间有一种粗糙但可用的平衡。
一个开发者一天能写出的 diff 有上限。需求要拆,环境要配,文档要查,测试要跑,线上历史包袱也要翻。哪怕 review 经常排队,输入量仍然被人的手速和注意力限制着。
AI 代码助手把这个天然限速器拆掉了一部分。
它不一定让每一行代码都更好,但它让代码变得非常便宜。脚手架、接口适配、测试样例、重构草稿,以前可能要半天,现在十几分钟就能铺出来。更夸张一点,一个人可以让几个 agent 同时处理不同分支,再把结果打包成 PR。
站在个人视角,这是爽感。
站在团队视角,这是输入洪水。
过去 reviewer 看到一个 PR,会默认它背后有一个人花了几小时思考和实现。现在 reviewer 看到的可能是一个同事花十分钟提示 AI 生成的 1200 行 diff。PR 变多只是表层现象,更麻烦的是,PR 背后的思考密度开始变得不稳定。
有些 AI diff 很干净,甚至比人写得规整。有些则像一份很会包装的作业:命名合理,结构像样,测试也有,但关键设计假设没人真的想过。
这会制造一种新的 review 疲劳。你不是看不懂代码,而是不知道该相信它到什么程度。
AI PR 的麻烦在于“看起来太像对的”
很多人以为,AI 生成的代码更规整,所以应该更好审。
实际体验往往相反。
人工写出的烂代码,经常会把问题暴露在脸上。命名混乱,结构别扭,重复明显,测试缺失。reviewer 很快就会警觉。
AI 写出的烂代码更像“精装修”。函数拆得像那么回事,错误处理也有,测试能跑过,PR 描述甚至还挺完整。它最危险的地方不是粗糙,而是顺滑。
你需要多问几句:这个改动解决的是不是原问题?它有没有引入新的状态分支?它是不是绕过了已有抽象?测试是在验证行为,还是只是在迎合当前实现?这个局部修复会不会变成下个月的维护成本?
这些问题都不是靠“能编译”“测试绿了”就能回答的。
AI PR 的难点不在语法,而在意图。
审同事的代码时,你多少能从上下文里判断他的思路。他为什么这么改,他知不知道这块历史包袱,他有没有理解业务约束。如果不确定,还可以拉过来问两句。
但 AI 生成的代码经常缺少这条思考链。提交者可能也只是确认了结果能跑,并没有完全吃透每个局部决策。于是 reviewer 面对的不是一个清楚表达意图的人,而是一段看起来已经完成的代码成品。
这时审查难度反而上升了。你不仅要审代码,还要反向推断它背后的决策到底成不成立。
“让 AI 多写测试”只能解决一部分问题
遇到这个问题,很多人的第一反应是:那就让 AI 多写测试。
当然应该让它写。AI 很适合补基础测试、生成回归用例、把遗漏路径暴露出来。问题是,测试并不会自动带来信任。
AI 很擅长根据现有实现生成能通过的测试。它经常验证的是“代码现在就是这样跑的”,而不是“业务本来就应该这样跑”。如果需求被理解错了,测试也会跟着错。如果提示词里没有边界条件,它也不会凭空知道你线上最怕哪个异常分支。
很多 AI 生成的测试还有一个特点:它们让人放心,但放心的理由不够扎实。
测试文件变多了,覆盖率看起来上去了,CI 也绿了。可是 reviewer 仍然要判断:这些测试有没有覆盖真实需求?有没有失败场景?有没有权限边界、并发、状态迁移?未来同类问题再出现时,它们能不能真的拦住?
如果没人做这层判断,测试越多,虚假的安全感也越强。
reviewer 的工作会越来越像系统设计守门
以前很多 code review 停留在局部层面。变量名好不好,重复代码要不要抽,边界条件有没有漏,接口是不是清晰。
这些还重要,但 AI 会把 reviewer 往更上游推。
因为底层实现越来越便宜,真正稀缺的是架构判断、边界感和取舍能力。一个 AI PR 最值得审的,往往不是某一行有没有写错,而是它有没有改变系统的形状。
它可能为了修一个小 bug 新增一套抽象。可能在业务层和基础设施层之间制造反向依赖。可能把同步问题包成异步队列,却没有处理重试和幂等。也可能为了让测试通过,mock 掉了真正应该暴露的问题。
这些事 AI 都能做得很自然。
它会沿着提示词找最短路径,尽量交付一个能展示结果的实现。至于这个实现三个月后会不会变成包袱,它不会天然在意,除非你把这个约束明确写进去,并且真的检查它有没有做到。
所以 AI 编程时代的 reviewer 不只是代码检查员,更像系统设计守门人。
他要判断的不是“这段代码能不能工作”,而是“这段代码进来以后,会不会让下一次修改更难”。
最好的应对不是接受更多 PR,而是压窄每个 PR
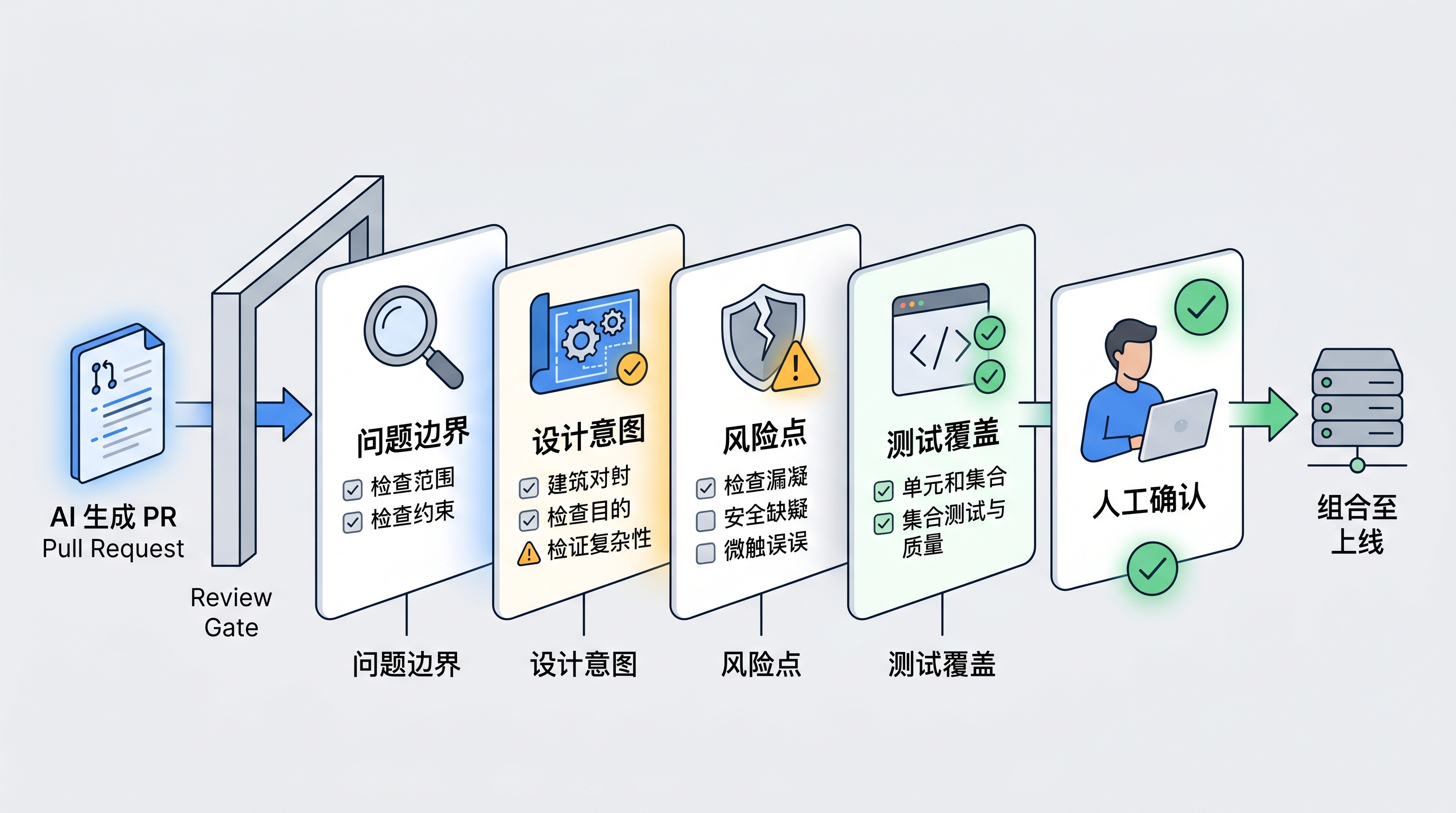
AI 让代码产出变快以后,最直觉的做法是吞下更多 PR。
我觉得这是危险的。
更健康的方向可能是反过来:让每个 PR 变小,让每个改动更容易被解释。
AI 可以负责探索,负责生成候选实现,负责补样板代码。但进入 review 流程时,团队应该主动收窄 diff。一个 AI-assisted PR 至少要说清楚:这次只解决什么问题,哪些文件是核心改动,哪些只是机械调整,AI 参与了哪些部分,人类确认过哪些设计决策。
这不是流程洁癖。
diff 变窄以后,reviewer 才能把注意力放在判断上,而不是被一大片“看起来都合理”的改动淹没。AI 可以扩大探索空间,但合并到主干之前,人类必须负责收敛。
真正危险的不是 AI 写错一行代码。真正危险的是团队开始接受巨大、模糊、解释不清的 AI PR,然后把 review 变成例行点头。
PR 描述会变成新的工程文档
过去很多团队的 PR 描述都很随意。
“fix bug”“update logic”“refactor service” 这种标题大家都见过。只要 diff 不大,reviewer 还能靠读代码补上下文。
AI 生成代码以后,这种习惯会越来越不够用。
reviewer 需要先知道这次改动的意图是什么,AI 做了哪些假设,人类做过哪些验证,哪些地方还没有把握。否则他只能在代码里盲猜。
我更愿意把未来的 PR 描述看成一份小型工程文档。它不需要很长,但要把几个关键点讲清楚:问题边界是什么,为什么选这个实现路径,跑过哪些验证,哪些风险还需要重点看。
如果用了 AI,也最好说明哪些部分是生成、重写或大规模整理过的。
这不是为了道德审判,也不是为了证明“我没有偷懒”。重点是协作。reviewer 知道哪些地方是 AI 大量参与的,才能合理分配注意力。如果提交者自己也说不清这些部分,那这个 PR 可能还不适合进入 review。
没有团队的人,也要给自己做 review
这件事不只影响公司团队。
很多独立开发者、内容创作者、自动化爱好者也在用 Claude Code 或类似工具快速做项目。没有同事 review,不代表 review 可以消失。
个人项目反而更容易被 AI 的完成感骗到。
页面能打开,接口能返回,脚本能跑,README 也写好了。看起来已经结束了。可真正的问题可能藏在错误处理、数据迁移、权限边界、部署脚本或者长期维护里。
我现在更倾向于把个人项目的 AI 工作流拆成两段:先让 AI 尽情生成,再强制切到审查模式。
审查模式里,不要急着继续补功能。先让 AI 总结本次 diff 的意图和风险点,再换一个会话或另一个模型从反方挑刺。然后只看关键路径文件,不要被大量辅助代码分散注意力。最后手动跑一次最接近真实使用场景的端到端流程。
这套流程不复杂,但它能防止一个很常见的问题:你以为自己在开发,其实只是在不断接受 AI 给出的下一个补丁。
AI 编程的竞争会转向验证能力
过去,AI 编程工具的竞争集中在生成能力。谁补全更准,谁改代码更快,谁能一次性完成更复杂的任务。
接下来,验证能力会变得越来越重要。
一个成熟的 AI 编程工作流,不能只回答“我能生成什么”。它还要回答:这段代码为什么这样写?有没有更简单的方案?风险在哪里?哪些测试证明它是对的?如果上线后出问题,怎么回滚?
这也意味着,开发者的核心能力不会消失,只是位置会变化。
以前你亲手写更多代码,所以价值体现在实现速度和细节熟练度。以后你可能写得少一些,但要更擅长定义问题、约束范围、识别风险、设计验证链路。
AI 没有让工程判断变得不重要。
它只是让缺乏工程判断的代码,以更快速度进入你的仓库。
最后
“AI 会写代码”已经不新鲜了。
真正的新问题是:当代码变得太容易生成,团队还有没有能力判断哪些代码值得留下。
如果一个团队只是把 AI 当成更快的打字员,它很快会遇到 review 堵塞、测试失真、架构变形和责任模糊。
如果一个团队把 AI 当成探索和生成工具,同时把人类注意力集中在意图、边界、验证和系统形状上,AI 才可能真正提升工程效率。
未来程序员的工作不会只剩下“点接受”。更可能的情况是:AI 负责把可能性摊开,人类负责把不该进主干的可能性挡在门外。
这听起来没有“一句话生成完整 App”那么兴奋,但它更接近真实的软件工程。