
“我用了三个月的 Claude Code,API 账单花了 $500。然后我发现了 Ollama,现在成本是零。”
这是一个真实的故事,来自一位独立开发者。在 AI 编程工具日益普及的 2026 年,成本和隐私已经成为很多开发者挥之不去的痛点。
2026 年 1 月 16 日,一个看似普通的更新改变了这个局面:Ollama v0.14.0 发布,宣布兼容 Anthropic Messages API。
这意味着什么?
简单来说,你现在可以用 Claude Code + 本地模型 = 零成本、全隐私的 AI 编程体验。

为什么这个组合如此重要?
在深入配置之前,让我们先理解为什么这个组合如此重要。
云端 AI 编程的痛点
| 痛点 | 具体表现 |
|---|---|
| 成本压力 | Claude Opus 4.5: $5/1M tokens,高频开发者月账单轻松超过 $100 |
| 隐私担忧 | 公司代码、敏感逻辑被上传到云端,合规风险 |
| 网络依赖 | 离线环境无法使用,网络延迟影响体验 |
| 用量限制 | API 有速率限制,高峰期可能被限流 |
Claude Code + Ollama 的解决方案
当 Claude Code 遇上 Ollama,你得到的是一个:
- 完全免费:本地模型运行,零 API 成本
- 真正隐私:数据永不离开你的机器
- 离线可用:无需网络连接
- 无限制使用:想怎么用就怎么用
什么是 Claude Code 和 Ollama?
Claude Code:Anthropic 的 CLI 编程助手
Claude Code 是 Anthropic 官方推出的命令行 AI 编程工具:
- 多文件编辑:可以同时修改多个文件
- Git 集成:原生支持 Git worktrees
- 长上下文:支持 200K token 的上下文窗口
- MCP 支持:可扩展的 Model Context Protocol
Ollama:本地 LLM 运行平台
Ollama 是一个简单的本地 LLM 运行工具:
- 一键安装:macOS/Linux/Windows 全平台支持
- 模型丰富:支持 Llama、Qwen、DeepSeek 等众多开源模型
- API 兼容:从 v0.14.0 开始兼容 OpenAI/Anthropic API
- 量化友好:支持 GGUF 格式,显存需求低
快速开始:5 分钟搭建本地 AI 编程环境
第一步:安装 Ollama
macOS/Linux:
|
|
Windows: 下载 Ollama 官方安装包
验证安装:
|
|
第二步:拉取代码模型
推荐的本地编程模型:
| 模型 | 大小 | 适用场景 | 拉取命令 |
|---|---|---|---|
| qwen2.5-coder:14b | ~9GB | 通用编程,中文友好 | ollama pull qwen2.5-coder:14b |
| deepseek-coder:16b | ~10GB | Python/JS 专用 | ollama pull deepseek-coder:16b |
| codegemma:7b | ~5GB | 轻量级任务 | ollama pull codegemma:7b |
| qwen2.5-coder:32b | ~20GB | 高性能编程 | ollama pull qwen2.5-coder:32b |
我的推荐:从 qwen2.5-coder:14b 开始,平衡了性能和资源需求。
第三步:启动 Ollama 服务
|
|
验证服务运行:
|
|
第四步:配置 Claude Code
设置环境变量:
|
|
或者使用配置文件: ~/.claude/config.json
|
|
重新加载配置:
|
|
第五步:验证连接
|
|
如果看到本地模型回复,恭喜你,配置成功了!
实战测试:本地 vs 云端
我用了三个真实任务来测试本地模型的实际表现:
测试 1:简单 CRUD 生成
任务:用 Node.js + Express 写一个简单的 TODO API
云端 Claude (Opus 4.5):
- 速度:~3 秒
- 质量:一次性生成,代码规范,带注释
本地 Qwen2.5-Coder 14B:
- 速度:~8 秒
- 质量:一次性生成,代码可用,需要小幅调整
结论:对于常见任务,本地模型完全够用。
测试 2:代码审查和优化
任务:审查一段 200 行的 JavaScript 代码,提出优化建议
云端 Claude:
- 分析全面,包含性能、安全、可维护性多角度
- 提供具体的重构方案
本地模型:
- 能发现主要问题
- 建议相对简单,但实用
结论:本地模型适合日常代码审查,复杂架构问题可能需要云端。
测试 3:理解大型代码库
任务:解释一个开源项目的核心架构
云端 Claude:
- 能快速理解整体结构
- 提供深入的分析
本地模型:
- 需要更多上下文
- 但可以无限次提问,不用考虑成本
结论:本地模型的优势在于"免费",可以反复提问直到理解。
性能对比详解
| 维度 | 云端 Claude Opus 4.5 | 本地 Ollama (14B) |
|---|---|---|
| 成本 | $5/1M tokens (~$50/月重度用户) | 完全免费 |
| 隐私 | 数据上传到云端 | 100% 本地 |
| 速度 | ~3-5 秒响应 | ~8-15 秒响应 |
| 质量 | 最强 | 中上等 |
| 上下文 | 200K tokens | 取决于模型配置 |
| 网络 | 必须联网 | 完全离线 |
| 硬件 | 无要求 | 需要 GPU/大内存 |
硬件需求参考
| 模型大小 | 推荐 GPU | 最小内存 | CPU 推理速度 |
|---|---|---|---|
| 7B | GTX 1060 6G | 16GB | ~5 tok/s |
| 14B | RTX 3060 12G | 32GB | ~3 tok/s |
| 32B | RTX 4070 16G | 64GB | ~2 tok/s |
纯 CPU 运行:可以,但速度会慢很多(~0.5 tok/s)
适用场景分析
✅ 本地模型非常适合:
-
个人学习项目
- 练习编程、做 side project
- 成本敏感,不需要最强性能
-
隐私敏感场景
- 公司内部代码
- 金融、医疗等行业
- 不想把代码上传到云端
-
离线环境
- 飞机上、咖啡店(网络差)
- 内网开发环境
-
高频使用
- 每天大量使用 AI 编程
- 月账单超过 $50 的人
❌ 本地模型不适合:
-
复杂架构设计
- 需要深度的技术洞察
- 云端 Opus 的能力仍然领先
-
硬件资源有限
- 没有 GPU,内存 < 16GB
- 笔记本电脑性能较弱
-
快速原型开发
- 需要最快的响应速度
- 对代码质量要求极高
高级配置技巧
1. 模型热切换
创建一个脚本快速切换模型:
|
|
使用:
|
|
2. 并发配置
优化 Ollama 的并发设置:
|
|
3. 量化模型节省显存
使用量化版本:
|
|
量化等级对比:
| 量化 | 显存需求 | 质量 | 速度 |
|---|---|---|---|
| Q4_K_M | ~9GB | 95% | 最快 |
| Q5_K_M | ~11GB | 98% | 很快 |
| Q8_0 | ~15GB | 99.9% | 快 |
| F16 | ~28GB | 100% | 中等 |
4. 与 VS Code 集成
使用 Claude Code VS Code 扩展:
- 安装扩展:
Claude Code - 设置使用本地 API:
|
|
混合策略:取长补短
经过实际使用,我发现最佳方案是 云端 + 本地混合使用:
混合使用决策树
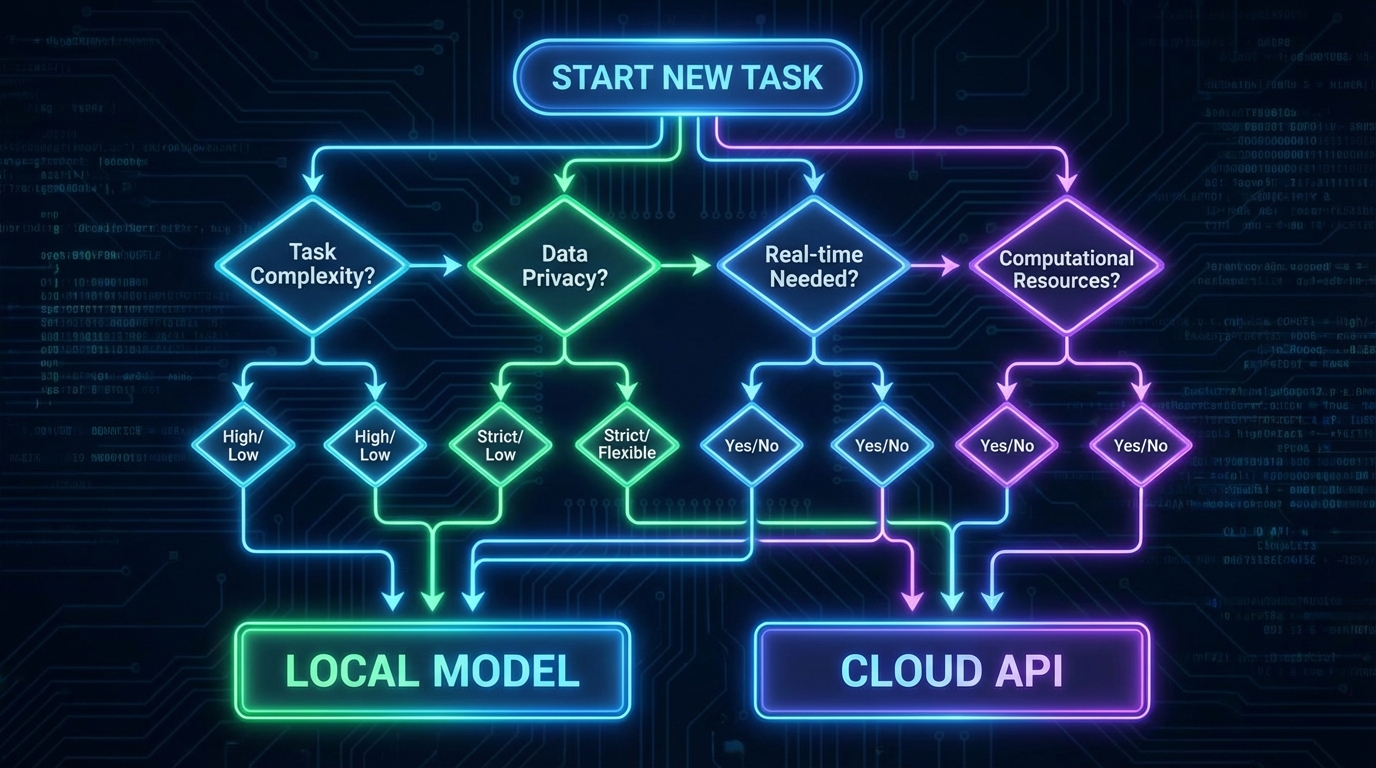
决策流程:
|
|
实际使用建议
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 日常编码 | 本地 14B | 免费,够用 |
| 代码审查 | 本地 14B | 可以反复问 |
| 学习新技术 | 云端 Sonnet | 理解更深入 |
| 公司项目 | 本地模型 | 隐私优先 |
| 复杂重构 | 云端 Opus | 能力更强 |
| Side Project | 本地模型 | 成本优先 |
常见问题解决
Q1: Claude Code 连接不上 Ollama
检查清单:
|
|
Q2: 模型生成质量差
可能的解决方案:
- 换更大的模型(7B → 14B → 32B)
- 调整 temperature 参数
- 提供更详细的 prompt
- 使用量化级别更高的版本
Q3: 速度太慢
优化方案:
- 确认使用了 GPU:
nvidia-smi查看显存占用 - 降低量化等级(Q8 → Q5 → Q4)
- 换更小的模型
- 减少上下文长度
Q4: 显存不足
解决方案:
- 使用更小的模型
- 使用 Q4 量化
- 增加 swap 空间(CPU 模式)
- 关闭其他占用 GPU 的程序
其他本地方案对比
除了 Ollama,还有其他本地方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| Ollama | 最简单,模型多 | 定制性较弱 |
| LM Studio | GUI 界面,易用 | 占用资源多 |
| llama.cpp | 最灵活,高性能 | 需要编译 |
| vLLM | 生产级性能 | 配置复杂 |
| Oobabooga | Web UI,功能全 | 资源占用大 |
对于个人开发者,Ollama 是最推荐的:简单、免费、够用。
未来展望
本地 AI 编程的未来是什么?
趋势 1:模型能力持续提升
- 2026 年:开源 7B 模型 ≈ 2024 年 GPT-4
- 2027 年:本地 14B 可能追平云端 Opus
趋势 2:硬件成本下降
- 专用的 AI 推理卡(如 NPU)将普及
- 笔记本电脑原生支持大模型推理
趋势 3:混合架构成为主流
|
|
总结
Claude Code + Ollama 的组合,让本地 AI 编程变得简单、免费、隐私友好。
立即开始:
|
|
我的建议:
- 如果你是个人开发者:直接上本地方案,省钱
- 如果你在大公司:本地方案解决隐私问题
- 如果你是独立黑客:本地方案降低运营成本
最重要的:
不要等待"完美时机"。现在就开始,哪怕用最小的 7B 模型,也比完全不用好。
“最好的本地 AI 编程环境,是你现在就开始用的那个。”