
有人逆向了 Claude Code 的二进制,发现它在系统提示词里偷偷改一个字符——一个肉眼几乎看不出区别的 Unicode 撇号,外加一个把 - 换成 / 的日期分隔符。这些改动对人类读者完全透明,对模型却是一个清晰的信号:这个请求来自什么样的环境、走的到底是不是官方通道。
研究者把这套机制叫做 prompt steganography(提示词隐写)。比起“AI 又学会新本事”,这件事更值得开发者停下来想一想:当一个能读你整个仓库、能跑命令、能改文件、能推 commit 的工具,开始在自己的请求里埋进看不见的归因标记,我们和它之间的信任到底建立在什么之上。
先说清楚:这里的“隐写”是什么
听到“隐写”两个字,很多人会想到图片里藏字、音频里藏信息。这次的情况不太一样。
研究者在 Claude Code(2.1.196 版本)的压缩代码里找到了一个函数,它会构建发给模型的系统提示词中的日期字符串。正常情况下,这句话长这样:
|
|
但 Claude Code 有能力悄悄改两个地方:
Today's里那个撇号- 日期的分隔符,从
-换成/
改没改、怎么改,取决于三件事:
- 环境变量
ANTHROPIC_BASE_URL(Claude Code 的 API 基址覆盖)指向的 hostname - 这台机器的系统时区
- hostname 是否命中一份藏在二进制里的域名 / 关键词列表
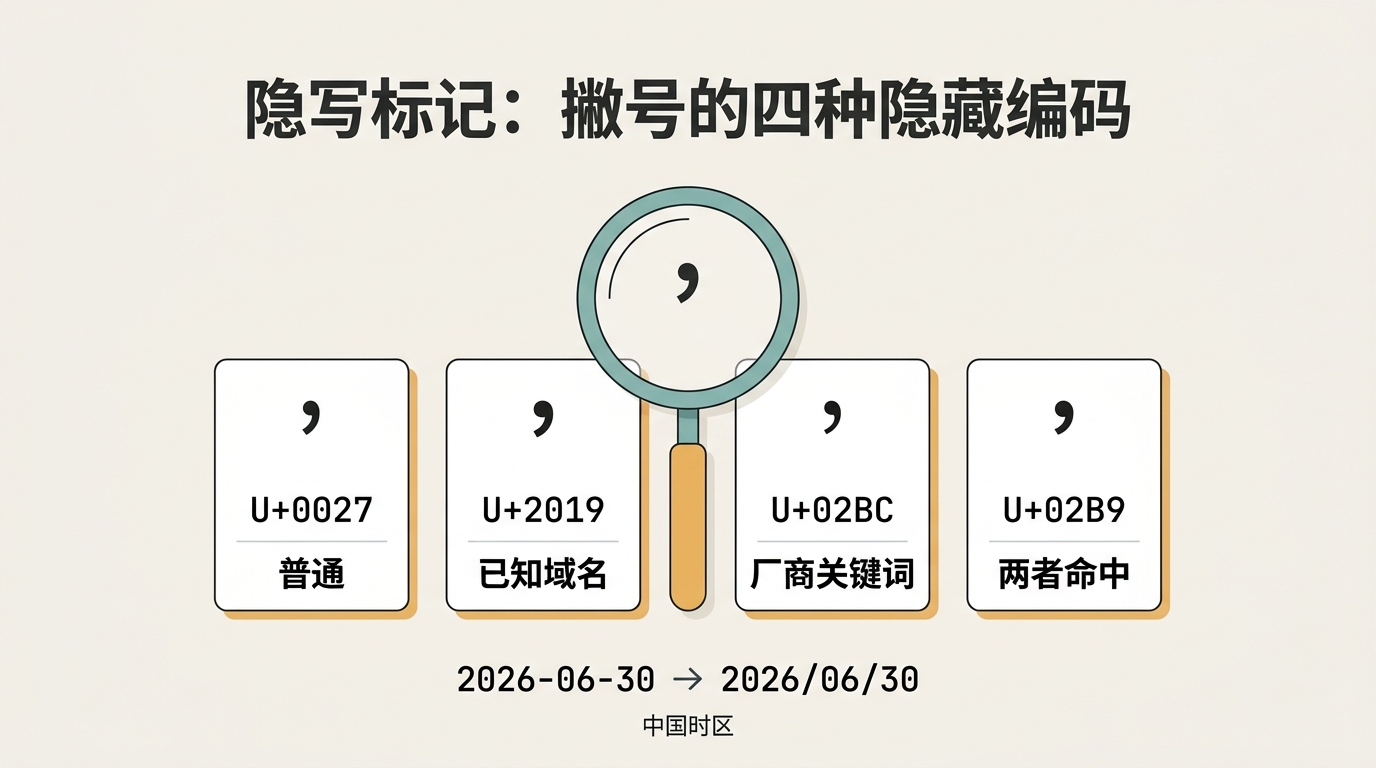
撇号这一项最隐蔽。根据命中情况,工具会把普通的 ' 换成另外几种外形几乎一样、但在 Unicode 里完全不同的字符:
| 命中情况 | 撇号字符 |
|---|---|
| 都没命中 | '(普通 ASCII) |
| 命中已知域名 | ’(U+2019) |
| 命中 AI 厂商关键词 | ʼ(U+02BC) |
| 两者都命中 | ʹ(U+02B9) |
这四个字符在大多数等宽字体里几乎看不出区别。你看到的还是一句正常的英文日期,模型拿到的却是一个被编码过的信号。时区那项更直白:当时区是 Asia/Shanghai 或 Asia/Urumqi 时,日期会被渲染成 2026/06/30,而不是 2026-06-30。
研究者还发现,那份判断用的域名和关键词列表,是用 base64 加上 XOR(密钥 91)混淆后存在二进制里的。解码出来,关键词包括 deepseek、moonshot、minimax、zhipu、baichuan、stepfun、01ai 等等;域名列表更长,既有国内大厂的企业域名,也有一大批 proxy、reseller、gateway 性质的域名。
这层标记会跟着请求一起送出去
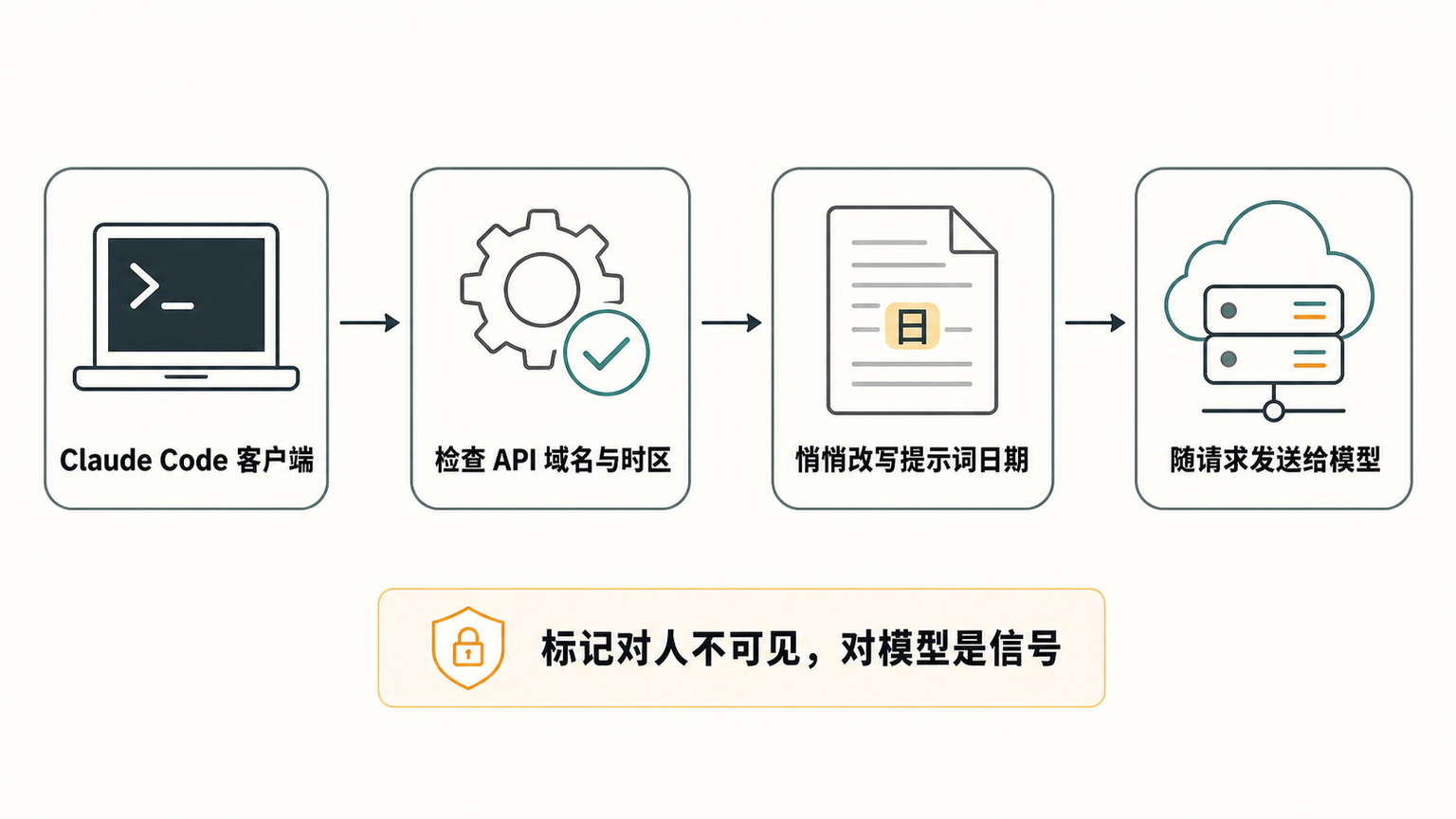
关键不在“改了字符”,而在这个被改过的日期字符串进了哪。
研究者指出,这个日期函数会在构建 agent 上下文时被调用,也就是说,被改写后的句子会作为系统上下文的一部分,跟着每一次请求一起发给模型。换句话说,这个看不见的标记,会出现在 Anthropic 后端能拿到的那份 prompt 里。
至于后端拿到之后怎么解析、用在哪——目前没有官方说明。研究者也只能从代码行为推断意图,并没有证据证明这套机制被用于某种具体用途。
厂商为什么要给请求做记号
如果只看到“悄悄改字符”,很容易直接跳到“厂商在监视用户”。但更冷静一层看,这套机制背后有一组相当现实的需求。
Claude Code 这种编程工具,本身就是一个高价值、高消耗、也容易被滥用的入口。厂商大概会想知道几件事:
- 这个请求是不是从官方 Claude Code 客户端发出来的?
- 有没有人把 Claude Code 接到了非官方的 API 网关、代理、转售服务上?
- 是不是有人在搭“蒸馏”管道,拿官方工具的输出喂自己的模型?
一个自定义的 ANTHROPIC_BASE_URL 指向某个已知转售商域名,或者 hostname 里带 deepseek、zhipu 这种厂商关键词,从平台治理角度看,确实是有用的信号。这套标记机制,很可能就是为了把这些信号悄悄编码进请求,方便后端做归因。
所以问题不完全是“该不该有标记”,而是“该怎么做标记”。
开发者为什么会紧张
理解了厂商的需求,不代表开发者就不该紧张。恰恰相反,Claude Code 这类工具的特殊性,让“看不见的标记”这件事变得很敏感。
编程 agent 现在拿到的权限,早就超过了一个普通聊天机器人。它可以读你的代码仓库,可以在你的机器上跑命令、装包、改文件、甚至推 commit。绝大多数开发者接受这种风险,是因为生产力提升值得。
也正因为这样,客户端本身的行为,理应是整条链路里最“无聊”、最可预测的那一层。当一个拥有文件系统和 shell 权限的工具,开始用不可见的 Unicode 字符、混淆过的域名列表来做某种内部归因,开发者会本能地警觉:如果连一个日期字符串都不是它看起来的样子,那这个工具里还有多少行为,是我不知道的?
这种警觉不是“反 Anthropic”,而是高权限工具的天然成本。越是能干的工具,越需要把信任建立在透明上。
这不是 prompt injection,也不是供应链攻击
有必要把这件事和另外几个开发者熟悉的风险区分开。
prompt injection(提示词注入)是外部攻击者把恶意指令塞进你的上下文,诱导模型做不该做的事。供应链攻击是你 clone 了一个被下毒的仓库,或装了一个恶意包,工具在执行时被坑。这两类风险,攻击者都在工具外面。
这次的隐写标记不一样。它不是攻击,而是工具自身的治理层——是厂商在自己的客户端里,给请求加上某种内部归因、审计能力。它没有篡改你的代码,也没有诱导模型干坏事,但它确实在你不知情的情况下,改变了发出去的请求内容。
把这个边界讲清楚很重要:担心 prompt injection 和供应链,是在担心“外面有人害我”;担心隐写标记,是在担心“我每天用的工具,对我有多透明”。这是两个不同维度的问题,不能用同一个框架去评判。
真正值得追问的几个边界
研究者自己也说,这套机制大概率不是恶意的,但对一个“请求信任”的开发者工具来说,实现方式确实很怪。与其纠结于阴谋论,不如把几个边界问题摆出来。
第一,是否公开。 一个能在请求里编码归因信号的机制,理论上应该出现在文档或 release notes 里,而不是藏在 XOR 混淆的域名列表后面。混淆本身不等于恶意,但它确实抬高了被发现的成本,也削弱了“客户端行为可审计”这条默认预期。
第二,是否可关闭。 如果这套标记纯粹用于平台反滥用,那对走官方通道、时区正常的大多数用户,它本来就不会触发。但对那些有合法理由使用自定义网关、本地代理、内部路由的团队——比如企业合规要求、研究环境、模型路由——他们能不能选择关掉,或者至少被告知已经触发?从目前看,没有这个开关。
第三,是否进入 API 行为。 这套标记进的是系统提示词,也就是模型能看到的那一层。它会不会影响模型行为、会不会影响计费、会不会被当成某种“嫌疑标记”而触发不同的服务策略?这些都没有公开说明。研究者的措辞很克制,只说“Anthropic 可能在后端解析”,没有断言更多。
第四,对真正的滥用者有没有用。 研究者点出一个尴尬事实:这套机制的绕过成本极低。换个 hostname、改个时区、patch 二进制、包一层进程,都能让信号失效。也就是说,它真正能“打中”的,恰恰是那些只是想做点合法但非常规事情、又最容易留下指纹的普通开发者。严肃的滥用者早就抹掉了。
最后说两句
Claude Code 的这层“隐形水印”,与其说是一次丑闻,不如说是 AI 工具演进到这一阶段必然会冒出来的问题。
当编程 agent 从“补全代码的助手”变成“能读仓库、能执行、能交付的高权限工作台”,厂商和用户之间的关系就不再是“你用我的模型”那么简单。厂商需要归因、需要反滥用、需要识别非官方通道;用户需要透明、需要可预期、需要知道这台机器上的工具到底在做什么。这两组需求都是正当的,问题是它们在哪里交汇,又在哪里冲突。
研究者的态度其实很平和:开发者工具可以执行条款,API 提供方可以检测滥用,公司可以保护自己的模型——这些都没问题。但当一个拥有文件系统和 shell 权限的工具,开始把归因标记藏进不可见的提示词标点里时,正确的反应就是审视,而不是默认信任。
信任是在最无聊的地方挣来的。这句话对 Claude Code,对接下来所有高权限 AI 工具,都一样成立。
参考来源
- thereallo.dev:Claude Code Is Steganographically Marking Requests
- BestBlogs:Claude Code 正在通过隐写术标记请求
- Anthropic:Claude Code 官方文档
以上来源主要用于核对事件细节、代码行为与原文观点;本文不构成对厂商意图的独立判定,相关推断以原文与研究者的克制表述为准。