
Anthropic 发布 Claude Fable 5 和 Claude Mythos 5 后,很多人的第一反应还是很自然:
它比 Opus 4.8 强多少?
它写代码是不是更猛?
它会不会又把 Claude Code 往前推一大截?
这些问题当然重要,但我觉得这次真正值得看的,不是模型又聪明了一点。
更关键的变化是:Anthropic 开始把同一套顶级模型能力,拆成了不同的访问方式、不同的安全边界和不同的价格层级。
换句话说,Claude Fable 5 的重点不是“更强模型终于来了”,而是 Anthropic 正在尝试回答一个更现实的问题:当一个模型强到可以同时帮助程序员迁移代码、帮助科学家做蛋白设计、也可能帮助坏人做高风险网络攻击时,这个模型到底应该卖给谁、怎么卖、什么任务该拦、什么任务该换模型处理?
这件事,比一次普通模型升级要大得多。

先说清楚:Fable 5 和 Mythos 5 是什么关系
根据 Anthropic 官方介绍,Claude Fable 5 是面向公众开放的高能力模型。官方把它称为一个 “Mythos-class model”,也就是 Mythos 级别的模型,但加上了适合通用使用的安全防护。
Claude Mythos 5 则是同一底层模型的另一种形态。它面向更受限的可信访问场景,尤其是网络防御、关键基础设施安全和部分生命科学研究。官方说得很直接:Mythos 5 拥有最强的网络安全能力,但这些能力不会直接对普通用户开放。
这里最有意思的地方在于,Fable 和 Mythos 并不是传统意义上的“两个不同档次模型”。它们更像是同一颗大脑,套上了不同的安全外壳。
普通用户拿到的是 Fable 5。它可以做软件工程、知识工作、视觉理解、科研推理和长任务,但遇到网络安全、生物化学、模型蒸馏等高风险请求时,会触发安全分类器。命中之后,系统不会继续让 Fable 5 回答,而是把请求交给 Claude Opus 4.8 处理,并告知用户发生了 fallback(回退)。
官方给出的数字是,平均少于 5% 的会话会触发这种机制。也就是说,绝大多数普通使用不会受影响,但在高风险区域,Anthropic 会主动把最强能力收回来。
这就是这次发布最值得拆解的地方。
过去我们讨论模型安全,常见逻辑是“能不能回答”。能回答就是放行,不能回答就是拒绝。
Fable 5 开始变成另一套逻辑:普通任务用最强模型,高风险任务换到更保守模型,可信用户通过受限项目访问解除部分护栏的版本。
它不只是拒绝,而是在路由。
定价也变成了产品信号
Claude Fable 5 的 API 模型名是 claude-fable-5。官方给出的价格是每百万输入 tokens 10 美元,每百万输出 tokens 50 美元。Mythos 5 的价格与 Fable 5 相同。
这个价格不便宜。它比 Opus 4.8 的公开价格更高,也明显把 Fable 放在了一个“顶级能力按需使用”的位置上。
但价格本身不是最关键的。关键在于,Anthropic 把价格、能力和访问边界放在一起设计了。
如果你只是问日常问题、写普通文案、做轻量总结,Fable 5 显然不是最经济的选择。它真正适合的是那些“贵一点也值得”的任务:大型代码库迁移、复杂代码审查、金融推理、科研假设生成、长周期 Agent 执行、难度较高的视觉理解。
这就和过去的“模型排行榜”思维不太一样。
以前我们习惯问:哪个模型最强?
现在更应该问:什么任务值得用最强模型?什么任务应该用更便宜的模型?什么任务虽然需要强能力,但不能让普通开放模型直接处理?
模型厂商也在回答这个问题。

Anthropic 这次其实没有把 Fable 5 包装成“所有任务都该用的默认模型”。它更像是在给高价值任务定价。你可以把它理解为 AI 里的“专家号”:它不是便宜,不是无处不在,但当你真的需要它时,它的价值来自一次复杂任务能否被完整解决。
官方案例真正想说明什么
Anthropic 给了很多能力展示。比如 Stripe 在 5000 万行 Ruby 代码库里做大规模迁移;Cognition 的 FrontierCode 评测;Hebbia 的金融推理基准;从科学图表中提取数字;根据截图重建 Web 应用;甚至只依靠视觉信息通关 Pokémon FireRed。
这些案例当然有展示肌肉的成分。
但如果只把它们看成“模型又变强了”,反而会错过重点。
这些案例共同指向的是同一件事:Fable 5 被设计来处理更长、更杂、更接近真实工作的任务。
真实工作不是一道单题。它往往包含很多小步骤:理解目标,读取上下文,写代码,检查结果,修 bug,重新规划,最后交付一个可以用的东西。
这也是为什么 Fable 5 和 Claude Code 的结合会让开发者兴奋。
Twitter 上已经有人把它用于代码审查,甚至开玩笑说现在应该让 Claude Code 做一次 “Fable Check”。Simon Willison 也在讨论如何计算 Fable 5 的 token 花费。还有用户反馈说,模型很强,但担心一天就把周额度用完。
这些反馈很真实。
当模型能力进入“复杂任务真的能做”的阶段,用户的关注点会从“它聪不聪明”转向另一个更现实的问题:我该把这么贵的智能用在哪些地方?
安全路由是这次最值得注意的产品设计
Fable 5 的安全机制里,有一个细节特别值得写。
当请求涉及网络安全、生物与化学、模型蒸馏相关内容时,Fable 5 不直接回答,而是交给 Claude Opus 4.8。官方说,用户会被告知发生了 fallback。
这其实是一个很微妙的产品动作。
它不是简单地说“这些话题都不能聊”。如果一个安全研究员问防御性问题,系统仍然可能给出帮助。但 Anthropic 不希望最强模型在这些敏感区域里无差别释放能力,于是选择用一个更保守的模型处理。
这像什么?
有点像金融系统里的风控分流。普通交易直接通过,大额或异常交易进入额外审核。不是所有交易都拒绝,也不是所有交易都放行,而是根据风险等级切换处理流程。
放到 AI 模型里,就是:普通任务给你最强体验;高风险任务进入更谨慎的处理链;经过验证的可信伙伴,才能访问更少限制的 Mythos 5。
这说明 Anthropic 已经不再把“安全”做成模型外面的一层静态护栏,而是在把安全变成模型产品的一部分。
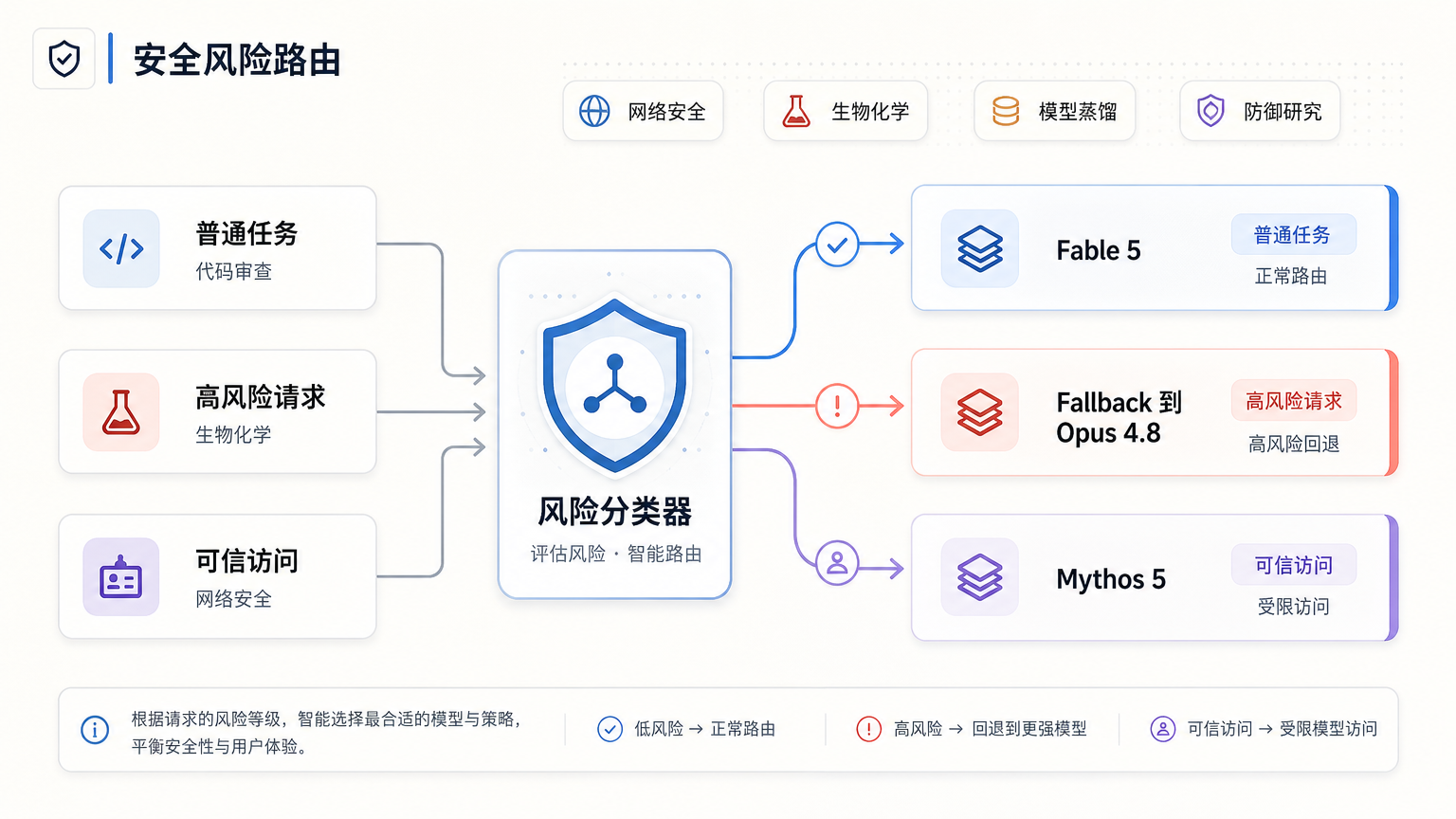
安全不只是红线,也变成了路由规则、访问权限和商业边界。
这会带来一个新问题:正常用户会不会被误伤
当然,这套设计不是没有代价。
只要有分类器,就一定会有误判。尤其是今天的 AI Agent 工程,本身就越来越靠近高风险边界。
比如 Harness Engineering(支架工程)。它本来是让 Agent 更可靠的一套工程方法,包括工具约束、权限控制、验证回路、失败恢复和人类审核。但在安全系统看来,这类内容也可能和“构建更强自动化能力”相关。
今天 Twitter 上已经出现类似抱怨:有人认为 Claude 对 harness engineering 相关任务过于敏感,甚至影响正常 Agent 开发。
这不一定代表 Anthropic 的系统真的大面积误伤,但它提醒我们一个趋势:模型越强,护栏越难做。
过去拦截一个“明显危险请求”相对容易。未来的问题会复杂得多。
同样是写脚本,一个场景是在做企业自动化运维,另一个场景可能是在构建攻击链。同样是网络安全,一个人是在做防御演练,另一个人可能是在找漏洞利用路径。同样是 Agent 编排,一个团队是在做可靠性工程,另一个人可能是在绕过平台限制。
分类器需要判断的不只是关键词,而是意图、上下文、身份和任务边界。
这也是为什么 Mythos 5 没有直接开放给所有人。能力越强,访问控制越像一套许可制度,而不是一个普通开关。
这和之前 Mythos 泄露事件有什么不同
如果你关注过 Anthropic,可能会觉得 Mythos 这个名字并不陌生。
此前 Fortune 报道过 Anthropic 内部测试一个能力很强、风险也很高的模型,当时外界看到的核心矛盾是:Anthropic 有一个更强模型,但因为网络安全风险没有直接发布。
那件事更像一次“模型太危险,所以藏起来”的故事。
这次 Fable 5 / Mythos 5 的发布,性质不一样。
现在 Anthropic 给出的答案不是继续把能力藏起来,而是把能力拆成不同产品形态:公开版本、可信访问版本、高风险 fallback、30 天安全保留政策、不同计划下的阶段性使用权。
也就是说,Anthropic 正在从“要不要发布最强模型”,走向“如何治理最强模型”。
这比单纯泄露更值得关注。
因为它意味着顶级模型的商业化,开始和安全治理绑在一起。
对开发者来说,Fable 5 不是默认答案
如果你是开发者,看到 Fable 5 的第一反应可能是:以后是不是所有 Claude Code 任务都该上 Fable?
我反而觉得不是。
Fable 5 更适合那些你愿意为结果质量付费的节点。
比如:
- 大型重构前的架构审查;
- 复杂 Pull Request 的最终代码审查;
- 需要跨多个文件和工具链的 bug 定位;
- 重要技术方案的反方评审;
- 长周期 Agent 任务里的关键决策步骤。
但如果只是日常补全、简单问答、轻量脚本,便宜模型可能更合理。
这会让 AI 编程工作流变得更像真实团队分工。不是每个问题都找首席架构师,也不是每个任务都交给实习生。真正成熟的工作流,会把不同模型放到不同位置:便宜模型做日常处理,强模型做关键判断,保守模型处理敏感区域,受限访问模型服务特殊行业。
这就是“能力分流定价”的含义。
不是只有一个最强模型,而是不同任务、不同风险、不同预算对应不同模型。
最后,Fable 和 Mythos 的关系说明了 AI 产品的新阶段
Fable 5 和 Mythos 5 的关系,可以这样理解:Fable 是公开市场里的强模型,Mythos 是受限场景里的强能力版本,Opus 4.8 则在高风险 fallback 中承担更保守的处理角色。
这三者不是简单的强弱排序。
Fable 负责把顶级能力带给普通用户,但它必须带着通用安全护栏。Mythos 负责把同一底层能力开放给更可信、更专业的场景,所以它可以解除部分限制。Opus 4.8 在这里不是“更弱替代品”,而是安全路由中的稳妥处理层,用来承接 Fable 不适合直接回答的高风险请求。
这套结构说明,模型产品正在从单一 API 变成一套分层系统。
过去我们买的是一个模型。以后我们买的可能是一整套能力调度:什么时候用强模型,什么时候用便宜模型,什么时候切到安全模型,什么时候需要身份验证,什么时候必须保留日志供安全分析。
所以,Claude Fable 5 真正的新东西,不只是它又聪明了。
它让我们第一次非常清楚地看到:顶级 AI 能力正在被产品化、风控化、分层定价。
模型竞争的下一阶段,可能不再只是“谁的模型最强”。
而是谁能把最强的智能,安全、可控、可持续地卖出去。