
两套叙事
4月16日,Anthropic 正式发布 Claude Opus 4.7。
科技媒体的报道很统一:Mashable 的标题是 “Anthropic: Claude Opus 4.7 has a 92% honesty rate, fewer hallucinations”(Anthropic:Claude Opus 4.7 拥有 92% 的诚实度,幻觉更少),VentureBeat 称其 “narrowly retaking lead for most powerful generally available LLM”(以微弱优势重获最强公开可用大模型宝座)。
官方系统卡(system card,模型评估报告)展示的数据也很漂亮:MASK 诚实度基准(Model Alignment between Statements and Knowledge,陈述与知识一致性基准)达到 91.7%,比 Opus 4.6 的 90.3% 更高;各类幻觉测试均有改善;新增高分辨率图像支持(3.75MP)、任务预算机制(task budget)、xhigh 推理等级。
同一天,r/ClaudeAI 社区出现了一个帖子,标题没那么客气:
“Claude Opus 4.7 is a serious regression, not an upgrade.”(Claude Opus 4.7 是一次严重回归,而非升级)
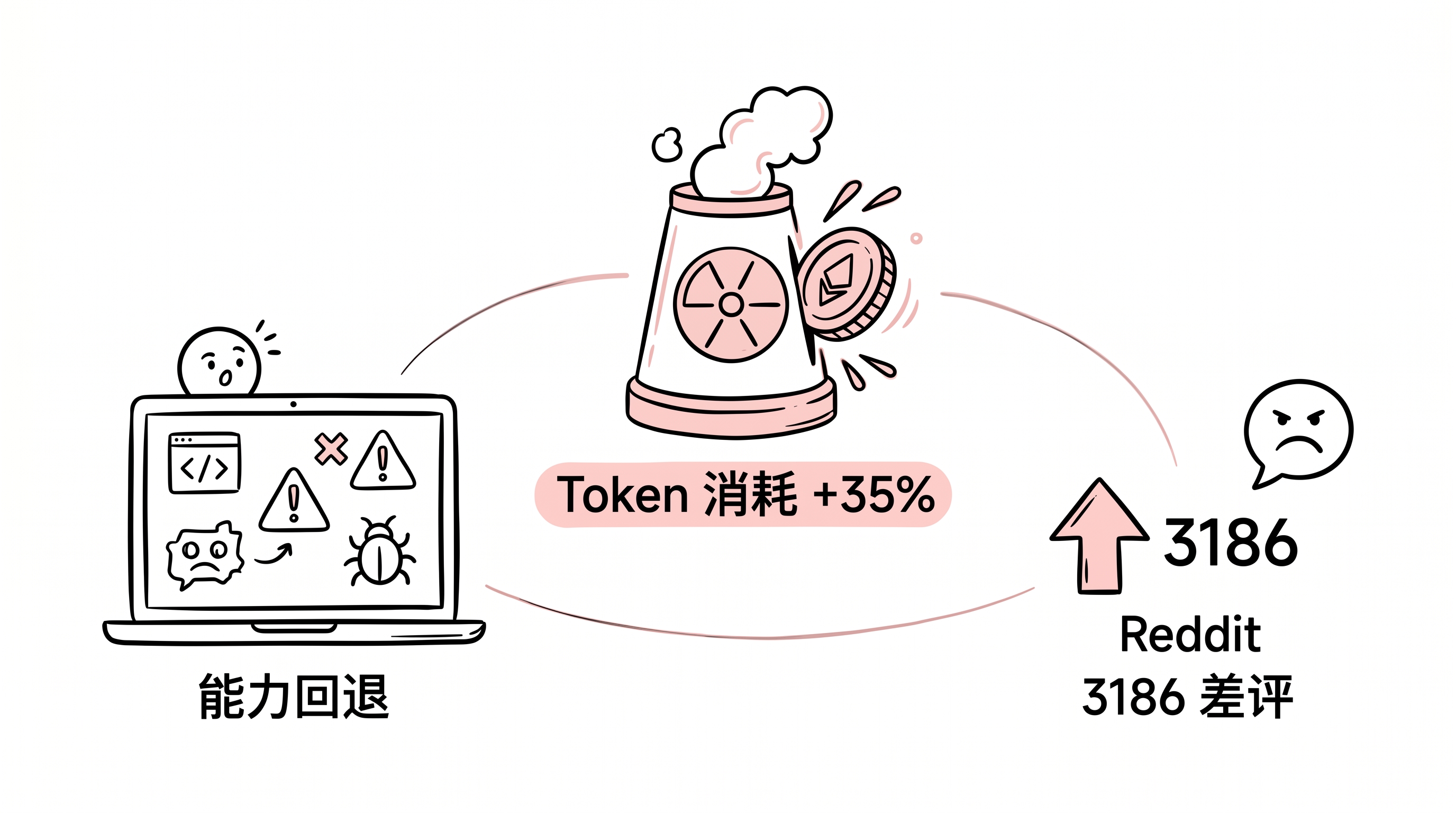
这个帖子最终获得了 ⬆️3186 赞和 803 条评论——几乎与官方介绍帖的 ⬆️3313 赞持平。
一边是 92% honesty(诚实度)的官方数据,一边是高赞差评的用户抱怨。
官方的叙事
Anthropic 对 Opus 4.7 的宣传重点很明确:
诚实度和幻觉改善:官方系统卡显示,Opus 4.7 在 MASK 诚实度基准上达到 91.7%,比 Opus 4.6 的 90.3% 有所提升(虽然仍低于 Opus 4.5 的 95.4%)。各类幻觉测试——事实幻觉、输入幻觉、错误前提拒绝——均有改善。
新特性:
- 高分辨率图像支持:最大分辨率从 1.15MP 提升至 3.75MP,坐标映射 1:1,更适合文档理解和计算机视觉任务
- 任务预算机制(task budget):让模型在 agentic 循环(代理循环)中自动优先处理任务并优雅收尾
- xhigh 推理等级(effort level):介于 high 和 max 之间,提供更精细的推理/延迟控制
能力提升:官方文档称 Opus 4.7 在高级编程、文档分析、视觉任务、记忆系统上都有"meaningful gains"(显著提升)。

用户的体验
Reddit 和 X/Twitter 上的抱怨集中在几个方面:
1. Token 消耗暴增
Opus 4.7 采用了新的 tokenizer(分词器),Anthropic 承认这会导致相同输入消耗 1x 到 1.35x 倍的 token(最多增加 35%)。
Business Insider 报道中,一位用户评论说:“Opus 4.7 eats usage like nuclear reactor."(Opus 4.7 像核反应堆一样吞噬配额)。另一位说:“I just reached my monthly limit just by reading this."(我光看这篇文章就用完了月度配额)。
对于按使用量计费的 Claude Pro 订阅者来说,这意味着同样的问题,同样的对话,成本可能上升三分之一。
2. 能力问题
用户报告的问题包括:
- 简单任务失败:有用户截图显示,Opus 4.7 在数 “strawberry”(草莓)里有几个 p 时出错
- “being lazy”(偷懒):模型承认自己"being lazy"而不做交叉引用
- 态度变化:多位用户提到模型变得更 “combative”(好争辩)
- 幻觉增加:Reddit 帖子 “Opus 4.7 is a master hallucinator”(Opus 4.7 是幻觉大师)获得高赞
更严重的是基准测试数据。Startup Fortune 报道称,在 MRCR(长文档检索与推理)基准上,Opus 4.6 得分 78.3%,而 Opus 4.7 仅得 32.2%——这不仅是回归,简直是崩溃。
Anthropic 开发者解释,公司正在逐步淘汰 MRCR 基准,因为它不能准确反映模型的实际使用场景。用户很难信服:如果基准不能反映实际使用,为什么之前用它来证明 4.6 的能力?
3. Claude Code 用户的崩溃
Claude Code——Anthropic 的旗舰开发者产品——也出现了问题。
GitHub issues #48167 标题直接是:“major quality and performance regression”(重大质量和性能回归)。多位工程师报告:
- 代码审查漏掉明显问题
- 拒绝执行合理的任务
- 对简单问题给出错误答案
一位用户在 X 上说:“Opus 4.7 is the first time I’ve thought ‘Anthropic may be moving too fast’. Just feels sloppy."(Opus 4.7 让我第一次觉得’Anthropic 可能走得太快了’。就是感觉草率。)
分裂的原因
官方测试的维度和用户实际使用的维度不是一回事。
Anthropic 强调"诚实度"和"幻觉率”,这些是安全性指标。用户关心的是能不能把活干好,这是功能性指标。
一个模型可以在"拒绝回答错误前提"上得分更高,但同时变得更固执、更不愿意顺着用户的思路工作。从安全角度看这是进步,从用户体验角度看可能是倒退。
测试环境与实际使用也存在差异。Anthropic 的基准测试在理想条件下进行,用户的实际场景千差万别——长上下文、复杂工具调用、多轮对话。标准基准捕捉不到这些场景下的问题。
Mythos 因素
Anthropic 的系统卡反复将 Opus 4.7 与未发布的 Mythos 模型对比。Mythos 在各项指标上都更优秀——Mashable 指出,Mythos 的 MASK 诚实度达到 95.4%,远超 Opus 4.7。
Anthropic 的"旗舰"能力在 Mythos 身上,公开发布的 Opus 4.7 更像是"二等品”。
如果 Anthropic 的研发资源正在向 Mythos 这样的企业级模型倾斜(通过 Project Glasswing 合作伙伴计划提供),公开发布的模型可能会变得"更安全但更无聊”。对普通用户来说,这不是升级。
社区情绪的转折点
Claude 一直被视为"AI 界的良心"——安全第一、透明度高、尊重用户。这种形象正在受到考验。
Opus 4.6 的"推理深度悄悄下降 67%“事件已经让社区信任受损(我们之前写过)。现在 Opus 4.7 的发布,又带来了 token 消耗增加、用户体验下降的问题。
Business Insider 将此称为"The Claude-lash”(Claude 反噬)——这对一个以用户好感度著称的产品来说,是相对罕见的情况。
一位用户在 Anthropic 的官方帖子下留言:“Please open back support for Opus 4.5. 4.6 is unusable and 4.7 eats usage like nuclear reactor."(请重新支持 Opus 4.5。4.6 不可用,4.7 像核反应堆一样吞噬配额。)
这条评论获得了大量点赞。用户怀念的不是一个抽象的"版本号”,而是那种"这个 AI 真的懂我在说什么"的感觉。
Anthropic 的挑战
Anthropic 面临的问题是:如何在安全性和可用性之间找到平衡。
Opus 4.7 的设计方向更强调安全性,降低幻觉、提高诚实度、拒绝危险任务。这对企业客户很重要。但对普通用户来说,如果代价是模型变得"更笨"或"更固执",他们不会认为这是升级。
透明度也是问题。Anthropic 对 tokenizer 变化、基准淘汰、API 行为改变都有文档说明,但这些信息散落在各个地方。普通用户很难完整理解。当他们发现"同样的问题,现在要花更多钱"或"以前能做的,现在做不了"时,自然会觉得被"悄悄降级"。
写在最后
从 Anthropic 的内部指标看——诚实度、幻觉率、安全性——Opus 4.7 可能是进步。但从核心用户的实际体验看——Token 消耗、任务完成度、交互友好性——这可能是回归。
信任才是问题。当官方数据和用户感受持续分裂时,Anthropic 需要的不是"解释为什么我们的数据是对的",而是"理解为什么用户的感受是对的"。
AI 产品最终不是靠基准测试成功,而是靠用户愿意付费使用。
参考来源:
- Mashable: Anthropic says Claude Opus 4.7 has a 92% honesty rate, fewer hallucinations
- Business Insider: The Claude-lash is here — Opus 4.7 is burning through tokens
- Startup Fortune: Anthropic’s Claude Opus 4.7 launch has triggered a wave of community backlash
- Claude API Docs: What’s new in Claude Opus 4.7
- Reddit: Claude Opus 4.7 is a serious regression, not an upgrade
- GitHub Issue: major quality and performance regression