
4 月 24 日,Anthropic 通过 Fortune 和 The Decoder 公开承认了一件事:过去一个多月,Claude Code 持续让用户失望,不是模型能力本身出了问题,而是三次独立的工程变更同时发作,叠加出一场没人预料到的质量崩塌。
这不是 Anthropic 第一次面对用户抱怨,但这次是他们第一次把具体的失误说清楚了。
三个变更,三层伤害
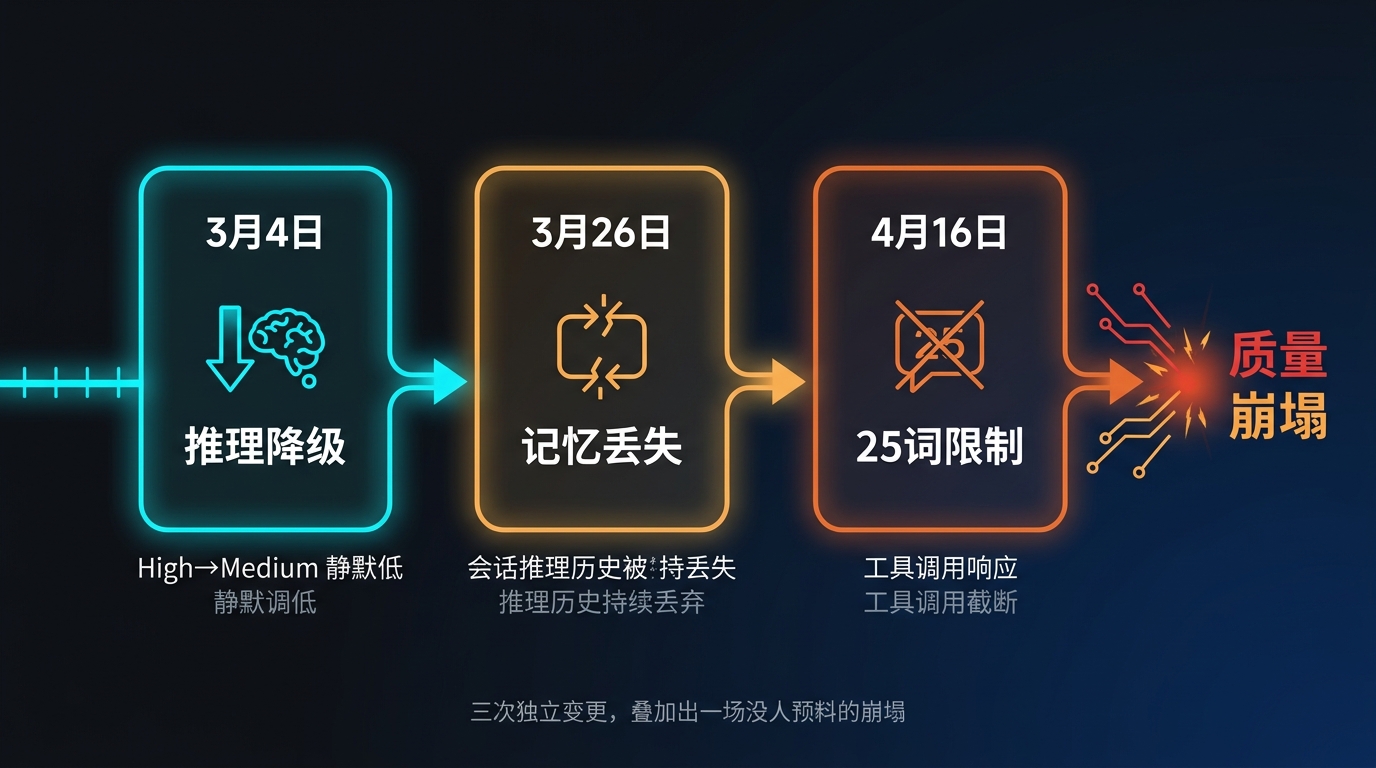
Fortune 的报道还原了时间线。三次变更分散在将近七周内,每一次在当时都是独立的决策,没有人意识到它们叠在一起会是什么效果。
第一次,3 月 4 日:推理强度被悄悄调低。
Anthropic 把 Claude Code 的默认推理努力等级从 high 改为 medium,理由是降低延迟、减少响应时间。这个改动没有公告。用户注意到的是:复杂任务开始出现偷懒,原本能一步解决的问题开始给出"我需要更多信息"的回避答案。Anthropic 后来承认,“这个权衡是错误的”。
第二次,3 月 26 日:一个 bug 让模型开始失忆。
新的 bug 导致模型在同一个会话中持续丢弃自己的推理历史,使响应看起来前后矛盾、反复绕圈。更糟糕的是,这个行为在用掉大量 token 的同时没有产出任何有效结果——用户的配额在静默中被消耗。
第三次,4 月 16 日:每次工具调用之间的回复被限制在 25 个词以内。
这是三个变更中影响最直接可见的一次。Anthropic 在系统提示词里加了一条限制,把工具调用之间的自然语言回复硬性压缩到 25 个词。这个数字在代码协作场景里几乎什么都说不清楚。公司自己后来承认,这"显著伤害了编码质量"。四天后,4 月 20 日,这条限制被撤回。
用户感知到的不是"性能下降",是"被欺骗"
这段时间里,r/ClaudeAI 出现了一篇标题直接的帖子:
“Claude Opus 4.7 is a serious regression, not an upgrade.”
这篇帖子最终获得 3186 个赞、803 条评论,热度几乎与 Anthropic 官方发布 Opus 4.7 的介绍帖持平。
但用户的愤怒不只是因为工具变差了。一位开发者在评论区写道:
“After they gaslit users and pretended nothing was wrong…Anthropic finally admit on the day GPT-5.5 releases there is a problem.”
时机刺眼:Anthropic 公开认错的那天,正好是 OpenAI 发布 GPT-5.5 的同一天,4 月 24 日。不管这是不是巧合,很多用户选择不相信是巧合。
AMD 的一位 AI 高管公开表示,Claude Code 已经"对复杂工程任务不可用"。多名订阅者取消了服务。有安全公司量化了这次崩塌:代码质量下降 47%,Claude Opus 4.7 在测试任务中引入安全漏洞的概率从 51% 升到 52%——而同期 OpenAI 模型的漏洞率约为 30%。
Opus 4.7 的另一面:过度审查的申诉爆炸
与性能问题并行的,是 Opus 4.7 的安全防护机制开始大量误判。
The Register 整理了一批案例,其中有两个尤其离奇:
一是 LSU 网络安全实验室主任,因为向 Claude 提交了包含基础密码学练习的实验室材料而遭到拒绝。他在社交媒体写道:“如果模型被限制到网络安全教育工作者无法使用的程度,这对安全有何帮助?”
二是一名开发者,想让 Claude 处理一份孩之宝《怪物史瑞克》玩具广告 PDF,结果被拒绝。排查后发现触发词是 PDF 内容流里的文本 CHARACTER OR FOR DONKEY UNDERNEATH。
申诉数量的变化更说明问题:2025 年 7 月到 9 月,每月 2—3 起;10 月到 11 月,每月 5—7 起;到 2026 年 4 月,单月超过 30 起,翻了将近 10 倍。
一个有意思的技术细节:根据此前泄露的 Claude Code 源代码,其安全分类器似乎使用了正则表达式做内容检测——只匹配禁用词汇,而不理解上下文。如果这是真的,那个案例就说得通了:DONKEY UNDERNEATH 这个词组对关键词过滤器来说模式高度可疑,哪怕原文不过是玩具说明书里的安装指引。
为什么三个"独立"变更会产生系统性崩塌
这里有一个软件工程里的经典问题,常被称为"变更交互效应"(change interaction effect):每个变更单独测试时都在可接受范围内,但叠加之后,各自的副作用开始互相放大。
具体在这个案例里:
- 推理强度降低(变更一),让模型在面对模糊任务时更容易走捷径;
- 推理历史丢失(变更二),让这种走捷径的行为更难被用户理解和纠正;
- 25 词限制(变更三),让用户甚至无法从 Claude 那里得到足够的信息来判断出了什么问题。
三个变更独立存在时,没有一个会让用户感觉"不可用"。叠在一起,结果是用户在用一个看起来在运行、实际上在糊弄他们的工具。
这不是偶发的 bug,而是缺乏跨系统集成测试和变更影响评估机制的结构性后果。
Anthropic 承诺了什么
公开认错之后,Anthropic 承诺了几件事:在推出任何影响核心用户体验的变更前,引入更严格的质量控制流程;建立跨系统的集成测试机制;对影响性能的隐性变更保持透明。
这些承诺写起来都很容易。
对开发者来说,更有说服力的不是承诺,而是行动:25 词限制在四天内撤回了,这算一个数据点。推理强度是否已经恢复到 high,推理历史的 bug 是否已经修复,官方没有明确说明。
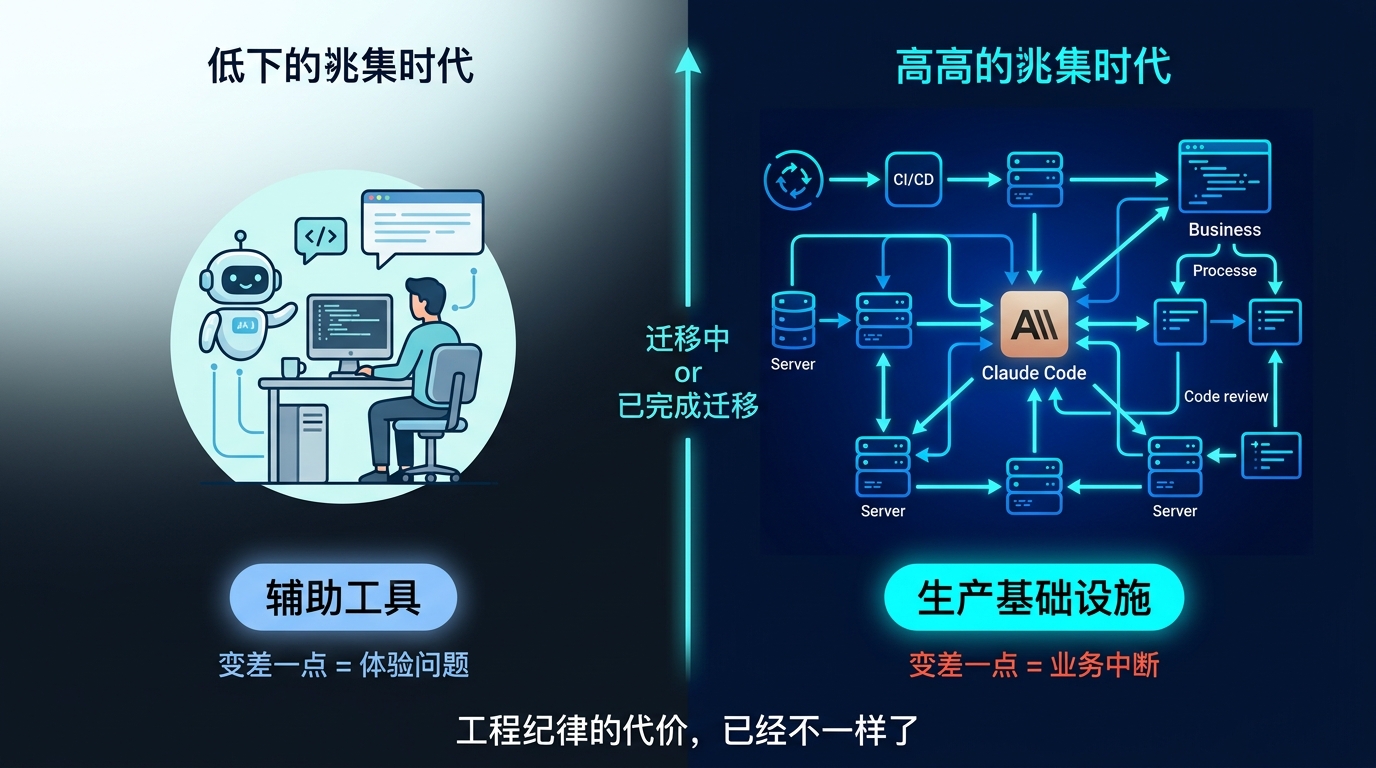
工具变成基础设施之后,工程纪律的代价变了
Claude Code 在过去一年里完成了一个迁移:从"很厉害的 AI 编程助手"变成了很多开发者工作流里的必要环节。当它只是一个辅助工具时,变差一点是体验问题;当它嵌入 CI/CD 流程、成为代码审查链路的一部分,变差一点是业务问题。
这也是 Anthropic 这次压力格外大的原因之一:抱怨最响亮的用户,恰恰是把 Claude Code 用得最深的用户。
传统软件公司对于这种迁移已经有了一套对应的工程文化:功能标志(feature flags)、灰度发布、A/B 实验、回滚机制、变更窗口的协调评审。Anthropic 不是不知道这些,但他们在一个快速扩张的阶段,显然没有把这套文化建设到位。
AI 工具公司普遍面临的一个结构性挑战是:模型行为的变化不像传统代码改动那样边界清晰,更难追踪、更难测试、更容易在组合下产生意外效果。这不是借口,但这是真实的技术难度。
把这件事讲清楚,是 Anthropic 这次认错之后还没有做到的部分。用户知道出了什么问题了,但还不知道 Anthropic 对这个技术难度有没有足够深刻的认识——以及是否已经为此配备了足够的工程资源。
参考来源
- Anthropic explains Claude Code’s recent performance decline after weeks of user backlash — Fortune
- Anthropic confirms Claude Code problems and promises stricter quality controls — The Decoder
- Claude Opus 4.7 has turned into an overzealous query cop — The Register
- Claude is getting worse, according to Claude — The Register
- Anthropic faces user backlash over reported performance issues — Fortune
- AI shrinkflation: Why Anthropic’s Claude Opus 4.7 may be less capable — The New Stack