
最近读到一篇 arXiv 论文,题目很长:Constraint Decay: The Fragility of LLM Agents in Backend Code Generation。它讨论的不是“AI 会不会写代码”这种大问题,而是一个后端工程师更熟悉的麻烦:你给 AI Agent 一堆项目规矩,它能不能在多文件改动里一直守住?
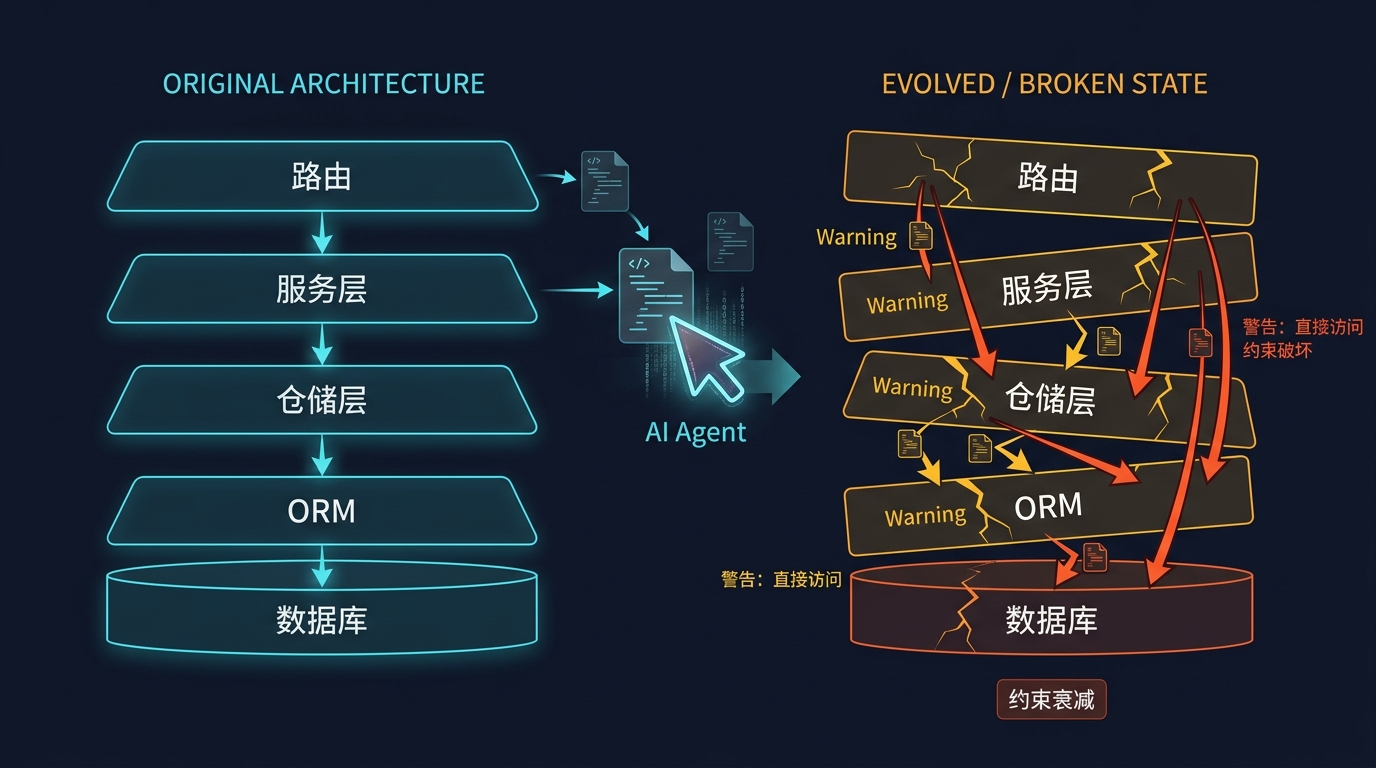
作者做了一个挺朴素、但很有价值的实验。他们固定了一套 API 契约(API contract),准备了 80 个从零生成的任务和 20 个功能迭代任务,覆盖 8 个 Web 框架。验收时不只看接口能不能跑,还用端到端测试和静态检查去看结构有没有被破坏。结果是,约束越多,Agent 掉得越明显。较强的配置从基础任务到完整约束任务,assertion pass rate 平均掉了 30 个百分点;弱一些的配置几乎掉到零。
论文把这个现象叫 constraint decay,约束衰减。
这个词有点学术,但你只要用 Claude Code、Cursor 或其他编程智能体(coding agent)改过一个稍微复杂的后端项目,就大概知道它在说什么:代码能跑,测试也许还绿,但项目的形状开始变了。
能跑,不等于写对
现在的 AI 编程工具很擅长把模糊需求变成演示项目(demo)。你说“帮我做一个用户登录接口”,它很快就能补路由(route)、控制器(controller)、模型(model)、数据库查询,甚至顺手加测试。
如果验收标准只是“接口返回 200”,这事看起来已经结束了。
但真实项目不会只问返回码。它还会追问:这段逻辑该不该放在 controller?有没有绕过 service 层?查询有没有经过统一的权限过滤?ORM 关系是不是只在简单数据下碰巧没炸?为了当前接口跑通,它有没有顺手改掉别的模块依赖的结构?
这些问题通常不会第一时间报错。它们更像裂缝。第一天只是代码有点别扭,第三天开始测试难写,第三周以后你发现每加一个功能都要绕开前面留下的结构债。
这也是这篇论文切中的地方。很多基准测试(benchmark)会奖励“功能正确但结构随意”的答案。论文摘要里的说法是:功能上正确、结构上任意的解法(functionally correct but structurally arbitrary solutions)。翻成工程现场的话,就是:我们一直在奖励 AI 写能跑的野路子。
后端的问题会被放大
前端当然也会被 AI 写乱,但后端更容易把这种混乱放大。
一个接口表面上只是接收参数、查询数据、返回 JSON,背后却牵着数据库模式(schema)、对象关系映射(ORM)、事务边界、权限模型、错误处理、依赖注入、迁移文件和框架生命周期。很多关键约束不在需求文字里,也不在当前文件里,而是散在项目习惯和历史代码里。
论文的错误分析(error analysis)里提到,主要问题之一是数据层缺陷(data-layer defects),包括查询组合错误(incorrect query composition)和对象关系映射运行时违规(ORM runtime violations)。这个判断很贴近实际。Agent 往往不是不会写 SQL,也不是不知道 ORM 怎么用,而是对不齐项目已有的模型关系、查询入口和框架约定。
比如你让它给订单系统加一个“按用户筛选订单”的接口。它看到 Order model 里有 user_id,于是写出:
|
|
这段代码可能能跑。问题是,项目里原本可能要求所有订单查询必须经过 OrderRepository,因为里面封装了租户隔离、软删除过滤、权限范围和审计日志。Agent 可能没读到那部分,也可能读到了但在后续修补里忘了。最后表现出来的是:功能通过,边界破坏。
这种破坏还不容易被普通单元测试抓住。你测“给 user_id 能不能返回订单”,它通过了。可你没测“有没有绕过租户隔离”。等真正出问题时,已经不是一个接口的 bug(缺陷),而是项目约束被穿了一个洞。
框架越有默契,Agent 越容易踩空
论文里还有个发现:Agent 在极简、显式(minimal、explicit)的框架里表现更好,比如 Flask;在重约定(convention-heavy)的环境里表现差得多,比如 FastAPI、Django。
这很合理。显式框架把事情摆在明面上,文件在哪里,函数怎么接,依赖怎么传,代码通常比较直接。Agent 读到相邻文件后,比较容易照着模式写下去。
约定型框架就麻烦些。很多规则藏在命名、目录、配置、装饰器、生命周期和社区惯例里。Django 的模型(model)、管理器(manager)、迁移(migration)、管理后台(admin)、序列化器(serializer)、视图集(viewset)之间有一整套默认假设。FastAPI 项目也经常把依赖注入(dependency injection)、Pydantic 模式(schema)、路由器(router)分组和服务层(service layer)组织成内部规范。
人类开发者进项目后,会慢慢形成“这里应该这么写”的手感。Agent 更容易被最近读到的几个文件带偏。它可能在 A 模块模仿得不错,到了 B 模块因为上下文挤压、文件没读全,或者目标被“尽快修好测试”绑架,就开始用自己熟悉的通用写法补洞。
我见过的典型过程是这样的:第一轮生成还像原项目;第二轮修 bug(缺陷),开始加局部 hack(临时补丁);第三轮扩功能,文件边界松了;第四轮再让它修测试,它为了过测试去碰更底层的结构。
这不一定是模型突然变笨。更像是当前任务的压力逐渐盖过了项目规则。Agent 追着“把这次需求完成”跑,架构约束在一次次局部修补里被磨掉。
Prompt 只能提醒,不能兜底
很多人的第一反应是:那我把规则写清楚一点不就好了?
确实有用。你应该告诉 Agent:不要绕过服务层(service layer),不要直接改数据库模式(schema),不要新增全局状态,不要在控制器(controller)里写业务逻辑。但只靠提示词(prompt),很快会遇到麻烦。
一个麻烦是目标冲突。你同时要求它保持架构一致、不要大改、修复所有测试、尽快完成需求。真冲突时,Agent 往往会选最容易被验证的目标:测试绿了,接口跑了。
另一个麻烦是可见性。规则写在 prompt 里,不代表它每一步编辑都能正确应用到当前文件。长任务里,它可能没有读到关键文件,也可能没有意识到某个局部改动已经违反项目级约束。
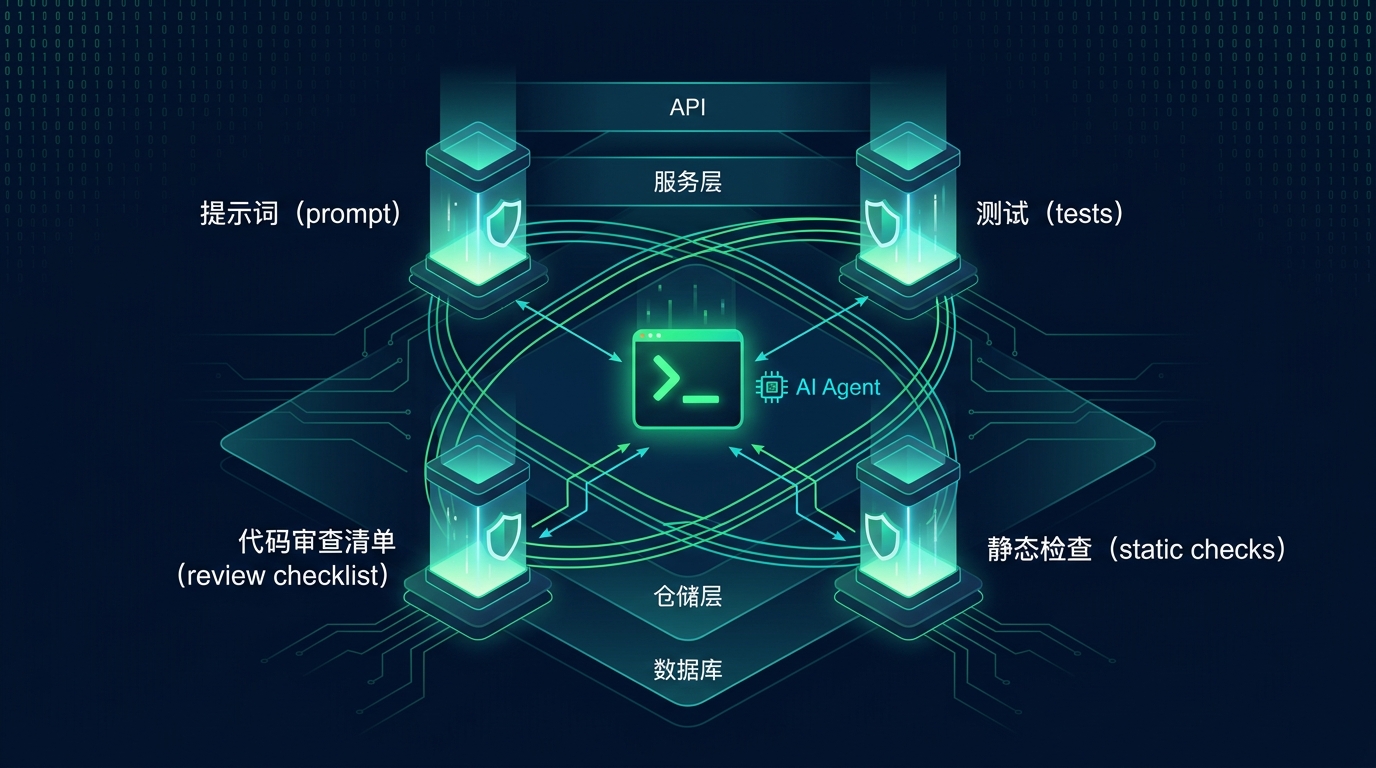
所以 prompt 只是意图,不是边界。更靠谱的做法,是把一部分规矩变成机器能检查的东西。
比如控制器(controller)不能直接访问对象关系映射(ORM),就用代码检查(lint)或脚本拦住。Agent 有没有偷偷改数据库结构,就看数据库模式差异(schema diff)。模块之间不能反向导入(import),就写架构测试。API 契约(API contract)不能动,就用静态检查和契约测试(contract test)。数据库行为不能只靠模拟对象(mock),就跑真实集成测试。
这些东西不一定要很复杂。关键是要在 Agent 完成任务后立刻跑,而不是几天后人工 review 才发现风格已经跑偏。
在 AI coding 里,prompt 像任务说明,verifier 才像门禁。
我会怎么改 Claude Code 工作流
如果你平时用 Claude Code 写后端,这篇论文不是在说“别用 Agent”。它更像是在提醒:别把 Agent 当成一个天然理解项目边界的同事。
它更接近一个执行力很强的外包工程师。给它自由度太大,它就可能在你看不见的地方做局部最优。
我的做法会保守一点。
先让它读结构,不急着写代码。让它说清楚控制器(controller)、服务层(service)、仓储层(repository)的边界,数据库访问集中在哪里,新增功能应该落在哪几个文件。如果这一步答不清,后面写得越快越危险。
然后把任务拆小。不要让它“一次实现完整订单管理模块”。先补数据库模式(schema),再补服务层(service),再补路由(route),再补测试。每一步都看代码差异(diff),避免一个大补丁里混进结构漂移。
还要给少量硬禁止项。比如不要修改迁移文件(migration)以外的数据库模式定义(schema),不要在路由(route)里直接查询对象关系映射(query ORM),不要新增跨层导入(import)。禁止项不用多,太多反而会被稀释,但关键边界要硬。
最后,检查重点要换一下。不要只看这段代码能不能运行,要看它有没有改变项目的写法。AI 生成代码的语法问题会越来越少,真正该盯的是边界、职责和长期维护成本。
这套流程看起来比直接聊天慢。可后端工程里的快,不是第一次生成用了几秒,而是三周后你还能不能安全改第二个需求。
这篇论文补上了缺的一块
过去一年,AI coding 的讨论很容易走向两个极端。
一种说法是模型越来越强,代码越来越快,未来人人都能做软件。另一种说法是 AI 代码全是垃圾,真正工程还得人写。
Constraint Decay 给了一个更具体的判断:AI Agent 不是不会写后端,它是在结构约束累积时开始掉队。这个问题不一定靠更长上下文就能解决,也不一定靠更顺滑的聊天界面就能掩盖。
后端开发本来就是约束密集型工作。一个成熟项目的价值,不只在功能列表里,也在那些看起来无聊的规矩里:哪些层可以互相调用,哪些数据只能通过统一入口访问,哪些异常必须被包装,哪些迁移必须可回滚,哪些 API 契约(API contract) 不能破坏。
人类工程师花很多年学会的,其实就是在功能压力下仍然守住这些规矩。
AI Agent 现在最容易做到的是把功能补上。它还不稳定的是:补功能时不破坏系统的形状。
所以我不觉得这篇论文是在唱衰 AI 编程。它是在把问题说得更准:代码生成变便宜以后,工程约束会变得更贵。
以后评价一个 Coding Agent,不能只问它能不能写出功能。还要问:当项目规则越来越多、文件越来越多、框架约定越来越重时,它还能不能守规矩。
如果答案不确定,就别把规矩只写在提示词(prompt)里。把它写进测试,写进静态检查,写进代码审查清单(review checklist),写进每一次小步提交。
这不是保守。想让 AI 真正进生产环境,这些东西迟早要补上。