
过去几个月,Agent 执行框架这个词突然变得很热。
这不只是因为大家又发明了一个新术语。更直接的原因是,AI 编程工具已经走到一个新阶段:模型不只是帮你补全代码,也不只是回答“这个 bug 该怎么修”,而是开始真的读仓库、跑命令、开浏览器、写测试、提 PR,甚至在你睡觉时连续工作几个小时。
一旦 AI 能行动,问题就变了。
以前我们关心的是:模型会不会写代码。现在更值得问的是:它在什么系统里写代码?谁给它目标?谁给它边界?谁检查它有没有真的完成?
OpenAI 最近发布了一篇工程文章,标题是《Harness engineering: leveraging Codex in an agent-first world》。里面讲了一个相当激进的实验:他们用 Codex 从一个空仓库开始,构建并发布了一个内部 beta 软件产品,而且按文章说法,所有应用逻辑、测试、CI 配置、文档、可观测性和内部工具,都是 Codex 写的。OpenAI 估算,这个项目大约用 1/10 的时间完成;五个月后,仓库已经接近百万行代码,期间合并了约 1500 个 PR。
另一边,Anthropic 在 6 月 2 日发布了 Claude Code 的 Dynamic Workflows(动态工作流)。文章开头就说,Claude Code 现在可以“on the fly”写出自己的多智能体执行框架,为当前任务定制工作流。它不是固定流程模板,而是让 Claude 根据任务需要生成一段 JavaScript 工作流,协调多个子智能体、做并行分发、做验证、做筛选,必要时还可以为不同子任务选择模型和工作树隔离方式。
两家公司都在讲执行框架,但它们讲的其实不是同一件事。
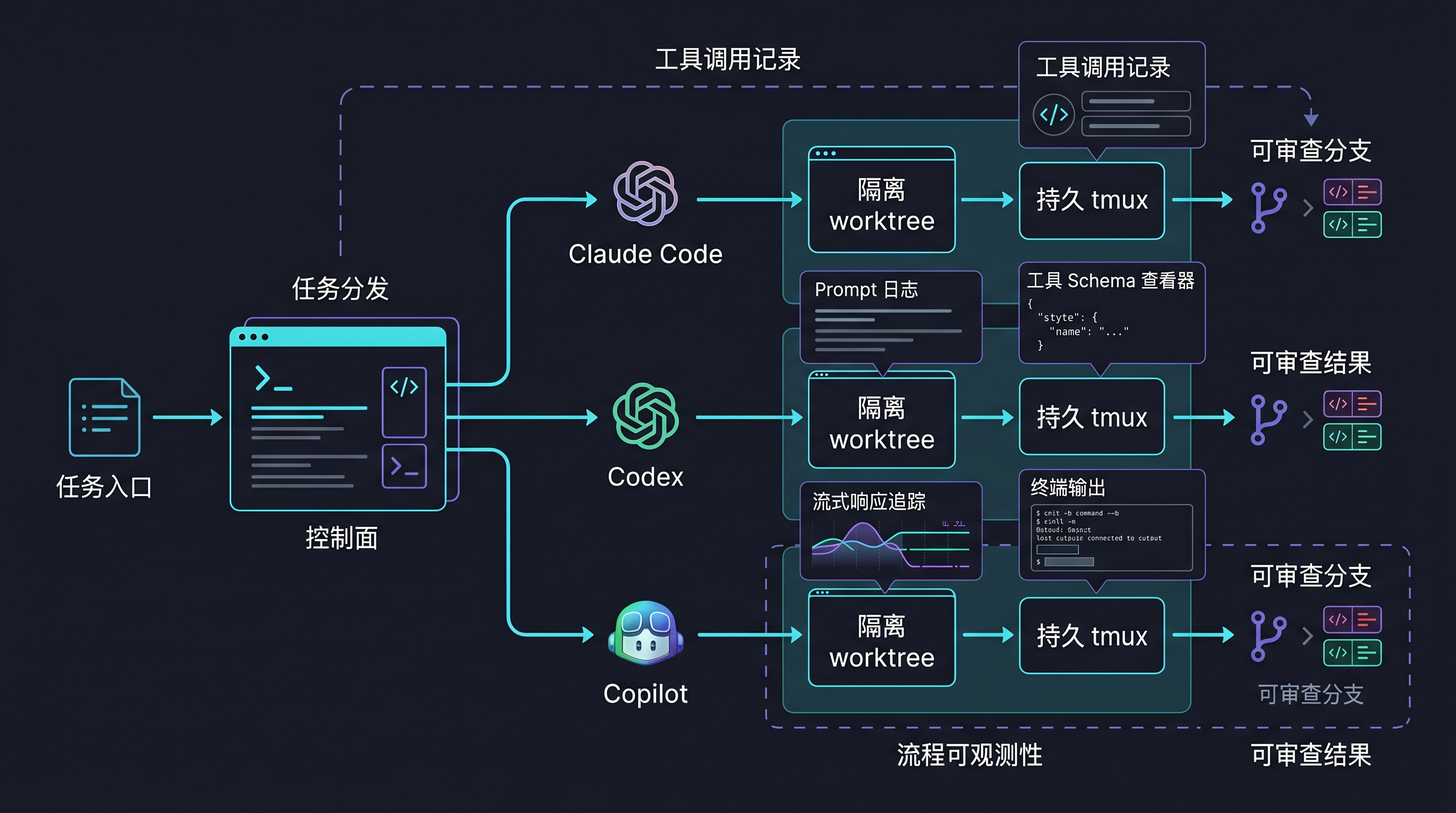
而且这不是两个官方博客之间的抽象路线之争。Twitter/X 上这两天围绕编程智能体的讨论,已经把问题说得更直白:有人把 Claude Code、Codex 和 Copilot 并行跑在隔离 worktree 和 tmux session 里,称编程智能体需要一个控制面;也有人发布 claude-tap 这类本地代理工具,专门检查 AI 编程智能体的提示词、工具结构定义和流式响应。换句话说,开发者社区已经不满足于“让模型写代码”,而是在追问:这个会行动的模型到底被谁调度、被谁观察、被谁约束。
两家公司都在讲执行框架,但它们讲的其实不是同一件事。
OpenAI 更像是在说:当 Codex 成为主力开发者,人类工程师要把仓库、文档、工具、验证、架构约束都变成 Codex 能读懂、能执行、能持续维护的工程脚手架。
Anthropic 更像是在说:当 Claude Code 遇到长程、并行、对抗性、结构化任务时,不要把所有事情塞进一个上下文窗口,而是让 Claude 临时生成一个更适合当前问题的执行系统。
一个偏“把组织流程和仓库结构标准化”,一个偏“让模型动态编排任务”。这条分叉,可能会决定未来 AI 编程工具到底长什么样。

OpenAI 的路线:先把仓库变成 Agent 能工作的环境
OpenAI 那篇文章里,最关键的一句话不是“0 行人工写代码”,而是:Humans steer. Agents execute.
这句话很容易被理解成“人类不写代码了”。但文章真正讨论的,是人类工程师的工作重心发生了变化。
在这个项目里,人类不再直接写代码,而是设计环境、指定意图、建立反馈回路,让 Codex 智能体能可靠工作。文章提到,早期进展慢,不是因为 Codex 写不了,而是因为环境“定义不足”。Agent 缺少必要的工具、抽象和内部结构,没法从高层目标稳定推进。
这很像给一个新同事搭建入职系统。你不能只告诉他“把产品做出来”,然后等他自己摸索。你要给他仓库结构、架构图、规范、测试、工具链、日志入口、代码评审方式,还要告诉他哪些东西能碰,哪些东西不能碰。
OpenAI 的做法有几个很鲜明的特点。
第一,它把仓库知识变成权威记录系统。
文章里说,他们尝试过“一个巨大的 AGENTS.md”,后来发现这种方式会失败。原因很直观:上下文是稀缺资源,所有东西都写进一个大文件,反而会让 Agent 迷路;规则太多等于没有规则;文档很快腐烂;也不容易机械验证。
所以他们把 AGENTS.md 做成目录,而不是百科全书。真正的知识放在结构化的 docs 目录里,包括设计文档、执行计划、产品规格、架构文件、质量评分、可靠性要求等。Agent 从一个短入口开始,再按需进入更深的资料。
这其实是给 Agent 做“渐进式披露”。
人类新人也不适合第一天读完公司所有文档。更好的方式是先知道地图在哪里,再根据任务找对应资料。对 Agent 也一样。
第二,它强调应用可读性和智能体可读性。
OpenAI 让 Codex 能启动每个 worktree 里的应用实例,用 Chrome DevTools Protocol 观察 DOM、截图和导航;也给它接入本地可观测性栈,让它能查日志、指标和追踪记录。这样,“确保服务启动低于 800ms”或“这四条关键路径里没有调用片段超过 2 秒”就不再是抽象要求,而是 Agent 可以直接验证的任务。
这一步很重要。
很多 AI 编程失败,不是代码语法错了,而是 Agent 只能在想象里验证结果。它觉得页面能用,实际按钮没反应;它觉得接口修好了,真实链路还有鉴权问题;它觉得性能改善了,但没有读到指标。
OpenAI 的路线是把真实反馈接进 Codex 能理解的环境里。
这也解释了为什么社区会开始讨论编程智能体的控制面。一个 Agent 能同时读仓库、改文件、开浏览器、跑测试,听起来很强;但如果没有统一的任务入口、隔离的执行环境、可追踪的 session、可审查的分支和可复盘的工具调用记录,它越强,系统越难管理。所谓执行框架,不只是让 Agent 有工具,而是让人类能看见 Agent 如何使用这些工具。
第三,它用机械规则约束架构和工程品味。
文章里提到,他们通过自定义代码检查器 和结构测试,限制业务域里的依赖方向,要求边界解析数据形状,检查结构化日志、命名约定、文件大小限制和可靠性要求。更有意思的是,代码检查器的错误消息会写成能给 Agent 直接修复提示的形式。
这不是人类团队里那种“代码风格建议”。对 Agent 来说,这些规则是硬边界。它们把人类的工程品味 和架构判断编码到系统里,让 Agent 不必每次都重新猜。
所以 OpenAI 这条路线的核心不是“Codex 更聪明了”,而是“仓库被改造成了 Codex 能连续工作的场地”。
它的执行框架更像一个组织级工程控制系统:文档是地图,工具是手脚,代码检查和测试是边界,日志和浏览器是感知,PR 和评审是反馈循环。
Anthropic 的路线:让 Claude 临时生成适合任务的执行框架
Anthropic 的 Dynamic Workflows(动态工作流)文章,关注点不太一样。
它承认默认 Claude Code 执行框架对很多编码任务已经很好用。但当任务变得很长、需要大量并行、需要结构化处理,或者需要对抗性验证时,单一上下文窗口会暴露几个问题。
文章列了三个典型失败模式:智能体懒惰、自我偏好偏差、目标漂移。
换成人话,就是:Claude 做到一半可能提前宣布完成;它可能偏爱自己刚刚得出的结论;任务跑太久以后,最初目标会在上下文压缩和多轮执行里慢慢变形。
这些问题很像人类长时间工作时的疲劳和偏见。区别在于,人类团队可以分工:有人写,有人审,有人质疑,有人整合。Anthropic 的 Dynamic Workflows(动态工作流),就是把这种分工结构交给 Claude 去临时搭建。
它的机制也很清楚:工作流执行一段 JavaScript 文件,里面有特殊函数可以启动并协调子智能体。每个子智能体有自己的上下文窗口,可以针对一个更小、更干净的目标工作。工作流本身负责流水线、并行、同步关卡、验证、多方案竞赛 这些结构。
文章给出的常见模式很有代表性。
比如“并行分发并汇总”:把任务拆成很多小块,每块交给一个智能体,再统一合成。
比如 对抗式验证:一个智能体得出结论后,另一个智能体 专门负责反驳或验证。
比如 生成再筛选:先生成多个候选,再按 评估标准 筛掉低质量结果。
比如 多方案竞赛:多个智能体用不同方法尝试同一任务,再通过评审选出最好的。
这些模式本质上不是“多叫几个 AI 来干活”。如果只是多开几个 Agent,成本更高,混乱也更大。真正有价值的是:工作流把任务结构、验证顺序和停止条件显式化了。
这就是 Anthropic 路线和 OpenAI 路线的差异。
OpenAI 更像是在仓库和组织流程里提前固化一套长期执行框架。Anthropic 则把 执行框架的一部分生成权交给模型:遇到复杂任务时,Claude 可以先判断该用什么结构,再写出一个临时执行系统。
这和 Claude Code 的产品气质是一致的。
Claude Code 一直不只是 IDE 插件,而更像一个命令行里的工程搭档。Dynamic Workflows(动态工作流) 进一步把它从“执行一个计划”推进到“设计一个执行系统”。当你说“用工作流找出过去 50 次会话里我反复纠正的问题,并把它们沉淀成 CLAUDE.md 规则”,它不只是搜索日志,而是可以创建分类智能体、聚类智能体、验证智能体、规则生成智能体,然后把结果合并。
它的优势在于适应性。
你不需要提前为所有任务写好工作流。Claude 可以根据任务现场生成一个。对研究、代码迁移、深度验证、批量排序、故障根因分析这类问题,这种动态结构很自然。
它的风险也在这里。
动态生成工作流往往更费 token,更难预测,也更依赖模型自己判断“这个任务值不值得动用更多计算”。Anthropic 文章也提醒,Dynamic Workflows(动态工作流) 不适合所有任务。普通编码任务不一定需要 5 个审查者,也不一定需要多方案竞赛。
这不是日常默认模式,更像高价值复杂任务的加速器。
有意思的是,swyx 最近在 X 上提到一个比“always use plan mode”更聪明的做法:不要只是命令模型执行,而是把任务框成一个问题,让模型先反驳、评分、提出替代方案,再决定怎么做。这个说法和 Dynamic Workflows(动态工作流) 的精神很接近。真正重要的不是多一个“计划模式”按钮,而是让 Agent 先判断任务结构:这件事需要线性执行,还是需要并行探索?需要一个审查者,还是需要多个互相独立的验证者?需要直接改代码,还是应该先定义验证标准?
所以 Anthropic 的路线并不只是“多 Agent”。它更像把任务设计本身也交给模型参与,让模型在执行前先选择合适的组织形态。
两条路线的真正分歧:谁来设计执行系统
如果把两篇文章放在一起看,会发现它们其实在争同一个问题:Agent 时代,到底谁来设计执行系统?
OpenAI 的答案更偏工程组织。
人类把知识库整理好,把架构边界写清楚,把代码检查器和测试建好,把应用、日志、指标暴露给 Codex。Codex 在这个系统里高速执行。人类的工作不是一行行写代码,而是在更高层次上设计约束、指定目标、维护反馈回路。
这条路线像平台工程。
它假设一个团队愿意长期投资,把自己的仓库改造成 Agent 友好的环境。投入越多,Codex 越能长期稳定产出。它适合内部产品、大型代码库、企业级软件团队,也适合那些愿意把 Agent 当成“新工程团队成员”来建设基础设施的组织。
Anthropic 的答案更偏任务现场。
默认执行框架解决大多数任务;当任务超出单窗口能力时,Claude 自己写工作流,临时组织子智能体,用结构化模式对抗懒惰、偏见和目标漂移。人类不用提前设计所有流程,只要给出目标和约束,让 Claude 在运行时选择合适的编排方式。
这条路线像自适应执行器。
它适合一次性复杂任务、研究、审计、迁移、验证和探索。你不一定有长期平台投资,也不一定知道任务结构该怎么拆。你让 Claude 先想清楚“怎么干”,再让它调度多个智能体 去干。
这两条路线没有绝对优劣。
OpenAI 的路线更稳,但前期投入高。你要维护文档系统、代码检查、可观测性、结构化规范、评审流程。它像把 AI 编程纳入工程组织的日常生产系统。
Anthropic 的路线更灵活,但更依赖模型临场判断。它可以快速适配新问题,也可能在不必要的时候过度编排。它像给高级开发者一个可以随手搭建任务流水线的工具箱。
如果用一句话概括:
OpenAI 在问:“怎样把我们的软件工程组织改造成 Codex 能持续工作的系统?”
Anthropic 在问:“怎样让 Claude 针对当前任务临时生成一个足够好的工作系统?”
这对普通开发者意味着什么
这里还要加一个现实问题:权限边界。
如果说 OpenAI 和 Anthropic 的官方文章更关注“怎样让 Agent 更有效地完成任务”,那开发者社区补上的另一半问题是:怎样让它不要越界。Simon Willison 最近连续提到两个很有代表性的点:一是他在寻找 沙箱中的 Python 方案,用 WebAssembly 里的 MicroPython 在 Python 应用中安全运行代码;二是他提醒,大多数人都不会把购买权限交给任何附着在 LLM 上的东西。
这两件事其实都在说同一个原则:Agent 不是普通函数调用,它是带有判断能力的行动者,所以它需要比普通自动化脚本更清晰的权限设计。
让 Agent 改一个测试文件、查询一段日志、打开一个浏览器页面,和让它删除数据库、购买服务、发起链上交易,不是同一种风险。前者是工程生产力,后者已经接近经营权限。最近围绕 MCP 的讨论也在往这个方向走:当 Base MCP 这类网关让 Claude 或 ChatGPT 能从聊天界面触发 DeFi 动作时,“不持有私钥”只是第一层保护,更关键的是谁定义动作白名单、谁审批高风险操作、谁记录审计链路。
所以对普通开发者来说,执行框架不只是效率工具,也是一套安全边界。
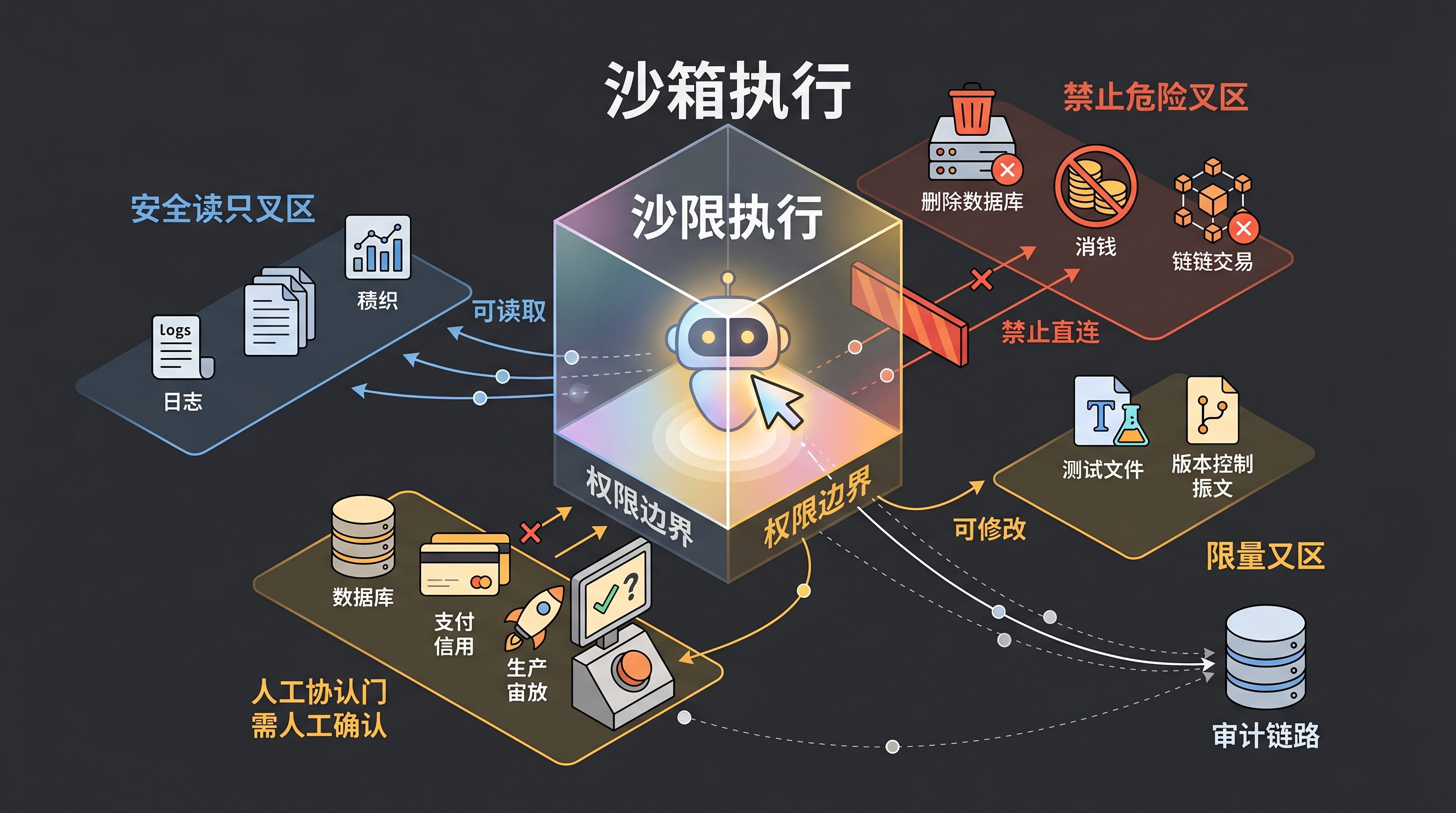
你不需要一开始就搭完整平台,但至少要想清楚三件事:
- Agent 可以读什么?
- Agent 可以改什么?
- Agent 做到什么程度必须停下来问人?
这三个问题,比“用哪个模型”更基础。
很多开发者看完这类文章,容易得出一个很吓人的结论:未来是不是必须搭一整套 Agent 平台,才能继续写代码?
我觉得没必要这么焦虑。
对个人开发者和小团队来说,更实际的做法不是照搬 OpenAI 的百万行 智能体生成的代码库,也不是每个任务都让 Claude 写工作流。更好的起点,是先区分两类场景。
第一类是重复出现的任务。
比如你的项目每次改 API 都要更新文档、跑测试、检查类型、生成 changelog;每次写文章都要查资料、做事实核验、转微信公众号 HTML;每次发布前都要检查 frontmatter、图片路径、Hugo 构建。
这种任务更适合 OpenAI 式思路:把流程固化下来。写 CLAUDE.md,写脚本,写检查清单,做 hooks,做技能,做发布前检查。不要每次都靠“请你认真一点”。把反复出现的失败,变成流程资产。
第二类是一次性复杂任务。
比如迁移一个大仓库、审计一批 PR、验证一篇长文所有技术断言、从 80 个候选里筛出最好的 10 个、分析一次故障的多种根因。
这种任务更适合 Anthropic 式思路:不要让一个 Agent 在一个上下文窗口里硬扛到底。让它 并行分发,让它生成假设,让不同 agent 独立验证,让最后的汇总步骤负责合并。这里 工作流的价值会比普通 提示词 大得多。
真正重要的不是选择 OpenAI 还是 Anthropic,而是不要再把 AI 编程理解成“给模型一句话,然后等结果”。
只要 Agent 开始行动,它就需要执行系统。
这个系统可以很小:一个测试命令,一个不允许删库的权限规则,一个发布前检查脚本,一个 README 里的项目地图。
也可以很大:多智能体工作流、工作树隔离、结构化文档、可观测性栈、自动评审、持续垃圾回收。
这里的关键不是技术名词,而是控制面。一个成熟的 智能体工作环境,至少应该回答四个问题:任务如何分配,执行如何隔离,过程如何观察,结果如何验证。没有这些,Agent 越能干,越像一个高权限黑盒。
规模不同,本质一样:让 Agent 在现实反馈里工作,而不是在语言自洽里工作。
真正的变化:代码不再是唯一产物
OpenAI 那篇文章里有个细节值得多想一下。
当他们说“所有代码都是 Codex 写的”时,列出来的不只是产品代码,还包括测试、CI、文档、可观测性、内部工具、评估框架、评审意见和生产仪表盘定义。
这说明 Agent 时代的软件产物边界会变宽。
过去开发者最重要的交付物是代码。文档、测试、脚本、规范、日志入口,经常被当成配套物。到了 Agent 时代,这些配套物反而变成主战场。
因为它们决定 Agent 能不能理解系统、能不能验证自己、能不能继承过去的经验。
一份好的架构文档,不只是给新人看的,也是给 Agent 看的。一条好的 代码检查错误,不只是提示人类改格式,也是把修复路径注入 Agent 上下文。一套好的测试,不只是防止回归,也是让 Agent 知道自己什么时候真的完成。
这也解释了为什么“AI 写了多少代码”这个指标越来越没意思。
如果一个 Agent 写了 5000 行代码,但没有测试、没有边界、没有验证、没有回滚,它可能只是制造了更多技术债。相反,一个 Agent 只改了 50 行代码,但同时补齐了测试、文档和规则,让以后同类问题不会再发生,这才是更高质量的产出。
未来工程师的价值,可能会更多体现在这些地方:
你能不能把隐性经验写成 Agent 可执行的规则?
你能不能把失败模式变成自动检查?
你能不能设计一个工作流,让多个智能体 互相质疑,而不是一起自信犯错?
你能不能判断什么时候该让 Agent 自主跑,什么时候必须停下来问人?
这些问题,比“会不会写 提示词”更接近真正的 AI 工程。
结尾:执行框架是 AI 编程从演示走向生产的分水岭
如果说 2023 年的关键词是 提示词,2025 年的关键词是 上下文,那么 2026 年的关键词很可能就是 执行框架。
提示词解决的是怎么和模型说话。
上下文解决的是给模型看什么。
执行框架解决的是:当模型开始行动,它如何被约束、验证、纠偏和复用。
OpenAI 和 Anthropic 的分歧,表面上是 Codex 和 Claude Code 的产品路线不同。深一点看,是两种 Agent 工程哲学。
社区讨论把这个分歧又往前推了一步:无论你选择哪种路线,最后都绕不开同一组基础设施问题。你需要控制面来分配任务,需要可观测性来看见 提示词、工具结构定义和流式响应,需要沙箱来限制执行环境,需要权限边界来决定哪些动作必须人工确认。
没有这些东西,Agent 只是一个更会写代码的黑盒。有了这些东西,Agent 才可能成为工程系统的一部分。
一种相信长期工程化:把仓库、文档、工具、测试、观测和规则都改造成 Agent 能稳定工作的环境。
另一种相信动态编排:让模型根据任务现场生成适合当下的多智能体工作流,用并行、验证、竞赛和循环来克服单一上下文的局限。
我不觉得最后只会剩一种路线。
日常生产需要 OpenAI 式的稳定脚手架。高价值复杂任务需要 Anthropic 式的动态编排。真正成熟的团队,可能会同时拥有两者:平时靠固定流程保障质量,遇到复杂问题时再让 Agent 临时搭一个更强的执行系统。
这也是 执行框架这个词值得关注的原因。
它提醒我们,AI 编程的下一阶段,不是简单地让模型更会写代码,而是让整个工程系统更适合 AI 参与。
代码会越来越容易生成。
真正稀缺的,会是那套让生成结果可靠落地的系统。
参考来源
- OpenAI: Harness engineering: leveraging Codex in an agent-first world
- Anthropic: A harness for every task: dynamic workflows in Claude Code
- OpenAI: Codex for every role, tool, and workflow
- Twitter/X: Anthropic 发布 Making Claude a chemist
- Twitter/X: OpenAI 账号误封与订阅 credit 问题说明
- Twitter/X: Simon Willison 关于 AI coding 与工程经验的讨论
- Twitter/X: Simon Willison 的 MicroPython in WebAssembly 沙箱实验
- Twitter/X: Simon Willison 关于不要给 LLM 智能体 购买权限的提醒
- Twitter/X: swyx 关于把任务框成问题而非盲目执行的建议
- Twitter/X: 编程智能体需要控制面 的讨论
- Twitter/X: claude-tap 观察 提示词 / 工具结构定义 / 流式响应 的工具线索
- Twitter/X: Base MCP 让 AI 智能体执行链上 DeFi 动作的线索