
6 月 27 日,DeepSeek 把一份叫 DSpark 的论文丢进 GitHub 仓库
deepseek-ai/DeepSpec,Hacker News 上对应帖子很快冲到 700 多分。配套的还有 MIT 协议的训练代码和两组直接能用的权重。本文是对论文和几篇公开解读的二次整理,数字以论文与官方口径为准,我没有独立复现。
先说结论:它解决的是一道老选择题
投机解码(speculative decoding)这个词,简单说就是让一个小模型先"猜"几个 token,大模型再一次性验证,猜对的就白赚,猜错就回退。猜得好,推理就快;猜得差,等于白干。这套做法在学术圈火了两三年,一直卡在一个尴尬的取舍上:
- 想猜得准,就得让小模型一个个 token 往下递推,像 Eagle3 那样。准是真准,可猜的成本会随块长越滚越大。
- 想猜得快,就得让小模型一次性并行吐出整块 token,像 DFlash 那样。快是真快,可每个位置都"各猜各的",越到块尾接受率掉得越狠。
一句话,快的不准,准的不快。DSpark 想做的,就是把这道二选一拆掉。
它给出的答案是:两种都要。一个并行骨架负责快,一个极轻的串行小头负责准。再叠一层会"看 GPU 脸色"的调度器,决定每次到底验证几个 token。论文称,在 DeepSeek-V4 的真实流量上,等吞吐条件下每个用户的生成速度比之前的 MTP-1 基线快了 60–85%,而且输出无损。
需要先点明一句:DSpark 不是新模型,是服务端优化(serving optimization)。它复用 DeepSeek-V4 现成的权重,只在前面外挂一个草稿模块(draft module)。所以它不改变模型本身的能力,只改变 token 是怎么被吐出来的。
投机解码的底层账本
要理解 DSpark 为什么这么设计,得先看清这笔账。
投机解码里有两个角色:草稿模型(draft model)和目标模型(target model)。草稿模型先一口气提出一整块 token,目标模型再对这些 token 做一次前向验证。验证用一种叫拒绝采样(rejection sampling)的规则,接受最长那段合法前缀,再额外补一个 token。因为这套规则在数学上精确保持目标分布,所以理论上质量不掉,只是速度可能变快也可能变白干。
每个 token 的延迟,论文给了一个很干净的公式:
|
|
T_draft 是草稿耗时,T_verify 是验证耗时,τ 是每个周期里被接受的 token 数。想让 L 变小,只有三个杠杆:让草稿更快(降 T_draft)、让草稿更准(升 τ)、让验证更聪明(少在注定被拒的 token 上浪费 T_verify)。
过去的方法基本只拉其中一两个杠杆。DSpark 的特别之处在于,它把三个都拉了。
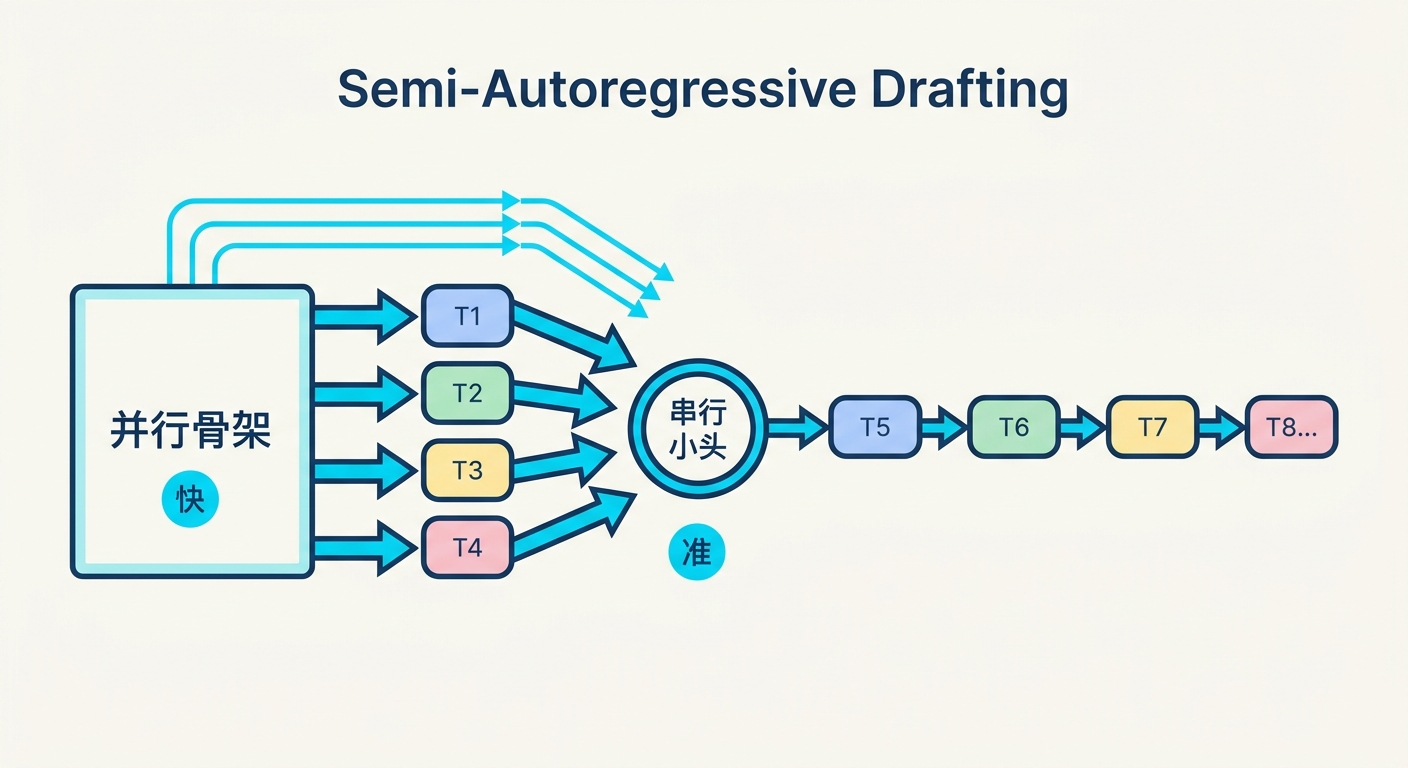
第一招:半自回归,把快和准缝在一起
DSpark 的草稿生成分两步走。
第一步,用一个并行的重型骨架(论文里用的是 DFlash)一次性为块内每个位置算出基础 logits。这一步继承了并行路线的优点:不管块多长,草稿成本几乎不变,而且第一个 token 的准确率很高。
第二步,接一个轻量串行小头,在采样前给每个位置加一个依赖前文的偏置。默认这个小头是个 Markov 头,只看紧挨着的前一个 token,并用 rank 256 的低秩分解压住参数量,即便词表很大也很便宜。
举论文里的例子:当第一个位置采样出 of 之后,这个小头会主动抬升 course 的概率、压低 problem 的概率。换句话说,它让后面的猜测"看一眼前面"。
效果是逐位置叠加的:并行骨架保证了开头的命中率,串行小头则把接受率稳稳托到块的深处,而不是像纯并行那样在后半段崩掉。论文还提到一个可选的 RNN 头能追踪整块前文,但增益边际,所以正式发布的版本用的是 Markov 头。
训练上有个细节值得记一笔:目标模型是冻结的,草稿头直接复用它的 embedding 和输出头,关键的损失项是全变分损失(total-variation loss)。最小化这个距离,等价于直接最大化草稿的接受率,目标很对齐。
数据层面,论文称在 Qwen3 的 4B/8B/14B 三个尺寸上,DSpark 的平均接受长度比 Eagle3 高 30.9% / 26.7% / 30.0%,比 DFlash 高 16.3% / 18.4% / 18.3%。更直观的是,2 层的 DSpark 就能压过 5 层的 DFlash。而串行小头本身几乎不花钱:把草稿块从 4 拉到 16,每轮延迟只多 0.2–1.3%,换来的接受长度提升最多到 30%。
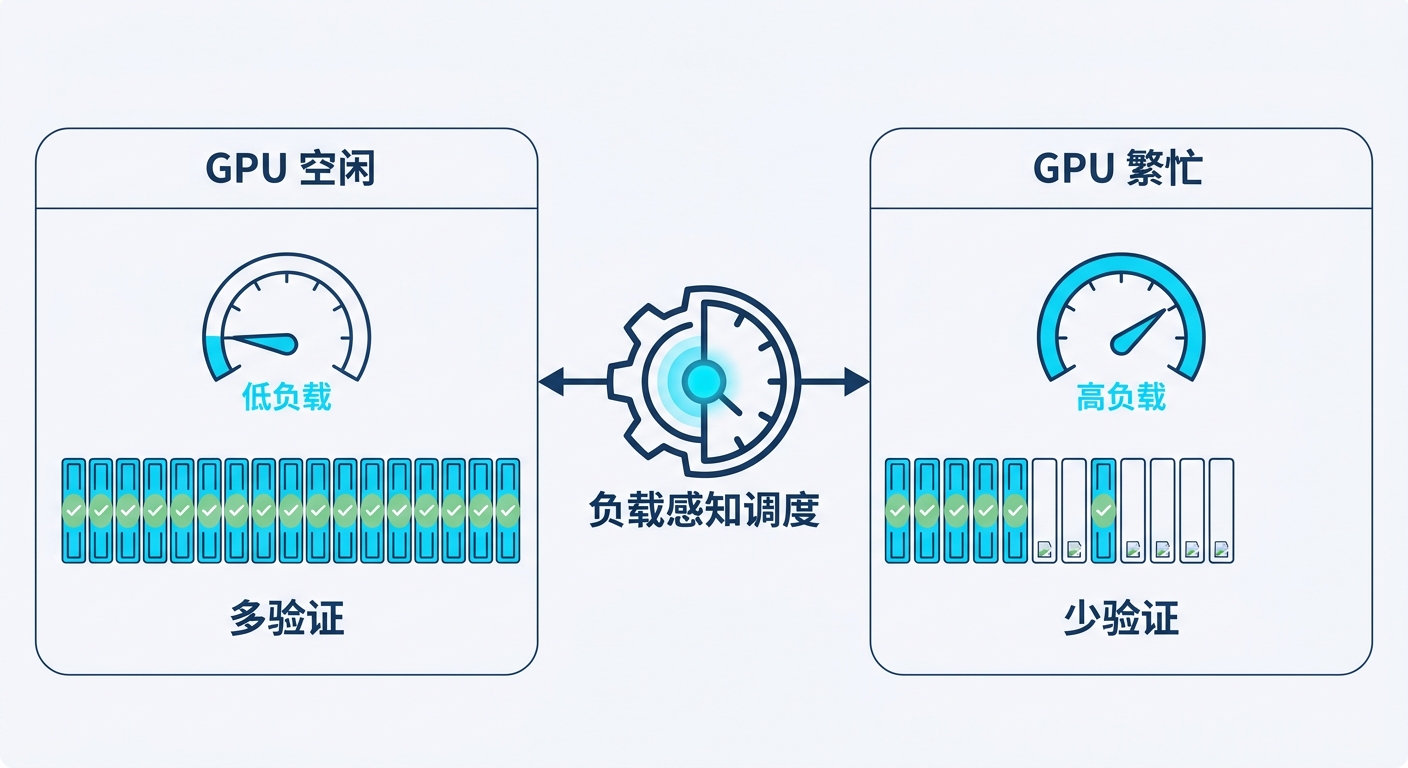
第二招:看 GPU 脸色的验证调度
光把草稿做准还不够。在真实的高并发服务里,多猜 token 不等于更快——验证那些注定被拒绝的 token,会白白吃掉宝贵的 batch 容量。DSpark 在这里加了两个零件。
第一个是置信度头(confidence head)。它给每个草稿位置打个分,估这个 token 能不能活过验证。监督信号来自解析出的逐步接受率。但神经网络天生爱"过度自信",所以作者又套了一层 Sequential Temperature Scaling 做事后校准,把预期校准误差(ECE)从 3–8% 压到约 1%。
第二个是硬件感知的前缀调度器。它在启动时先离线测一条吞吐曲线 SPS(B)(B 是 batch 大小),然后据此给每个请求动态分配验证长度。GPU 闲的时候,多验证几个 token;GPU 忙的时候,少验证,保住吞吐。这套调度带一条"早停"规则来保证无损——论文附录里专门给了一个反例,说明朴素的 全局搜索 会泄露信息,所以这条规则不是多余的。
不同负载下表现不同。据解读,中等负载时调度器大概会给每个请求验证 4–6 个 token;并发一上来,它就主动砍预算。这恰好是 DSpark 区别于前代的地方:Eagle3 和 DFlash 的验证长度基本是固定的,DSpark 则是动态的。
把两招合起来看,三个杠杆都动到了:并行骨架降 T_draft,串行小头和置信度头升 τ,负载调度省 T_verify。
和 MTP 是什么关系
如果你读过本站之前那篇讲 Gemma 4 MTP 和 Qwen 3.6 MTP 的文章,可能会问:这跟 MTP(多令牌预测,Multi-Token Prediction)有什么不一样?
两者都想一次生成多个 token,但思路不同。MTP 偏向让模型结构本身支持多 token 输出,DSpark 则是纯粹的推理时(inference-time)投机解码框架,挂在已有模型外面。更有意思的是,论文里 DSpark 的生产基线正好是 MTP-1,也就是 DeepSeek 之前那套单 token 设置。换句话说,DSpark 上线就是来替掉 MTP-1 的,60–85% 的提速是相对它而言。
发布的两组权重 DeepSeek-V4-Pro-DSpark 和 DeepSeek-V4-Flash-DSpark 都附在 V4 现成权重上,Hugging Face 卡片里有最小推理示例,目标模型不用重训。实际跑起来的发布配置叫 DSpark-5,也就是 5 个 token 的草稿块配 Markov 头。
想自己玩,门槛并不低
DSpark 的训练代码叫 DeepSpec,MIT 协议,三阶段走:数据准备、训练、评估。默认配置假设单机 8 张 GPU,评估覆盖 gsm8k、math500、aime25、humaneval、mbpp、livecodebench 等九个数据集,目标模型支持 Qwen3 和 Gemma 两个系列。仓库里同时收了 DSpark、DFlash、Eagle3 三种草稿模型,方便横向比。
但有一个现实门槛得提醒:复现训练所需的 目标缓存 体积惊人。论文/仓库提到,默认的 Qwen3-4B 设置下,这份缓存大约要 38 TB。普通团队基本只能直接用发布好的权重,走推理那条路,而不是从头训草稿。
对不同任务,收益也不一样。代码生成本身接受率就高,调度器敢验证长前缀,所以 编程类 agent 的流式输出会明显变顺;开放聊天经过一轮置信度阈值调整,接受率从 45.7% 提到 95.7%;数学推理居中,从 76.9% 提到 92.5%。越是结构化、越可预测的 workload,越吃香。
几个概念,谁负责什么
回到开头那道选择题。DSpark 里其实塞了四个互相配合的东西,把它们的关系理清,才算看懂这篇工作:
- 草稿模型负责"猜"。DSpark 把它拆成并行骨架加串行小头,分别拿下"快"和"准"。
- 目标模型负责"判"。它只做验证,不改输出分布,这是"无损"的来源。
- 置信度头负责给每个猜测打分,告诉系统哪些 token 值得拿去验证。
- 负载调度器负责"看脸色",在 GPU 忙闲之间动态调节验证长度,把算力花在刀刃上。
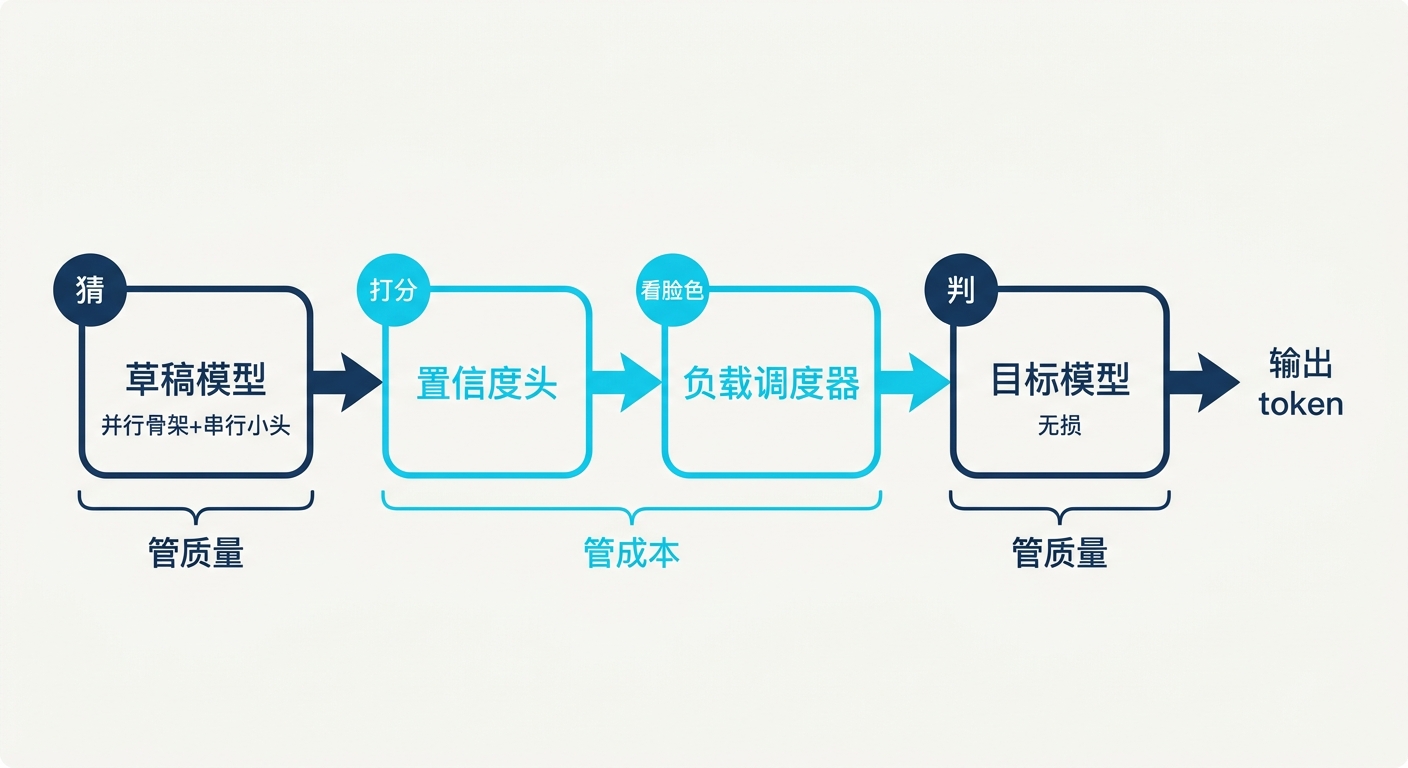
四者的边界很清楚:草稿和目标管"质量",置信度头和调度器管"成本"。DSpark 的真正贡献,不是发明了投机解码,而是把这条流水线上每个环节都重新调了一遍,让"快、准、省"第一次不必互相对抗。
放到更大的图里看,2026 年开源模型推理优化的战事已经从"谁的模型更强"悄悄转向"谁的服务更便宜"。MTP 路线、投机解码路线、各种 draft 模型设计,本质上都在抢同一块成本。DSpark 给出了一个相当完整、且直接上过 DeepSeek-V4 真实流量的开源样本。至于它在别家模型、别家硬件上能不能复现这个 60–85%,那就要等社区拿 38 TB 之外的更轻量复现来回答了。
参考来源
- DSpark 论文 PDF(DeepSpec 仓库内)
- DeepSpec 代码库(MIT 协议)
- DeepSeek-V4-Pro-DSpark 权重(Hugging Face)
- MarkTechPost 解读:DeepSeek Releases DSpark…
- Hacker News 讨论帖
以上来源用于观察发布口径和社区反馈,不等同于独立基准测试;文中所有百分比均为论文或官方解读给出的数据,未经本文独立复现。