
同一天,r/LocalLLaMA 上两篇帖子同时冲上热榜,内容分别是「Gemma 4 MTP released」(1046 赞)和「2.5x faster inference with Qwen 3.6 27B using MTP」(1051 赞)。这不是巧合,这是一个技术拐点。
2026 年 5 月 7 日,Google 和阿里同一天发布了各自旗舰开源模型的 MTP 加速版本。数字很直接:同一块 GPU,不换模型,不改参数,推理速度翻一倍到三倍。
如果你在跑本地大模型,这件事值得认真看一下。
先说今天发生了什么
Google DeepMind 发布了 Gemma 4 MTP 版本,支持 26B MoE、31B Dense 和 E2B/E4B 边缘模型。官方数据:
- NVIDIA GPU(RTX PRO 6000):最高 3 倍速度提升
- Apple Silicon(M 系列芯片):约 2.2 倍加速(batch size 4-8 时)
- 质量:输出质量和推理逻辑不降级
几乎同时,r/LocalLLaMA 上一篇 Qwen 3.6 27B MTP 的帖子也冲上热榜,用户实测 2.5 倍加速,配置:48GB 显存,262k 上下文窗口。
这两件事放在一起,说明 MTP 已经不是某家公司的实验技术——它正在成为开源模型推理的新标准配置。
MTP 到底是什么
先从头讲清楚。
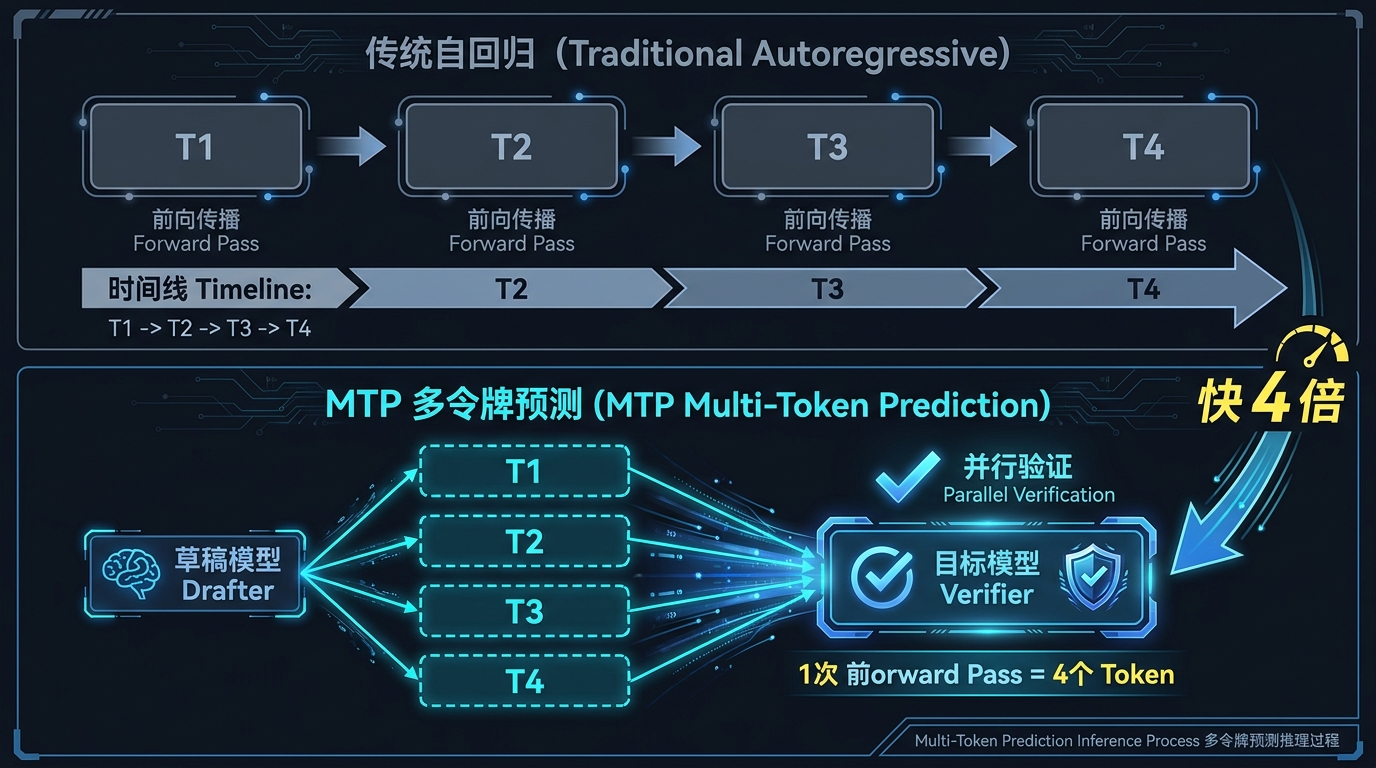
传统 LLM 推理是自回归的:模型每次只预测下一个 token,预测完才能预测下下一个,以此类推。你想要 100 个 token 的回答,模型就得走 100 步。每一步都要完整跑一遍 transformer 的 forward pass,这是推理慢的根本原因。
MTP(Multi-Token Prediction,多令牌预测)的思路是:不要只预测一个,先猜一串。
具体怎么做?
- 配一个轻量的「草稿模型」(drafter),这个小模型很快,在大模型完成一次 forward pass 的时间里,它能猜出接下来 3-4 个 token
- 大模型(target model)拿到这 3-4 个候选 token,并行验证——这一步和验证 1 个 token 的计算量几乎一样
- 如果全部正确,直接接受,一次前向传播净赚 3-4 个 token
- 如果某个位置猜错了,从那里截断,重新生成
关键在于第 2 步:验证是并行的,代价极低。只要草稿模型猜对的概率足够高,整体吞吐量就会大幅提升。
和 Speculative Decoding 什么关系?
严格来说,MTP 是 Speculative Decoding(推测解码)的一种实现方式。两者核心思路一致:用小模型猜,用大模型验。
但 Gemma 4 的 MTP 有一个关键设计差异:草稿模型与目标模型共享 KV 缓存和激活值。
这意味着:
- 不需要单独加载一个草稿模型的权重(省显存)
- 草稿模型天然了解目标模型的上下文状态(猜的更准)
- 整个推理流程更紧凑,适合显存有限的本地部署场景
传统 speculative decoding 需要找一个和大模型「配对」的小模型,配错了效果很差。MTP 的草稿模型是随主模型一起训练出来的,开箱即用。
数字说话:实际能快多少
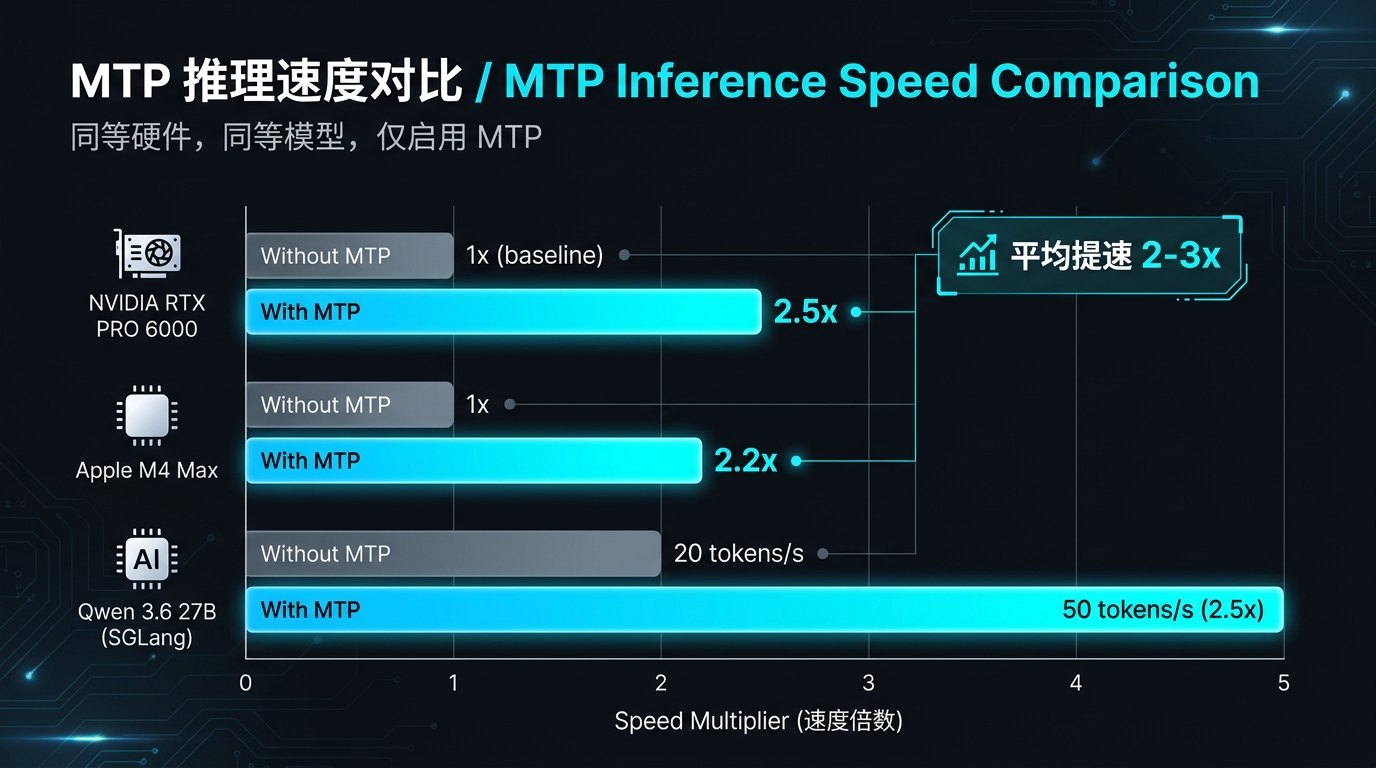
Gemma 4 MTP 官方数据
Google 发布的基准测试中:
| 设备 | 模型 | 提速倍数 |
|---|---|---|
| NVIDIA RTX PRO 6000 | Gemma 4 31B Dense | ~2-3x |
| Apple M 系列(M4 Max 等) | Gemma 4 27B | ~2.2x(batch=4-8) |
| 手机端(Android/iOS) | Gemma 4 E2B/E4B | 有提升,具体因设备而异 |
实际提速受两个因素影响最大:草稿模型的命中率和批量大小。命中率越高、batch 越大,加速越明显。
Qwen 3.6 27B MTP 社区实测
r/LocalLLaMA 热帖中,用户用 SGLang 在 48GB 显存环境下实测:
- 标准推理:约 20 tokens/s
- 启用 MTP(
--speculative-num-draft-tokens 4):约 50 tokens/s - 实测提速:约 2.5 倍
- 上下文长度:262k,全程稳定
这个数字在本地 AI 用户里算是相当可观了——等于你原本要等 10 秒的回复,现在 4 秒就能拿到。
为什么 Google 和阿里同时在这个时间点发布?
不是巧合,是技术成熟度到位了。
MTP 的理论基础并不新。DeepMind 的 AlphaCode、Meta 的研究都探索过多 token 预测,但真正在大规模部署中跑通,需要主流推理框架的配合。
SGLang、vLLM、MLX、Ollama 这些框架在过去半年里都逐步加入了对 speculative decoding 的原生支持。框架层面的基础设施到位了,模型厂商自然开始批量跟进。
另一个时机因素:MTP 对训练过程有要求,模型要在训练时就配上草稿模型联合优化。这意味着 Gemma 4 和 Qwen 3.6 在发布之初就内置了 MTP 能力,并非后期打补丁。
趋势判断:接下来几个月,你会看到越来越多的开源模型发布时就自带 MTP 版本。Llama 系列、Mistral 系列大概率也会跟进。到年底,不带 MTP 的本地模型可能会显得「过时」。
怎么在本地跑起来
Gemma 4 MTP(推荐 Ollama 或 MLX)
Ollama(最简单)
|
|
Ollama 已经在近期版本中集成了 MTP 支持,拉取带 MTP 标记的模型变体即可自动启用。
MLX(Apple Silicon 用户首选)
|
|
MLX 框架对 Apple Silicon 统一内存做了深度优化,跑 Gemma 4 MTP 的 2.2x 加速在 M3/M4 芯片上能稳定复现。
Qwen 3.6 27B MTP(推荐 SGLang)
SGLang 是目前对 MTP/speculative decoding 支持最成熟的推理框架:
|
|
几个参数说明:
--speculative-algo NEXTN:启用 Next-N Token 推测算法(MTP 的 SGLang 实现)--speculative-num-steps 3:草稿模型跑 3 步--speculative-num-draft-tokens 4:每步最多猜 4 个候选 token--tp 2:双 GPU 张量并行(48GB 显存建议两张 24GB 或一张 48GB)
vLLM 用户
|
|
vLLM 的 ngram speculative decoding 也能提速,但命中率比 MTP 专用草稿模型稍低。
注意事项
什么情况下 MTP 效果最好?
- 长文本生成(小说、报告、代码):草稿模型命中率高,加速明显
- 重复性较高的内容(代码补全、模板填写):效果最佳
什么情况下 MTP 效果有限?
- 极短回复(1-3 个 token):加速来不及体现
- 高温度随机采样(temperature > 1.0):草稿命中率下降
显存:MTP 会多用多少?
几乎不额外增加。草稿模型共享 KV cache 的设计意味着额外显存开销通常在 5% 以内,对本地部署用户基本无感。
总结
MTP 是推理优化里难得的「免费午餐」:不换模型、不损质量、不加显存,速度翻倍。
Google 和阿里同一天跟进,说明这项技术的基础设施依赖已经就位,主流框架的支持也已到位。接下来几个月,MTP 会从「高级用户才用的技巧」变成「新模型的标配能力」。
如果你现在在本地跑 Gemma 4 或 Qwen 3.6,不妨直接切到 MTP 版本试一下——2.5 倍的提速,体感差别还是很明显的。
参考来源