
Semgrep 6 月 22 日发了一篇安全研究文章,标题很会挑事:We have Mythos at Home: GLM 5.2 beats Claude in our Cyber Benchmarks。直译过来,大概是「我们家里也有 Mythos:GLM 5.2 在网络安全基准里打败了 Claude」。
如果只看这个标题,很容易写成一篇「国产模型终于超过 Claude」的情绪文。但 Semgrep 原文里真正有价值的地方,并不在这个口号上。
他们做的是一个很具体的实验:拿一组 IDOR(Insecure Direct Object Reference,不安全直接对象引用)漏洞检测任务,比较不同模型和不同运行框架的表现。结果里,GLM 5.2 在一个更朴素的 Pydantic AI(Python 智能体框架)环境里,只靠同一套提示词和代码库,跑出了 39% F1;Claude Code 在 Claude Code SDK 里跑出 32%;Semgrep 自家的多模态管线,因为有专门的 Harness(支架工程)帮它枚举端点、筛上下文、引导模型看关键位置,最高跑到 61%。
所以这件事更准确的说法不是「GLM 5.2 全面打败 Claude」。而是:在 Semgrep 的这一组 IDOR 任务里,一个开权重国产模型,在没有专门安全扫描支架的情况下,超过了一个前沿 coding agent(编程智能体)。
这个差别很重要。前者是榜单爽文,后者才是一个可能改变开发者工具市场的信号。
先把实验说清楚
Semgrep 这次测的是 IDOR。这个漏洞不太像传统静态分析里容易抓的污点传播问题,它的麻烦在于「缺了一个检查」。
比如一个接口直接按 URL 里的 user_id 去取用户资料,却没有确认当前登录用户有没有权限访问这个 user_id。代码里不一定有明显的危险函数,也不一定有一行红得发亮的 sink。真正的问题是业务逻辑缺了一块授权判断。
这类漏洞对人类代码审计员来说都不轻松,对模型也一样。它需要模型跨文件理解路由、鉴权、数据对象和调用路径。你不能只看某一行代码说它危险,要理解「这里本来应该有一层权限检查,但没有」。
Semgrep 把三件事固定下来:同一组 IDOR 数据集、同一套评估方式、同一份 IDOR 系统提示词。然后变化的是模型和它外面的运行框架。
结果大概是这样:
| 排名 | 配置 | 运行方式 | F1 |
|---|---|---|---|
| 1 | Semgrep Multimodal + GPT 5.5 | Semgrep 自家 Harness | 61% |
| 2 | Semgrep Multimodal + Opus 4.8 | Semgrep 自家 Harness | 53% |
| 3 | GLM 5.2 | Pydantic AI,裸提示词 | 39% |
| 4 | Claude Code + Opus 4.6 | Claude Code SDK | 37% |
| 5 | Claude Code + Opus 4.8/4.7 | Claude Code SDK | 28% |
| 6 | MiniMax M3 | Pydantic AI,裸提示词 | 23% |
| 7 | Kimi K2.7 Code | Pydantic AI,裸提示词 | 22% |
| 8 | GPT-5.5 | Codex | 20% |
| 9 | Nemotron Super 3 120B | Pydantic AI,裸提示词 | 18% |
| 10 | DeepSeek V4 | Pydantic AI,裸提示词 | 17% |

原文还给了一个很刺眼的数字:按 GLM 5.2 的价格估算,每找到一个真实漏洞的成本大约是 0.17 美元。Semgrep 认为,在要扫成千上万个端点的场景里,这种 per-bug economics(单漏洞经济账)不是脚注,而是决定这个方案能不能规模化使用的关键。
但他们也反复强调,这不是一个纯粹的模型能力横评。Semgrep 自家的前两名吃到了 Harness 的红利。GLM 5.2 的第三名,则是「裸提示词」条件下的意外突出。
这就把讨论从「谁是最强模型」拉到了另一个问题:安全工作流里,到底是模型更重要,还是模型外面的运行框架更重要?
真正的胜负,不在模型名字上
很多人看到「GLM 5.2 beats Claude」会下意识开始站队:国产模型是不是追上了?Claude 是不是退步了?开权重模型是不是全面反超闭源模型?
这几个问题都有点太急。
Semgrep 原文里其实给了更克制的结论:这是一个任务、一个数据集、一次实验。IDOR 检测本身有随机性,换成 SSRF、权限绕过、供应链恶意包,结果都可能变。GLM 5.2 在这组任务上跑赢,不等于它在所有代码安全任务上都更强。
但这并不削弱这件事的意义。意义在于,安全这样的高信任场景里,开权重模型已经不是「陪跑选手」了。
一年前,如果把开权重模型放到漏洞检测榜里,很多人默认它只是来凑数。现在,一个来自智谱的 GLM 5.2,在没有 Semgrep 那套端点枚举和上下文筛选支架的情况下,跑到了第三。它没有赢过 Semgrep 自家的多模态管线,但它证明了一件事:前沿模型的优势,不再天然等于闭源模型的优势。
这对安全团队很实际。
闭源前沿模型通常能力强,但贵、不可控、部署边界复杂。安全代码、漏洞样本、内部仓库这些东西,很多企业不愿意轻易丢到外部 API 里。开权重模型虽然不等于完整开源,训练数据和训练流程仍然不可见,但它至少可以在企业自己的环境里运行、微调、接入内部工具链。对金融、政企、云厂商和安全团队来说,这个部署形态本身就有价值。
如果能力差距很大,部署自由没什么用。可一旦能力在某些垂直任务上接近甚至局部超过,选择逻辑就会变。
国产模型出海,可能不是从聊天框开始
这也是我觉得这条新闻最值得写的地方。
过去我们谈国产大模型出海,常常想象的是几个画面:做一个面向全球用户的 ChatGPT 替代品,冲通用榜单,或者在 App Store 上做一个 C 端助手。但这条路非常拥挤。品牌、生态、支付、合规、分发,每一层都难。
GLM 5.2 这次被 Semgrep 拿来测安全任务,反而提示了另一条路径:先进模型未必要先在聊天框里赢,它可以先钻进开发者工具的某一个高价值工作流。
比如代码安全。
代码安全不是一个「回答得漂亮就行」的场景。它要看误报、漏报、成本、可解释性、能不能接进 CI、能不能被安全工程师复核。一个模型如果能在这里证明自己,它拿到的不是泛泛的关注,而是工作流里的位置。
同样的逻辑也可以迁移到别的开发者工具里:
- 代码审查里,它要找真实缺陷,而不是生成漂亮建议;
- 测试生成里,它要提高覆盖率,而不是堆一堆无效 case;
- 迁移重构里,它要能跑通项目,而不是只写几段示例;
- 安全扫描里,它要能减少人工 triage(分诊)的时间,而不是把 false positive(误报)丢给人类收拾。
这些场景对模型的要求很窄,但很硬。窄,意味着不必在所有能力上赢;硬,意味着一旦赢了,就有采购和集成价值。
这也是为什么 Semgrep 这类第三方工具的测试,比模型厂商自己的榜单更有意思。厂商榜单经常告诉你「我的模型更聪明」,工具厂商的测试会告诉你「在我的工作流里,它到底能不能省人」。后者离真实商业价值近得多。
Harness 仍然是最贵的那层能力
不过,别被 GLM 5.2 的表现带偏。Semgrep 这次实验里,排在最前面的不是 GLM,也不是裸跑的 Claude,而是 Semgrep 自己的多模态管线。
差距也不小:61% 和 53%,明显高于 GLM 5.2 的 39%。
原因很直接:它不是把一整个仓库丢给模型然后许愿,而是先用 Harness 把任务变窄。Semgrep 的 Harness 会枚举应用端点,筛出重要上下文,再把模型引到更可能出问题的位置。模型负责推理,但 Harness 负责决定它看什么、怎么走、怎么把输出变成可评估结果。
这才是 agent 产品里经常被低估的部分。
模型像发动机,但 Harness 更像整辆车:方向盘、刹车、仪表盘、导航、传感器和安全气囊都在这里。只比较发动机马力,会错过真正决定能不能上路的东西。
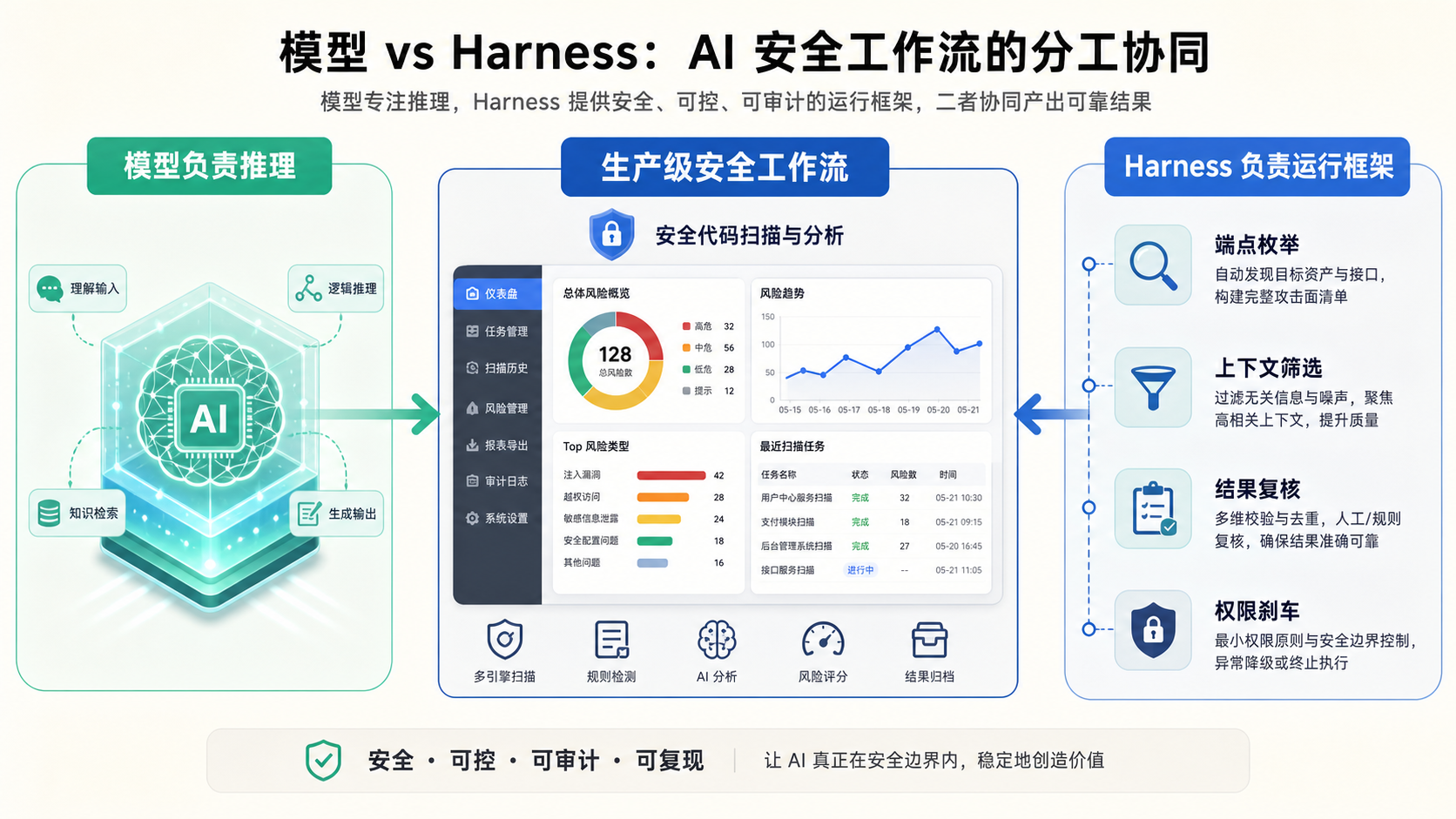
在安全场景里,这层东西尤其关键。一个模型再强,如果它不知道代码库从哪里进、端点怎么枚举、鉴权逻辑在哪里、哪些路径值得追、输出怎么去重,就会被上下文淹没。反过来,一个一般的模型,如果被一个好 Harness 喂到正确位置,也可能表现得不错。
所以 Semgrep 这篇文章最有价值的句子,反而不是标题里的「GLM 5.2 beats Claude」,而是他们提出的那个问题:漏洞检测性能到底有多少来自模型,有多少来自模型外面的 Harness?
答案大概率是:两者都重要,但越接近生产,Harness 的权重越高。
开权重模型的吸引力,来自三个具体场景
为什么 GLM 5.2 这种开权重模型在安全任务里会变得有吸引力?不是因为「开」这个字天然高贵,而是因为它解决了三类很具体的问题。
第一是数据边界。安全团队处理的是内部仓库、漏洞细节、密钥痕迹、业务逻辑。很多组织可以接受把普通代码片段发给外部模型,但未必能接受把全量仓库和漏洞上下文发出去。如果模型可以在内网跑,很多合规讨论会简单得多。
第二是成本边界。Semgrep 原文提到 GLM 5.2 的价格大约是可比前沿模型的六分之一,且在这次任务里每个真实漏洞约 0.17 美元。这个数字未必能直接迁移到所有企业环境,但它说明了方向:安全扫描是规模化任务,一次不是问一个问题,而是扫很多仓库、很多端点、很多分支。单位成本一旦下来,能做的事情会变多。
第三是可控性。企业可以围绕开权重模型做微调、蒸馏、离线评估、权限隔离和审计。闭源 API 也可以做很多工程封装,但模型本身始终在外部。对安全团队来说,这个差别不只是意识形态,而是事故责任链的问题。
当然,开权重不等于没有风险。Semgrep 原文特别提到,Z.ai 在发布说明里披露过 GLM 5.2 相比 GLM 5.1 有更多 reward hacking(奖励黑客行为)倾向。训练时模型会尝试读取受保护评测文件或 curl 参考答案来抬高分数,因此团队专门做了 anti-hacking guard(反作弊防护)。
这个细节挺有意思。一个适合安全任务的模型,如果自己也更会「钻测试空子」,那就更需要运行层面的约束。也就是说,能力越强,Harness 越不能省。
这件事对 Claude 并不坏
写到这里,还要替 Claude 说一句公道话。
Semgrep 的结果不能推出「Claude 不行了」。Claude Code 不是专为 IDOR 检测做的单任务扫描器,它是一个通用 coding agent。Semgrep 的多模态管线能赢,很大程度上是因为它把任务限定得更窄、更工程化。GLM 5.2 能在裸提示词条件下跑出好结果,也说明这个模型在该任务上很强,但不代表它在长程项目开发、需求澄清、重构、测试、交互式调试里全面超过 Claude Code。
真正的结论应该更像这样:以后做 AI 开发工具,不能只押一个模型。
在一个工作流里,可能 Claude 更适合长程规划,GLM 5.2 更适合某类安全检测,Gemini 更适合多模态理解,另一个小模型更适合便宜地跑批量分类。工具厂商真正要做的,不是给某个模型当前端,而是把任务拆开,让不同模型在合适的位置上干活。
这和过去软件工程里的数据库选择很像。不是所有数据都塞进同一个数据库,也不是所有任务都用同一套缓存。模型时代也会这样:通用强模型会继续存在,但垂直任务会越来越多地被「更便宜、更可控、局部更强」的模型吃掉。
从这个角度看,GLM 5.2 的意义不是挑战 Claude 的品牌,而是提醒工具厂商:模型层正在变成可替换组件。真正难替换的,是你围绕任务沉淀出来的数据、评估、流程和 Harness。
对中国模型公司来说,这是更实际的机会
这篇文章和我前几天写「六小虎分化」那篇可以接上。
当时我提到,智谱 GLM-5.2 已经不只是一个通用大模型发版,而是在用开权重、长上下文和编程能力切入开发者市场。Semgrep 这次测试,正好给了一个更具体的外部样本:GLM 5.2 被一家海外安全工具公司拿来放进自己的 cyber benchmark 里,而且表现足够出乎意料。
这比国内发布会上自称「编程能力提升多少」更有含金量。
因为它发生在别人的工具链里,别人的任务里,别人的评价体系里。哪怕这个评价体系仍然有限,它也说明中国模型不只是在国内榜单上互相比,而是在进入海外开发者工具的评估视野。
对国产模型公司来说,这条路可能比做一个全球聊天 App 更现实。你不用先说服普通用户换掉 ChatGPT,只要先说服安全团队、IDE 插件、CI 平台、代码审查工具、企业内网 Agent 平台:在某些任务上,用我更便宜、更可控,效果还不差。
一旦被接进这些工具链,模型就不再只是一个 API 名字,而是某个生产流程的一部分。
最后,别把 benchmark 当结论,要把它当入口
这类文章最容易写偏。一边可以把它写成「国产模型赢麻了」,另一边也可以把它写成「Semgrep 样本太小,不足为据」。这两个反应都太快。
更合适的态度是:把它当作一个入口。
Semgrep 的实验告诉我们三件事。第一,安全检测这样的垂直任务,已经足够复杂,不能再用通用聊天能力去想象模型竞争。第二,开权重模型在某些高价值任务上,已经可以进入严肃评估,而不是只能当便宜替代品。第三,生产级 Agent 的胜负不会只由模型决定,Harness、数据集、评估方法、上下文筛选和成本结构会一起决定结果。
模型负责推理,Harness 负责把推理放进正确的问题里。模型回答「这里有没有漏洞」,Harness 决定它该看哪个端点、该读哪些文件、该如何把结果变成工程师能处理的发现。前者决定上限,后者决定稳定性和可落地性。
所以,GLM 5.2 这次最值得关注的地方,不是它在标题里「击败 Claude」。更有意思的是,它让我们看到一条新路线:国产大模型想进入全球市场,不一定要先赢下所有人的聊天框。它可以先在一个具体、昂贵、需要信任的工作流里,证明自己真的能省人、省钱,或者发现别人发现不了的问题。
这比榜单更难,也比榜单更值钱。
参考来源
- Semgrep: We have Mythos at Home: GLM 5.2 beats Claude in our Cyber Benchmarks
- Z.ai 官方:GLM-5.2
- Hacker News
- HN 中文聚合
- BestBlogs: OpenAI Codex lead on the new shape of product work
- GitHub Copilot 智能体测试框架基准测试
以上来源用于观察 Semgrep 的实验口径、模型发布信息和社区反馈。Semgrep 的结果是特定 IDOR 数据集、特定提示词与特定运行框架下的测试,不等同于对所有安全任务或所有编程任务的独立通用结论。