
2026 年 4 月 28 日,OpenAI 和 Anthropic 做了一件很有信号意义的事。
它们把各自最新的网络安全 AI 模型,带进了美国众议院国土安全委员会。
不是发布会。
不是产品演示。
而是闭门汇报。
Axios 的报道说,OpenAI 和 Anthropic 已经分别向国会议员和工作人员介绍了这些“具备网络能力”的新模型,以及它们可能给网络安全带来的影响。
听起来像是一条普通的政策新闻。
但它背后真正的问题是:
当 AI 已经可以帮助发现漏洞、分析攻击链、甚至辅助生成利用路径时,这种能力应该给谁用?
只给少数大型科技公司和政府机构?
还是开放给更多经过验证的安全团队?
这一次,OpenAI 和 Anthropic 给出了两套完全不同的答案。
这次汇报为什么重要
过去几年,AI 安全讨论大多围绕几个主题:
模型会不会胡说?
会不会泄露隐私?
会不会生成有害内容?
会不会被越狱?
但网络安全模型把问题推到了另一个层级。
因为它不只是“说错话”。
它可能帮助人发现真实系统里的漏洞。
Anthropic 的 Claude Mythos Preview,据称在测试中发现了大量高严重性、此前未知的软件漏洞。OpenAI 的 GPT-5.4-Cyber,则是 GPT-5.4 面向防御性网络安全任务的专门版本,支持更深入的漏洞研究、恶意软件行为分析和二进制逆向。
这类模型有一个天然的双重属性。
同一项能力,防御者可以用来提前发现漏洞、修补系统;攻击者也可以用来降低攻击门槛、扩大攻击规模。
所以国会关心的不是“AI 能不能写代码”。
而是更现实的问题:
如果这种模型继续进化,美国的关键基础设施、医院、电网、金融系统和地方政府网络,会不会先被攻击者用 AI 打穿?
如果防御者也需要这种能力,谁来决定访问资格?
Anthropic 的答案:太危险,所以只给少数人
Anthropic 的路线很清楚:严格控制。
它的代表模型是 Claude Mythos Preview。
这个模型并没有面向公众发布,而是放进了一个叫 Project Glasswing 的防御计划里。
根据公开报道,参与方包括 Apple、Google、Microsoft、AWS、Cisco、CrowdStrike、JPMorgan Chase、Linux Foundation 等少数大型机构。Axios 此前还提到,大约 40 个公司和组织获得了相关访问权限。
Anthropic 的逻辑并不难理解。
如果一个模型已经具备发现高危漏洞、分析复杂系统弱点的能力,那么让它进入公众可用状态,本身就是风险。
尤其是在网络安全领域,能力扩散的速度可能比防御体系升级更快。
一个普通攻击者过去需要多年经验才能完成的事情,如果被 AI 压缩成“提示词 + 工具调用 + 自动化分析”,那整个攻防生态都会被改写。
所以 Anthropic 的选择是:
先不给大众。
先给少数最有能力、最有资源、也最能承担责任的机构。
这些机构本身维护着大量关键软件、云基础设施、操作系统、浏览器、安全产品和金融系统。Anthropic 希望它们先用 Mythos 找出自己系统里的漏洞,形成防御经验,再逐步建立行业规则。
这个策略的优点是显而易见的:
风险可控。
参与者可信。
反馈质量高。
一旦模型发现严重漏洞,少数大机构也更有能力快速修补。
但缺点同样明显。
如果只有巨头和少数政府部门能用最强防御工具,那么其他人怎么办?
中小企业、地方医院、学校、市政系统、公共事业单位,往往才是最缺网络安全资源的一群人。它们没有 Apple、Google、Microsoft 那样的安全团队,却同样暴露在攻击面上。
如果最强 AI 防御工具只给少数机构,那么安全能力可能会进一步集中。
强者更强。
弱者继续裸奔。
OpenAI 的答案:可以开放,但必须验证身份
OpenAI 选择了另一条路。
它推出的是 GPT-5.4-Cyber。
按照 The Next Web 的报道,这是 GPT-5.4 面向防御性网络安全任务的专门版本。它降低了普通模型在漏洞研究、恶意软件行为分析、利用链理解等方向上的拒答限制,并新增了二进制逆向能力。
但 OpenAI 没有说“所有人都来用”。
它把访问放进了 Trusted Access for Cyber 体系。
简单说,就是分层访问。
用户需要验证身份。
不同级别的用户获得不同能力。
最高级别的验证用户,才可以使用 GPT-5.4-Cyber。
OpenAI 的路线可以概括为:
不是不开放,而是带身份、带监控、带权限地开放。
这个思路和 Anthropic 很不一样。
Anthropic 更像是在说:能力太危险,所以只能交给极少数机构。
OpenAI 更像是在说:能力确实危险,但防御者也需要它;关键不是把门关死,而是建立访问制度。
这背后有一个现实判断。
攻击者并不会因为 OpenAI 和 Anthropic 谨慎,就停下来。
开源模型会进步。
地下工具会进步。
其他国家和组织也会训练自己的网络安全模型。
如果防御方不能广泛获得类似能力,那么未来可能出现一种不对称局面:攻击者用 AI 自动化发现漏洞,普通防御者还在靠人肉排查 CVE 清单。
OpenAI 的赌注是:让更多经过验证的安全人员使用高级模型,可以提高整体防御水平。
但它的问题也很尖锐。
验证机制真的可靠么?
权限分层能不能防止滥用?
使用监控能不能及时发现异常?
如果模型输出被转移、复用、包装成其他工具,平台还能控制吗?
这不是简单的产品风控问题,而是网络安全 AI 的治理实验。
真正的分歧:安全能力应该集中,还是扩散?
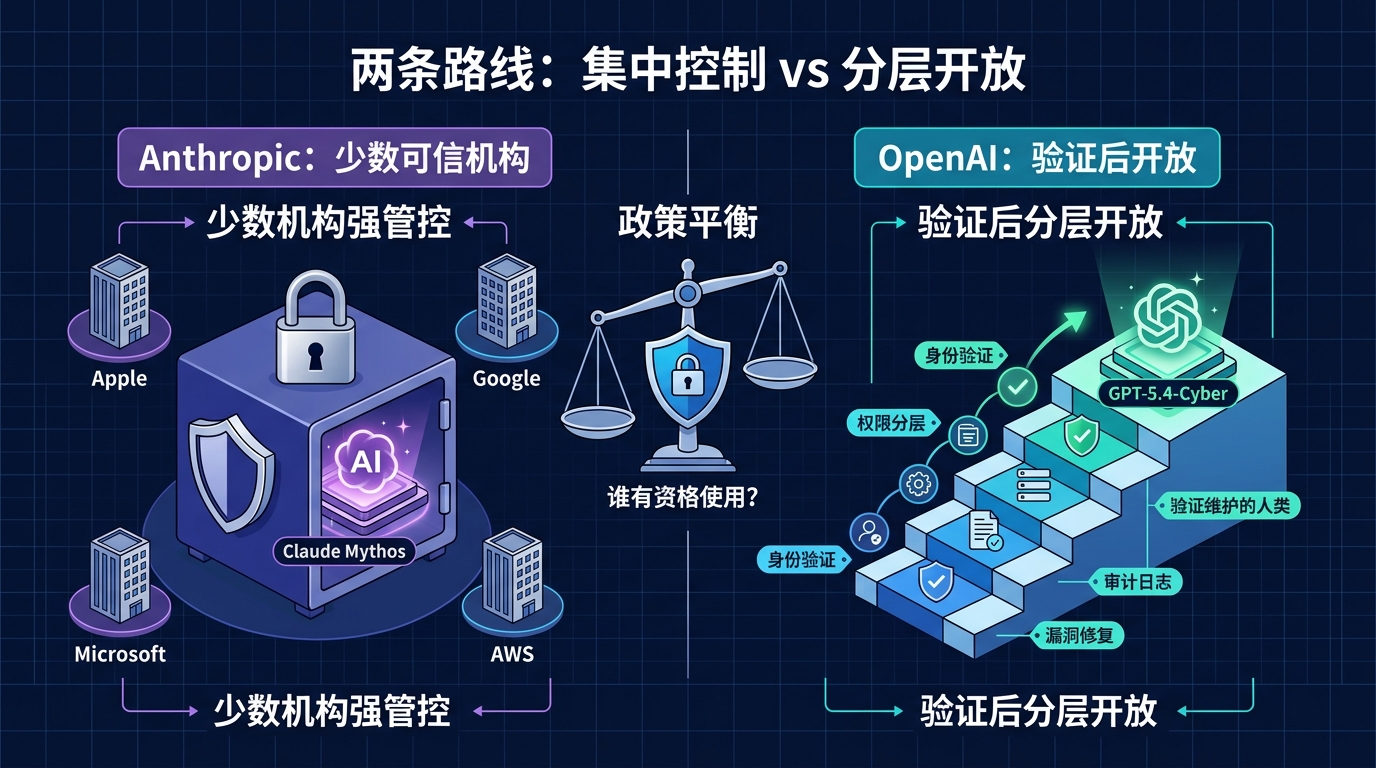
所以,OpenAI 和 Anthropic 的分歧,不是技术路线分歧。
而是治理哲学分歧。
Anthropic 认为,最危险的能力应该先集中在少数可信机构手里。
OpenAI 认为,防御性能力应该在验证后更广泛地扩散。
两边都有道理。
如果能力扩散太快,攻击门槛会下降。
如果能力集中太久,防御能力会垄断。
这就是网络安全领域最麻烦的地方。
不像图像生成,滥用后最多是版权、深伪、垃圾内容。
网络安全模型一旦被滥用,影响的是现实系统。
医院可能停摆。
城市服务可能中断。
金融系统可能被勒索。
工业设备、汽车、航空、IoT、遗留银行系统这类难以及时修补的基础设施,风险尤其高。
Bruce Schneier 在分析 Mythos 时提到一个很重要的判断:AI 不一定会让攻击方永久占优,关键取决于系统是否容易修补、是否容易验证。
手机、浏览器、大型云服务这类系统,如果有快速更新机制,AI 反而可能帮助防御者更快发现和修复漏洞。
但那些难以更新、难以验证、长期暴露在真实环境中的系统,就会成为最脆弱的目标。
这也是为什么国会会关心这件事。
因为它已经不是某家 AI 公司的产品策略,而是国家基础设施风险。
“实验室很强”和“真实世界可用”不是一回事
不过,也不能把这类模型神化。
CyberScoop 报道中,美国联邦 CIO Greg Barbaccia 对 Mythos 的态度就很谨慎。
他的核心意思是:
测试和基准表现很重要,但不能直接等同于真实网络环境里的有效性。
实验室里发现漏洞是一回事。
面对一个有人防守、有告警系统、有权限边界、有复杂业务逻辑的真实网络,是另一回事。
这句话很关键。
很多 AI 模型在 benchmark 上看起来很强,但真实环境里会遇到一堆脏问题:
系统文档不完整。
资产清单不准确。
权限边界混乱。
历史包袱很多。
告警噪声巨大。
业务系统不能随便停机。
安全团队真正缺的,也不只是“再发现一个漏洞”。
他们缺的是判断:
哪个漏洞真的影响核心资产?
哪个漏洞只是理论风险?
哪个修复可以立即做?
哪个修复会影响生产系统?
哪个风险应该优先处理?
所以 AI 网络安全模型的价值,不能只看它能不能发现漏洞。
更要看它能不能进入完整的防御流程。
这也是 Schneier 提到的 VulnOps 方向:用 AI agent 持续在真实技术栈上测试漏洞、验证修复、过滤误报,并把安全测试变成软件工程的日常流程。
换句话说,未来的安全 AI 不应该只是一个”黑客聊天机器人”。
它更像是一套持续运行的防御系统。
发现。
验证。
排序。
修复。
复测。
留痕。
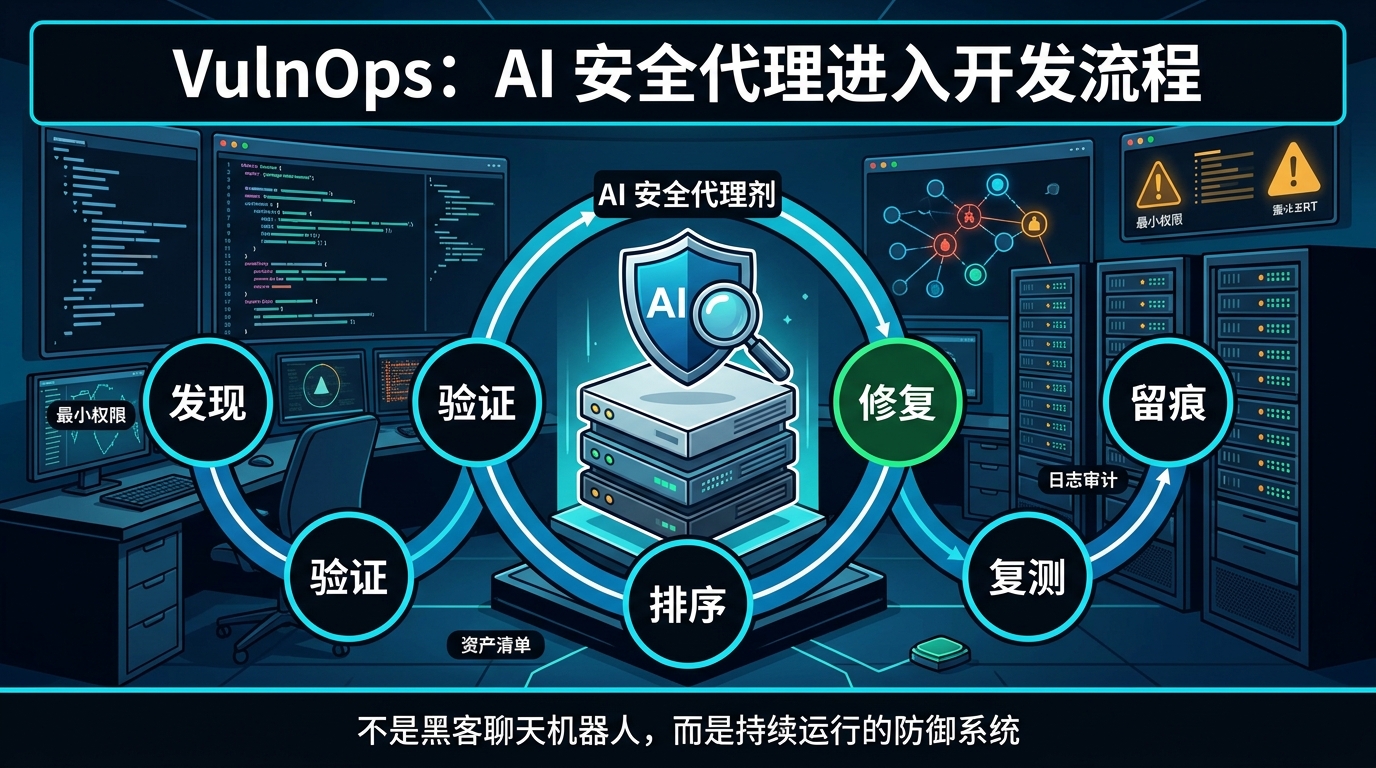
这才是真正的价值。
CISA 没有访问权限,说明问题更复杂
还有一个细节很值得注意。
Axios 此前报道,美国网络安全和基础设施安全局 CISA 并没有获得 Anthropic Mythos 的访问权限。
这很微妙。
CISA 是美国负责保护民用联邦网络和关键基础设施的重要机构。按理说,如果有一个强大的防御性网络安全模型,它应该是最需要访问的一方。
但现实并没有这么顺。
有些政府机构已经在测试 Mythos,比如 NSA 和商务部相关 AI 测试机构;财政部也在寻求访问。但 CISA 仍然在外面。
这说明“谁有资格使用最危险的 AI”并不是一个简单的技术审核问题。
它牵涉公司政策。
政府采购。
供应链风险认定。
军方使用边界。
监管关系。
机构间权限协调。
Anthropic 此前因为军方使用限制问题,与美国国防部门发生过冲突。这个背景也让 Mythos 在政府内部的访问安排更复杂。
所以,AI 网络安全模型越强,越不可能只是一个 SaaS 产品。
它会变成政策问题。
对普通开发者意味着什么
这件事听起来离普通开发者很远。
国会、Anthropic、OpenAI、CISA、NSA、Mythos、GPT-5.4-Cyber,都是大词。
但它其实和每个软件团队都有关。
因为这类能力迟早会下沉。
今天是顶级实验室和政府闭门讨论。
明天可能是大型企业安全团队的内部工具。
后天就会变成开发流程的一部分。
未来的软件工程,很可能会默认包含一层 AI 安全代理:
提交代码后,它自动做漏洞扫描。
部署前,它自动构造攻击路径验证。
依赖升级时,它自动判断 CVE 是否真正影响当前系统。
系统上线后,它持续模拟攻击面,检查权限边界和配置错误。
这不是科幻。
它只是把今天已经存在的 SAST、DAST、依赖扫描、红队演练、日志分析、安全审计,重新用 AI 串成一个更连续的流程。
但这里有一个前提:
AI 不能替代安全制度。
最小权限、资产清单、日志留存、快速修补、变更审计、网络隔离、密钥管理、依赖治理,这些老东西不会因为 AI 出现而过时。
恰恰相反,它们会更重要。
因为 AI 越强,越需要清晰的系统边界和可验证的工程流程。
如果你的系统本来就没有权限边界、没有资产清单、没有测试环境、没有日志,那 AI 只会更快地告诉你:你到底有多脆弱。
最危险的 AI,到底应该给谁用?
回到最开始的问题。
谁有资格使用最危险的 AI?
Anthropic 的答案是:少数可信机构先用。
OpenAI 的答案是:经过验证的防御者分层使用。
我更倾向于认为,未来不会只有一种答案。
最强能力,短期内一定会被严格限制。
但防御性能力,长期一定会向更多组织扩散。
因为网络安全不是少数巨头能单独解决的问题。
攻击面分布在整个社会。
医院、学校、地方政府、小企业、开源项目、工业系统、个人设备,都是攻击面的一部分。
如果只有少数机构拥有 AI 防御工具,那么整体安全并不会真正提高。
但如果完全开放,又会制造新的灾难。
所以真正需要建立的,不是“开放”或“封闭”二选一,而是一套新的访问制度:
谁可以用?
用到什么能力级别?
是否需要身份验证?
是否需要日志审计?
是否允许数据保留?
发现漏洞后如何披露?
模型输出是否能进入自动化执行链?
出现滥用由谁负责?
这些问题,比模型本身更难。
也更重要。
OpenAI 和 Anthropic 把 AI 黑客模型带进国会,标志着一个新阶段的开始。
AI 网络安全不再只是工程师之间的技术竞赛。
它正在变成监管问题、产业问题、国家安全问题,也会变成每个软件团队迟早要面对的工程问题。
未来最重要的能力,也许不是“让 AI 找到漏洞”。
而是让人类社会决定:
这种能找到漏洞的 AI,应该被怎样安全地使用。
参考来源
- Axios: OpenAI, Anthropic brief House Homeland Security on AI cyber threats
- Axios: OpenAI briefs feds and Five Eyes on new cyber product
- Axios: CISA doesn’t have access to Anthropic’s Mythos
- The Next Web: OpenAI releases GPT-5.4-Cyber for vetted security teams
- Schneier on Security: What Anthropic’s Mythos Means for the Future of Cybersecurity
- CyberScoop: Federal CIO cautious on Anthropic’s Mythos despite planned rollout
- KYC AI LABS: The AI Cybersecurity Arms Race: Mythos vs. GPT-5.4-Cyber
- Permiso Security: Episode 09 - Mythos, GPT-5.4 Cyber, and Opus 4.7