
OpenAI 在 5 月 19 日发了一篇关于内容溯源的更新。它准备在 ChatGPT、Codex 和 OpenAI API 生成的图片里加入 Google DeepMind 的 SynthID 隐形水印,同时继续支持 C2PA Content Credentials,并开放一个早期验证工具,让用户上传图片后检查里面是否带有 OpenAI 的来源信号。
单看功能,这像是一条安全更新。AI 图越来越多,平台加水印、做验证,似乎是顺理成章的事。
但这条新闻有个细节值得单独拎出来看:OpenAI 没有只推自己的识别体系,而是接入了 Google 的 SynthID。
这意味着内容溯源正在从“各家公司自己证明自己”往外走一步。过去两年,AI 生成内容识别很像一堆孤岛:A 公司说自己的模型会加标记,B 平台说自己能检测,C 工具说自己能验证。问题是,一张图只要离开生成平台,就会进入社交网络、聊天软件、截图、转存、压缩、二次编辑的混合环境。单个平台的承诺,很难在这条传播链里一直有效。
OpenAI 这次接入 SynthID,重要性就在这里。它不是多了一个“水印按钮”,而是在承认:AI 内容的信任问题,不能靠某一家厂商独自解决。
OpenAI 这次做了哪几件事
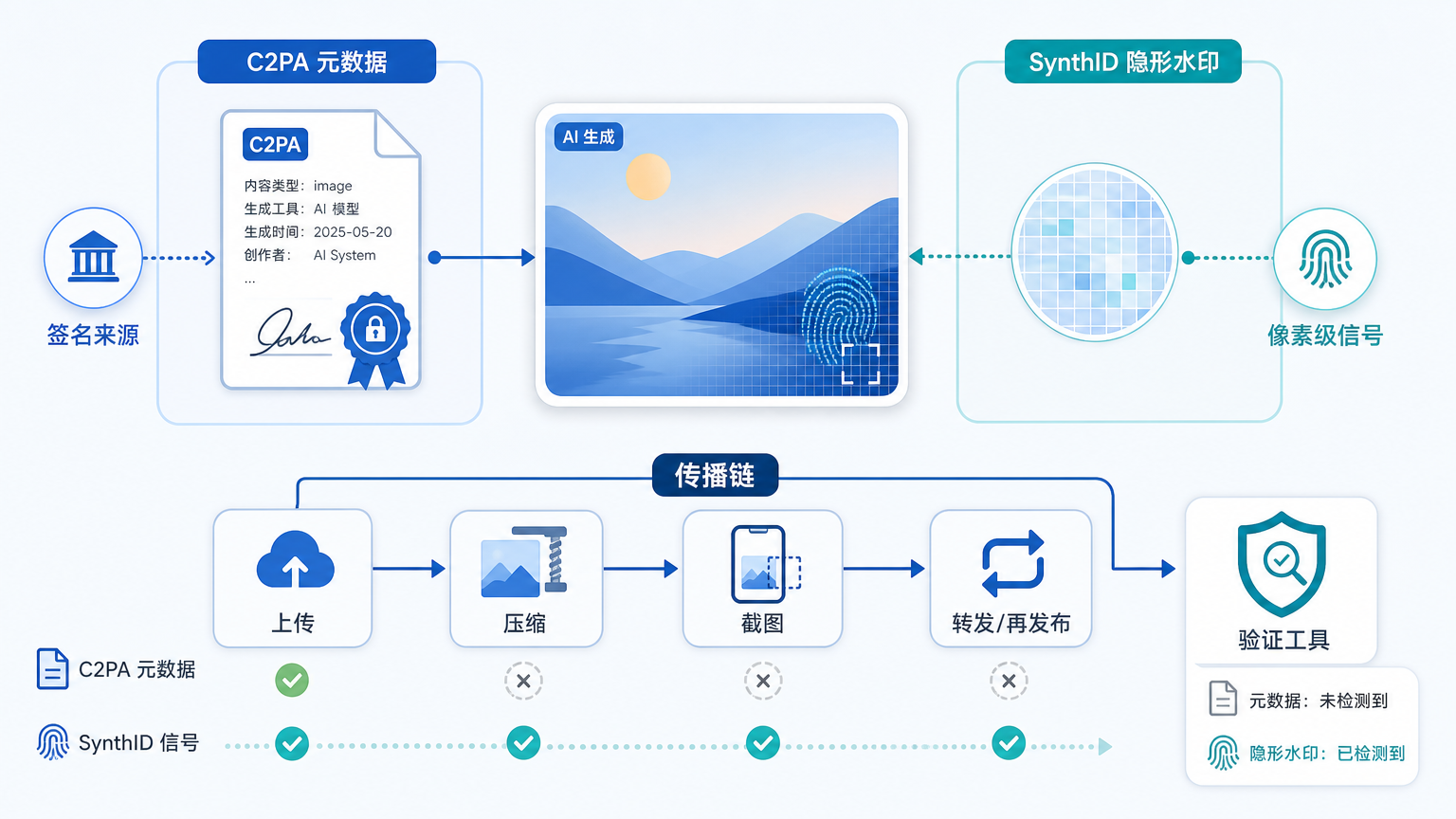
OpenAI 官方文章里主要讲了三层。
第一层是 C2PA。OpenAI 宣布自己成为 C2PA Conforming Generator Product。C2PA 全称是 Coalition for Content Provenance and Authenticity,是一套跨行业的内容来源标准。你可以把它理解成给媒体文件附上一份带签名的“来源说明”:这张图来自哪里,被什么工具生成或编辑过,相关信息由谁签名。
这种信息对新闻机构、内容平台和普通用户都有用。它比“AI 生成”四个字更细,因为它能提供上下文,而不是只给一个粗糙标签。
第二层是 SynthID。OpenAI 会给图片加入 Google DeepMind 的隐形水印。它不是角落里肉眼可见的 logo,而是嵌入在图像里的检测信号。OpenAI 说,这会从 ChatGPT、Codex 和 OpenAI API 生成的图片开始。
第三层是验证工具。用户可以上传图片,工具会检查里面是否有 Content Credentials、SynthID 这类来源信号。如果检测到了,它可以提示这张图是否来自 OpenAI 的生成系统。
这三层放在一起,才是这次更新的重点:元数据提供丰富信息,隐形水印提高耐传播性,验证工具让普通人有机会读懂这些信号。
元数据很好,但它太容易丢
C2PA 这类元数据方案很有价值,但它有一个天然弱点:它依赖文件携带信息。
现实传播环境没那么温柔。一张图从生成工具到用户眼前,可能经历聊天软件压缩、社交平台重编码、内容管理系统裁剪、编辑软件导出、截图再上传。任何一步都可能把元数据弄丢。
这不是 C2PA 做得不好,而是互联网一直就是这样运转的。很多平台过去并不关心保留图片元数据,有些还会主动清理元数据,以减少文件体积或规避隐私问题。
所以,只靠元数据不够。
SynthID 这类隐形水印的价值,在于它更贴近图像本身。它不一定能提供 C2PA 那么丰富的信息,但它可能在截图、压缩、尺寸变化之后仍然留下可检测的痕迹。
一个不太精确但好懂的类比是:C2PA 像随文件携带的履历表,SynthID 像藏在图像纹理里的指纹。履历表信息多,但容易在转手时丢失;指纹信息少,却更可能随着图像一起留下来。
OpenAI 这次没有说用 SynthID 替代 C2PA,而是把它们叠在一起。这个方向是合理的。AI 内容的传播路径太复杂,单一技术很难扛住所有场景。
为什么“用 Google 的水印”比水印本身更有意思
OpenAI 完全可以只做一套自己的水印系统,然后告诉用户:OpenAI 生成的图片,可以用 OpenAI 工具验证。
这当然也有用,但它解决的是自家生态里的问题。
现在它选择接入 Google DeepMind 的 SynthID,意味就不一样了。至少在图片溯源这件事上,两个最重要的 AI 阵营之间出现了基础设施层面的协作。
这对用户更有意义。因为用户最终看到的不是“OpenAI 生态内的一张图”,而是一张已经经过多轮传播的图片。它可能由 ChatGPT 生成,被发到 X,又被搬到小红书,再被公众号引用,最后出现在某个群聊截图里。看到它的人通常只关心两个问题:这是不是 AI 生成的?它从哪里来?
如果每家公司都用一套完全不同的识别体系,验证就会变得很笨重。平台要兼容很多种信号,用户也要记住很多个工具。A 家内容用 A 家工具查,B 家内容用 B 家工具查,这很难成为互联网级别的信任机制。
OpenAI 接入 SynthID 的信号是:内容溯源不应该只是某个产品的卖点,它更像是一层公共协议。
这有点像早期互联网里的 HTTPS、邮件认证、OAuth。用户最终需要的不是“某家公司说自己可信”,而是一套跨平台都能读取、传递和验证的机制。
验证工具不是“真假裁判”
OpenAI 这次也预览了一个公开验证工具。这个工具可以检查上传图片里是否存在 OpenAI 的来源信号,包括 Content Credentials 和 SynthID。
但这里要特别小心一个误解:这种工具不是“真假裁判”。
如果工具检测到信号,它能告诉你:这张图很可能来自 OpenAI 的生成系统,或者至少带有 OpenAI 的来源标记。这个结论有用。
如果工具没检测到信号,它不能证明这张图一定不是 AI 生成的。信号可能被剥离,图片可能来自其他模型,也可能经过了工具目前无法处理的编辑流程。OpenAI 官方也写得很谨慎:没有检测到元数据或水印时,工具不会直接下结论。
这个边界必须讲清楚。否则内容溯源工具很容易被误用成另一种“鉴定神器”。
它能回答的是“有没有找到来源线索”,不是“图里发生的事是不是真的”。一张由 OpenAI 生成的图片,可能描述的是虚构场景;一张没有水印的照片,也可能是真实拍摄。来源验证和事实核查是两回事。
对媒体来说,这种工具可以帮助编辑判断素材来源;对平台来说,它可以成为审核系统的一层输入;对普通用户来说,它能减少一部分判断成本。但它不能替代常识、上下文和事实核查。
难点不在生成端,而在传播链
讨论 AI 水印时,人们经常盯着几个问题:模型有没有加水印,用户能不能去掉,检测器准不准。
这些都重要,但最麻烦的地方其实在传播链。
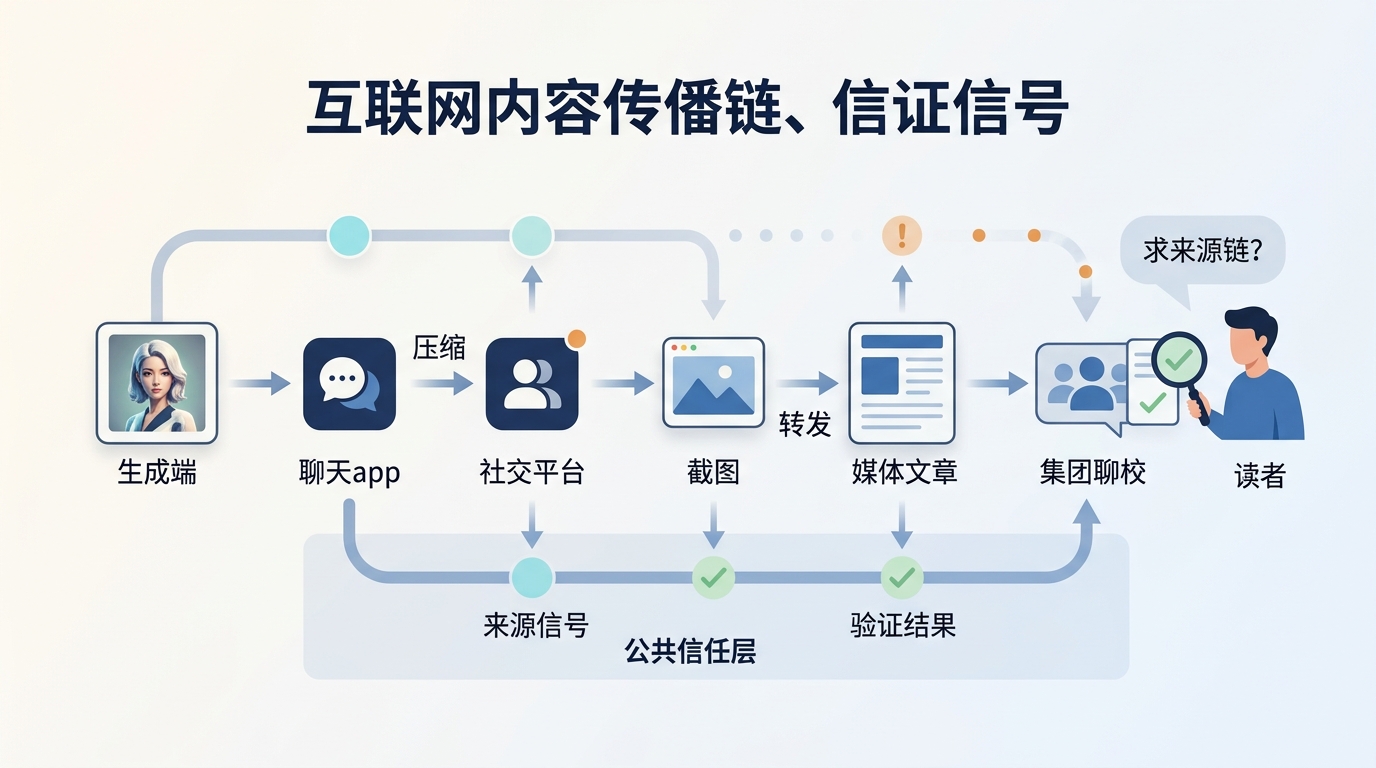
互联网内容不是放在文件柜里的原件,而是一条不断复制、压缩、裁剪、截图、转码的流水线。图片经过几轮传播后,原始文件早就不存在了。你看到的可能只是某个截图的截图,或者被平台重编码后的版本。
如果内容溯源要真正有用,就不能只靠 OpenAI 和 Google 在生成端努力。社交平台、媒体系统、图库、浏览器、操作系统、相机厂商、编辑软件,都要参与进来。至少,它们不能随手把来源信号全部抹掉;更进一步,它们还要能读懂这些信号,并用用户能理解的方式展示出来。
这也是 C2PA 这类开放标准的价值。它试图让不同工具理解同一种来源信息,而不是让每家公司各自发明一套格式。SynthID 的价值也类似:如果越来越多模型和平台支持可检测的隐形信号,验证工具就不必只服务于某一家厂商。
不过,这不会很快完成。内容溯源更像一次基础设施迁移:标准要统一,平台要接入,工具要支持,用户也要学会解释结果。
短期内,它不可能消灭假图。更现实的目标是:让带有可信来源信号的内容更容易被识别,让没有来源信号的内容在高风险场景里需要更多佐证。
普通创作者会受到什么影响
如果你只是偶尔用 ChatGPT 生成几张配图,这次更新可能看起来离你很远。但它会慢慢改变创作者和平台之间的关系。
过去,AI 图片的争议主要集中在版权、风格模仿、是否应该标注 AI。接下来,另一个问题会变得更常见:这张图的来源能不能被证明?
对正常创作者来说,来源信号有时是一种保护。你用 AI 生成了一张插图,并且明确标注用途。后来别人转载、裁剪、二次发布,来源信息至少可以帮助说明它来自一个生成流程,而不是某张伪造的现场照片。
对媒体和品牌来说,来源信号会进入风控流程。广告图、新闻配图、产品宣传图,如果带有可验证来源,内部审核会更清楚。反过来,在新闻、金融、公共安全这些高风险场景里,没有来源信息的图,可能会被要求提供更多证明。
平台压力会更大。它们不能只判断“这是不是违规内容”,还要处理“有没有来源信号、信号是否可信、信号丢失时怎么办”。这比给图片简单打一个 AI 标签复杂得多。
普通用户也需要调整预期。水印不是“真假标签”,而是“来源线索”。看到“由 OpenAI 生成”,不等于图中事件真实;看不到水印,也不等于图一定是真的。
公共信任层也可能变成平台权力
内容溯源听起来天然正确,但任何信任基础设施都会带来权力问题。
如果未来大平台都要求内容带有可验证来源,谁来定义“可信来源”?小工具、小模型、开源模型生成的内容,如果没有接入这些标准,会不会被默认看低?如果验证工具主要由头部模型公司提供,用户会不会被迫接受它们对来源的解释?
这些问题不能靠一句“开放标准”就解决。
C2PA 至少提供了一个跨行业协商的框架,避免每家公司都做一套黑盒规则。但开放标准本身不自动带来公平。接入成本高不高,验证过程透明不透明,开源社区能不能参与,平台愿不愿意保留和展示信号,都会影响它最后长成什么样。
OpenAI 接入 SynthID 是一个积极信号,因为它说明竞争对手之间愿意在内容来源问题上共享一部分底层能力。但下一步更关键:其他模型公司会不会接入?社交平台会不会展示?浏览器和操作系统会不会原生支持?开源模型有没有低成本的参与方式?
如果这些问题没有处理好,内容溯源也可能变成大公司之间的互认证俱乐部。
未来可能会分成三层
我更愿意把 AI 内容信任层拆成三层来看。
最底层是生成端标记。模型或应用在内容生成时写入 C2PA、SynthID 或其他来源信号,解决“来源信息从哪里开始”的问题。
中间层是传播端保留。社交平台、CMS、编辑软件、浏览器尽量保留、读取和传递这些信号,解决“来源信息能不能活过传播链”的问题。
最上层是用户端解释。验证工具、平台提示、浏览器 UI 把复杂信号翻译成人能理解的结果:检测到了什么,没检测到什么,这个结果意味着什么,又不意味着什么。
OpenAI 这次主要做了底层和上层:它生成信号,也提供验证工具。但中间层仍然取决于更大的生态。
所以,这条新闻不该只被理解为“OpenAI 给图片加水印”。更准确地说,它是 AI 内容来源系统开始跨公司拼接的一步。
结尾
OpenAI 接入 Google SynthID,不会让 AI 假图问题立刻消失,也不代表以后每张 AI 图片都能被准确识别。
它的意义在于,AI 公司开始承认:内容来源不能只靠“我生成的内容我来证明”。当 AI 生成内容越来越便宜、越来越逼真,互联网需要一套大家都能读、能传、能验证的来源机制。
以后我们判断一张图片时,问题不会只剩下“它看起来真不真”。还会多一个问题:它有没有可验证的来源链?
这条来源链不等于真相,但它可能会成为重新建立信任的起点。