
OpenRouter 刚完成 1.13 亿美元 B 轮融资。
公告里写得很漂亮:CapitalG 领投,NVentures、ServiceNow Ventures、MongoDB Ventures、Snowflake Ventures、Databricks Ventures 等参投;过去六个月,平台周处理量从 5 万亿 tokens 增长到 25 万亿 tokens;OpenRouter 称自己服务 800 万以上开发者,覆盖 400 多个模型。
这条新闻也上了 Hacker News 首页。当前条目显示,它拿到了 342 points 和 166 comments。一个模型调用基础设施产品能有这个讨论度,已经说明它不只是开发者圈里的小工具了。
不过,如果只把这件事写成“又一家 AI 公司融了大钱”,就有点浪费了。
我更关心的是另一个问题:为什么现在是 OpenRouter?为什么一个站在应用和模型之间、做聚合、路由、账单和故障切换的平台,会突然变得这么有价值?
答案可能不在融资金额里,而在 AI 应用开发的日常麻烦里。
过去大家做 AI 产品,第一反应往往是选模型:用 GPT,还是 Claude?用 Gemini,还是开源模型?但到了生产环境,问题会慢慢变成另一种样子:这个请求该走哪个模型?如果供应商限流怎么办?成本超预算怎么办?企业客户不允许数据留存怎么办?某个模型变贵或者变弱,系统能不能切走?
也就是说,AI 应用的入口,正在从“选模型”变成“选路由”。
以前接 AI,像是在押一个主力模型
过去两年,很多 AI 应用的架构其实很朴素:选一个主力模型,然后围绕它把产品做出来。
押 OpenAI,就围绕 GPT API 设计提示词、上下文和成本。押 Anthropic,就围绕 Claude 的长上下文、写作能力或代码能力来做体验。偏开源路线,就在 Llama、Qwen、Mistral、DeepSeek 这些模型里选一个部署方案。
早期这样做没问题。很多产品本质上就是“一个模型加一个界面”:用户输入一句话,模型返回一段内容。模型差距足够大时,选对模型就能把体验拉起来。
麻烦出现在产品长大以后。
比如,一个客服产品可能发现,八成请求用便宜模型就够了,但少数高价值客户的问题必须交给更强模型。一个编程工具可能发现,A 模型写代码更稳,B 模型解释报错更清楚,C 模型便宜到适合做批处理。再比如,某个供应商今天延迟突然飙升,或者晚上高峰期开始限流,产品不能跟着一起卡住。
成本也会改变心态。每月几百美元模型账单时,大家更在意上线速度;一旦账单涨到几万美元,模型调用就不再是可以忽略的小开销。你会开始追问:哪些请求真的需要强模型?哪些请求可以降级?哪些功能在偷偷烧钱?
这时,真正的问题已经不是“哪个模型最强”,而是能不能把模型当成一组可调度、可替换、可观察的资源来管理。
OpenRouter 这类平台的机会,就出现在这个转折点上。
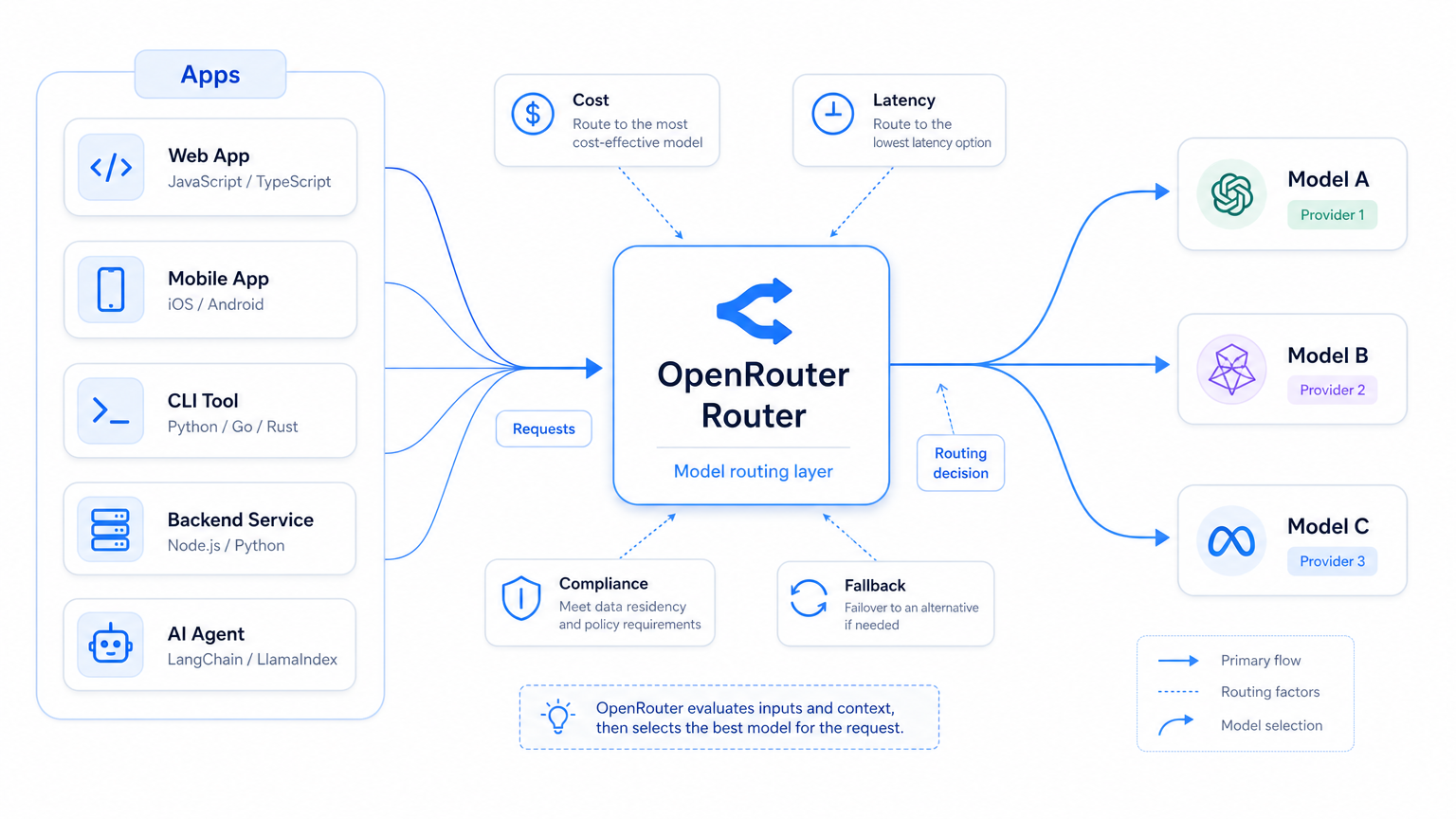
OpenRouter 不只是“模型超市”
从外面看,OpenRouter 很容易被理解成一个模型超市:一个接口,接很多模型,开发者不用分别注册一堆账号。
这个理解没错,但太浅。
在 B 轮融资公告里,OpenRouter 把自己放在应用、Agent 和模型提供商之间。它强调的能力不是“模型数量多”这么简单,而是路由、可靠性、成本优化、合规、企业 workspace、费用管理、guardrails、零数据保留、供应商级故障切换、质量感知路由。
这些词有点枯燥,但它们恰恰是生产环境里最真实的问题。
一个 Demo 只需要能调通模型。一个要收钱、要签企业客户、要稳定运行的 AI 应用,需要知道每一次请求去了哪里,花了多少钱,失败了怎么处理,日志能不能审计,数据会不会被保留,客户要求换供应商时能不能动得了。
这和云服务的发展有点像。刚开始上云时,大家关心的是“有没有机器”。后来系统规模起来,真正每天缠着工程团队的是负载均衡、监控、权限、账单、故障切换、区域部署。服务器当然重要,但只会开服务器还不够。
AI 模型也在走这条路。
模型本身仍然是核心能力,但当模型越来越多、价格越来越复杂、企业要求越来越细,应用和模型之间就需要一层操作台。它不负责把模型变聪明,而是负责决定:这次请求交给谁,出了问题切到谁,成本算到谁头上,以及这条调用链能不能被企业接受。
OpenRouter 想站的位置,大概就是这张操作台。
多模型不会只是过渡阶段
有人可能会说,等最强模型足够强以后,大家直接用最好的那个不就行了?
听起来省事,但真实软件世界很少这样运转。
公司不会因为一家云厂商好用,就永远不考虑备份;不会因为一个支付通道稳定,就完全不准备备用通道;也不会因为一个数据库强大,就把所有场景都塞进去。成熟系统通常都会慢慢长出抽象层,因为业务不喜欢被单点绑住。
AI 模型尤其容易出现这种情况。
一方面,模型能力变化太快。今天某个模型代码能力强,过几周另一个模型可能在长文本、图像理解或工具调用上更划算。模型厂商更新很频繁,能力边界也经常变化。把整个产品体验押在一个模型上,等于把一部分产品路线图交给供应商。
另一方面,不同任务本来就不该用同一个模型。用户意图分类、客服初筛、合同摘要、代码修复、研究报告、后台批处理,对质量、延迟、成本和合规的要求都不一样。用最强模型处理所有请求当然简单,但账单会很难看。
企业客户还会继续增加约束。有的客户不允许数据被训练,有的要求特定地区处理,有的要求供应商白名单,有的要日志留存,有的只关心预算上限。AI 一旦进入企业采购,就不只是模型回答得好不好,还要过采购、法务、安全和财务那几关。
所以,多模型不是“模型还不够强之前的临时方案”。它更像是 AI 应用成熟后的常态。
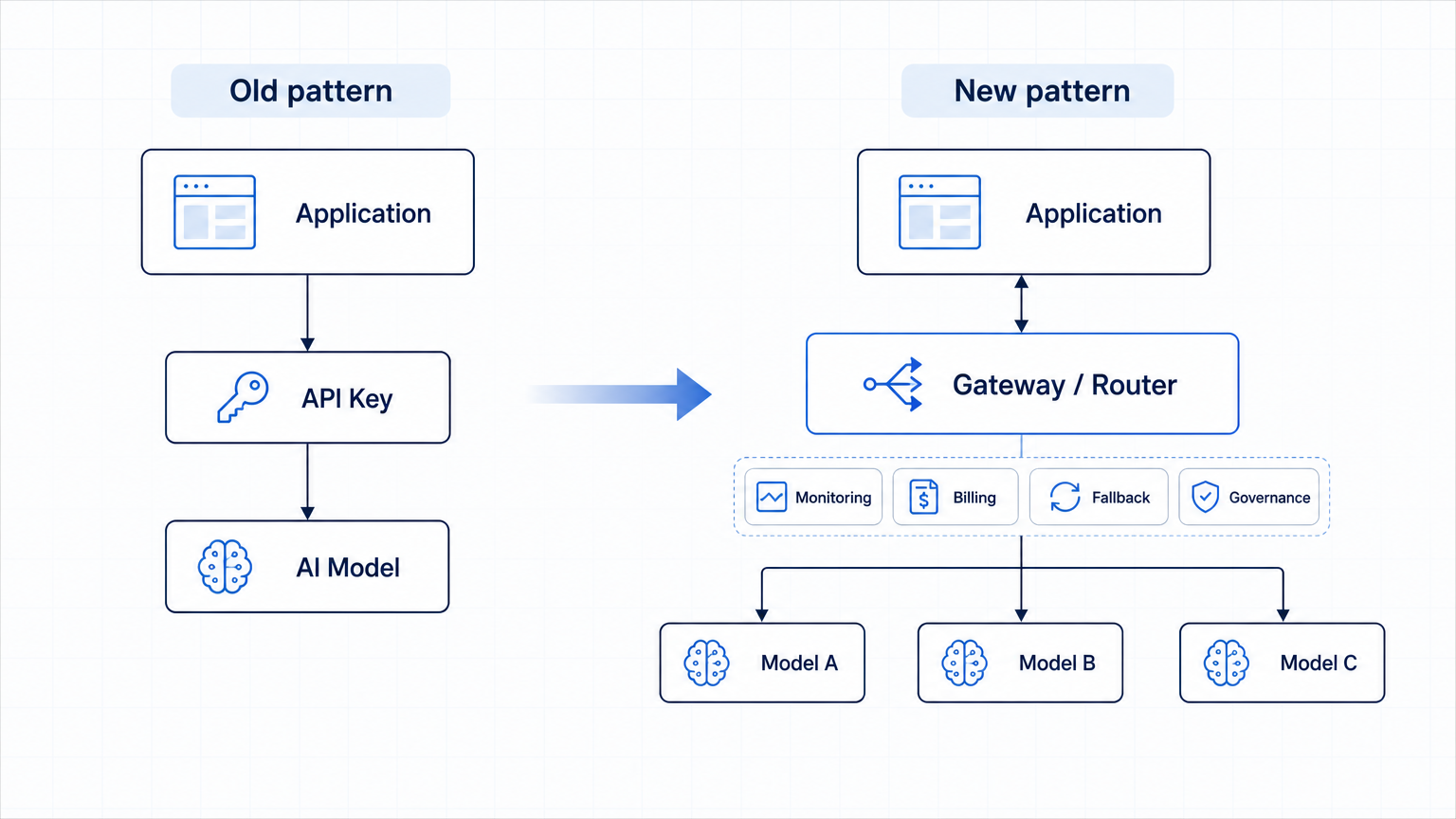
从 API Key 到 Gateway
很多团队第一次接入 AI,都是从一个 API Key 开始。
拿到 key,写几行 SDK 调用,调一段 prompt,功能上线。这个阶段越简单越好,没必要过度设计。
但真实用户来了以后,代码里的模型调用会慢慢变成一堆散点:这个功能接 OpenAI,那个功能接 Claude,后台任务用了另一个便宜模型;每个地方都有自己的错误处理和重试逻辑;账单来了以后,也很难说清楚到底是谁烧掉的。
再往后,模型升级也开始变麻烦。一个模型换版本,可能影响多个功能;一个供应商出问题,临时切换要改代码;某个客户要求数据不出某个供应商,工程团队还得专门绕一套逻辑。
于是 gateway 或 router 这类中间层会自然长出来。
它大概承担几件事:统一模型调用入口;根据任务、用户等级、成本预算和延迟要求选择模型;主供应商失败时切到备用模型;记录每个功能、团队或客户的消耗;处理数据保留、权限和审计;比较不同模型在真实任务里的表现。
OpenRouter、Vercel AI Gateway、LiteLLM、自建代理层,都是这类需求的不同解法。
区别不在于谁“绝对更好”,而在于团队想把控制权放在哪里。
OpenRouter 这样的托管平台,优势是快。模型多,接入省事,不用自己维护一堆供应商适配。Vercel AI Gateway 更贴近前端和应用部署生态。LiteLLM 或自建网关则适合更在意数据、日志、私有化部署和内部控制的团队。
小项目可以直接调 API。产品走到一定规模后,模型调用就不该只是散落在代码里的 SDK 调用。
投资方阵容透露了什么
OpenRouter 这轮融资的投资方名单值得多看一眼。
除了 CapitalG,里面还有 ServiceNow Ventures、MongoDB Ventures、Snowflake Ventures、Databricks Ventures、NVentures。这些名字背后连接的是企业软件、数据平台、云基础设施和 AI 计算生态。
这不能直接推导出 OpenRouter 会和它们达成具体合作,公告也没有这么承诺。但这至少说明,模型路由已经不只是开发者社区里的便利工具,而开始被企业基础设施玩家看见。
企业为什么会在意这件事?因为它们问的问题通常不浪漫,却很关键。
哪个团队用了多少 tokens?哪个客户的成本最高?请求失败有没有重试和降级?数据会不会被模型供应商保留?新模型上线前有没有灰度和回滚?合同里写的安全承诺,能不能落实到每一次模型调用?
这些问题听起来不像 AI 新闻里的主角,但它们决定 AI 能不能真正进入生产环境。
OpenRouter 的融资叙事,正是把自己放在这组问题中间:不是帮你尝鲜某个新模型,而是帮你管理一套多模型生产系统。
什么样的团队需要模型路由层?
不是每个项目都需要 OpenRouter,也不是每个团队都该立刻搭一层复杂网关。
如果你只是做个人工具、Demo、内部小脚本,直接调用一个模型 API 往往最合适。早期最重要的是把东西做出来,而不是先把架构画得很完整。
但有几种信号出现时,就该认真考虑模型路由层了。
第一,模型账单开始影响毛利。你不再只关心“效果好不好”,还要知道每个功能、每类用户、每个客户到底消耗了多少。否则 AI 功能越受欢迎,财务压力反而越大。
第二,AI 功能已经是核心体验。供应商故障、限流、价格变化不能再只是“等一下就好”。你需要备用模型、重试策略和降级路径。
第三,团队正在同时试多个模型。早期工程师手工切配置还行,后期如果没有统一评估和监控,模型实验很快会变成一堆临时分支。
第四,产品开始进入企业客户。客户一旦关心数据保留、审计、权限、预算和供应商风险,模型调用就变成治理问题。这个时候,路由层不只是工程优化,也会影响销售和交付。
第五,你希望保留谈判空间。系统天然支持多供应商替换,就不会在价格、能力和策略变化上完全被一家模型厂商牵着走。
这也是 OpenRouter 这类平台最实际的价值:它不保证每次调用都更便宜,但它给应用保留了选择权。
别把中间层当成新的神
当然,OpenRouter 不是银弹。
在应用和模型供应商之间增加第三方平台,本身也是一种新依赖。它可以降低你对单个模型的依赖,也可能让你依赖新的路由平台。
这里有几个风险不能忽略。
数据和合规是第一层。模型请求会经过路由平台,企业必须确认数据保留、日志、加密、访问控制和合规承诺是否符合自己的业务要求。OpenRouter 公告里提到了零数据保留等企业能力,但具体到某个行业、某个客户,仍然要一项项看。
调试是第二层。多模型路由越智能,问题排查越麻烦。同一个用户问题,今天走 A 模型,明天走 B 模型,效果变化到底来自模型、prompt、路由策略,还是供应商状态?如果日志和评估没做好,所谓智能路由也可能变成黑盒。
锁定是第三层。平台刚接入时很方便;调用量上来以后,你会越来越依赖它的模型列表、路由规则、账单体系和企业控制台。未来想换走,未必轻松。
所以,更稳妥的态度是:把模型路由层当成架构里的一个可替换组件,而不是新的单点信仰。
这也是为什么有些团队会选择 LiteLLM 或自建网关。它们未必最省事,但能把关键控制面留在自己手里。
最后拼的不是模型名字,而是模型管理能力
我倾向于把未来的 AI 应用调用链看成三层。
底层是模型供应商。OpenAI、Anthropic、Google、Meta、DeepSeek、Mistral、Qwen 等继续竞争模型能力、价格、上下文长度和多模态能力。
中间是路由和治理。OpenRouter、Vercel AI Gateway、LiteLLM、自建网关以及云厂商服务,会围绕这层继续竞争。它们解决的不是“哪个模型最聪明”,而是怎样把一堆模型变成稳定、可控、可审计的生产资源。
最上层才是用户真正看到的应用。客服、编程工具、内容生成、研究助理、企业工作流,用户最终关心的是结果是否稳定、价格是否可接受、出了问题有没有兜底。
普通用户以后可能越来越不关心底层用了哪个模型。就像你使用一个 SaaS 产品时,通常不会在意它跑在哪个云区域、用了哪家数据库。你只关心它快不快、稳不稳、结果好不好。
但对开发者和企业来说,模型选择不会变得不重要。它会从“产品早期选一个模型”,变成“运行过程中持续调度一组模型”。
这才是 OpenRouter 这轮融资最值得看的地方。
它提醒我们,AI 应用开发正在从接入模型,走向管理模型。模型仍然是发动机,但当发动机越来越多,真正影响驾驶体验的,往往是变速箱、仪表盘、维修系统和整套控制链。
最强模型会继续吸引注意力。可真正把 AI 做进生产系统的人,迟早都要回答另一个更朴素的问题:这些模型,谁来管?