
过去聊 AI,大家很容易被模型本身吸走注意力。
上下文又变长了,推理又变强了,Agent 又能多做几步了,视频生成又自然了一点。每一次发布会都像是在提醒你:软件还在狂飙。
但我最近越来越觉得,AI 接下来的麻烦可能不在屏幕里,而在屏幕背后那些很笨重的东西上:电、地、冷却塔、变压器、机柜、并网审批,以及一座座没有什么科技感的数据中心。
模型可以一夜之间更新,数据中心不行。
如果说过去两年的问题是“模型够不够聪明”,那接下来几年更现实的问题会变成:这些越来越聪明的模型,到底有没有足够多、足够便宜、足够稳定的地方运行?
这就是我说数据中心正在成为 AI 最大线下瓶颈的原因。
AI 的竞争,已经不只是模型竞赛
早期 AI 更像软件竞赛。
谁的架构更漂亮,谁的数据清洗得更好,谁的训练技巧更极致,谁就可能在下一轮模型榜单里往前冲一截。研究能力、工程调参、数据质量,这些是牌桌上的主要筹码。
大模型把这件事改了。
训练前沿模型要成千上万张高端 GPU 长时间协同;一个被大量用户调用的 AI 产品,需要一直在线的推理集群;多模态、实时语音、视频生成、长上下文 Agent,又会继续把算力需求往上推。
这些能力都要落到很具体的物理链条里:GPU 插进服务器,服务器放进机柜,机柜接上电和网络,热量要排出去,园区要拿到土地、许可和能源供应。
AI 看上去在云端,但扩张速度越来越受地面约束。
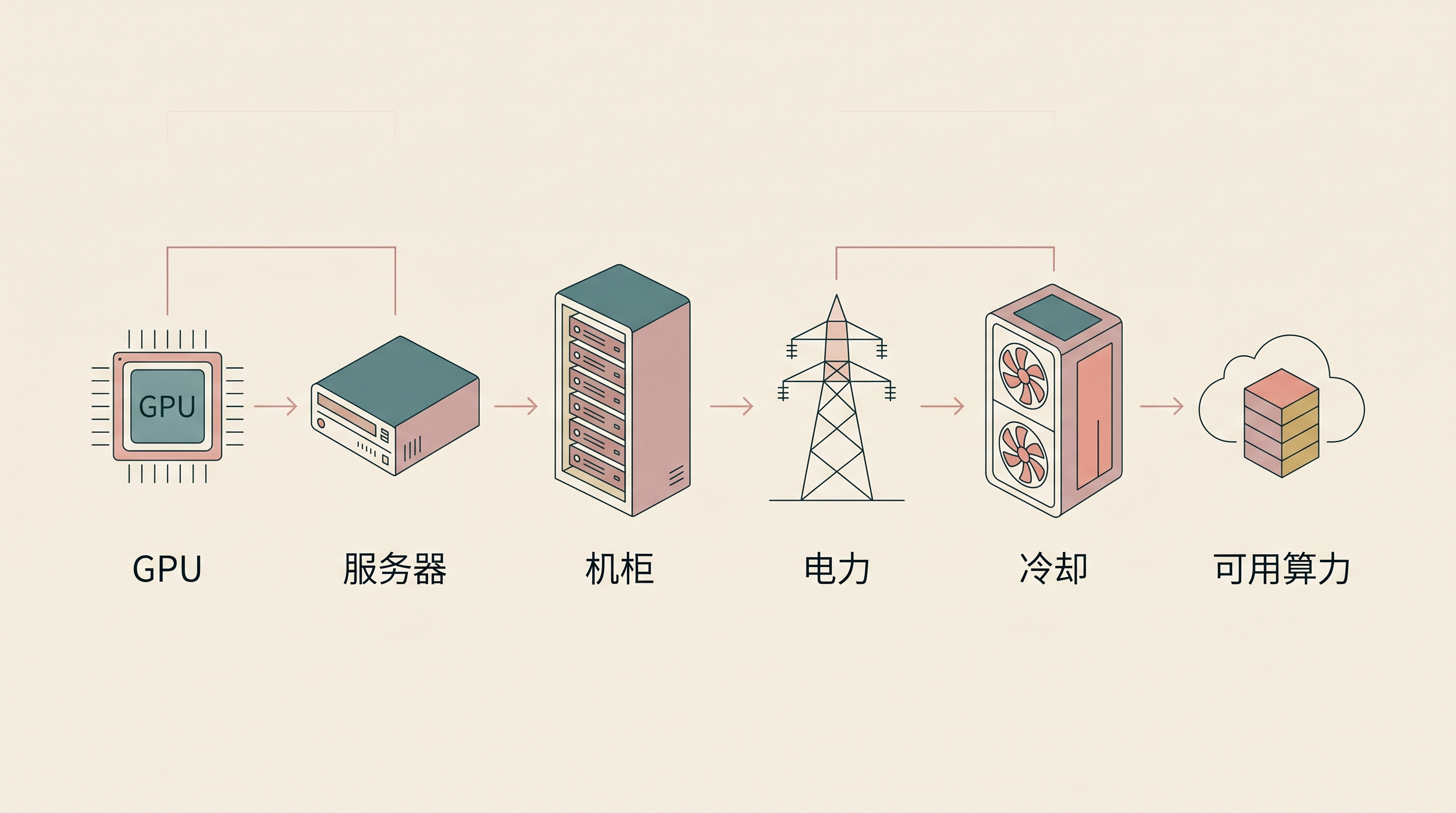
这和上一代互联网不太一样。搜索、社交、电商当然也吃数据中心,但一次请求的成本相对平滑。生成式 AI 更像把每一次用户交互都变成了一次实时计算。你问一句话,它不只是从数据库里取一条记录,而是在消耗 GPU 时间、电力和冷却资源。
用户越希望 AI 像一个随叫随到的同事,基础设施侧就越像制造业:产能、良率、交付周期、单位成本,一个都绕不开。
GPU 不是终点,可用容量才是
一谈 AI 基础设施,很多人会先想到 GPU 不够。
这当然对。高端 GPU 供给紧张,HBM、先进封装、晶圆产能都会影响交付。但只盯着 GPU,容易把问题看窄。更大的难点是:GPU 到货以后,能不能尽快变成稳定可用的算力。
一张 GPU 本身不是生产力。它要和服务器、网络、供电、冷却、机房运维、调度系统、软件栈一起工作。只要其中一个环节慢,账面上的芯片库存就还不是模型能力。
我觉得这里最容易被低估的是三件事。
电力排第一。
AI 服务器的功耗密度远高于传统机房。过去一个机柜几千瓦、十几千瓦已经不低,到了 AI 集群时代,高密度机柜会直接挑战配电、UPS、变压器和冷却系统。问题不只是电费贵不贵,而是当地电网能不能给你这么多稳定电力。
冷却排第二。
GPU 集群产生的热量不是普通空调随便吹一吹就能解决的。风冷还能用,但液冷、冷板、浸没式冷却正在从“高端配置”变成越来越现实的选项。冷却跟不上,性能、稳定性和硬件寿命都会被拖下水。
第三是建设周期。
软件可以今天写、明天发版,数据中心不行。选址、审批、采购、施工、并网、调试,每一步都可能按月计算。AI 公司如果等需求已经爆了再补基础设施,基本就晚了。
所以 AI 产业的问题正在从“有没有芯片”,变成“有没有足够强的工程和供应链能力,把芯片变成稳定在线的算力”。
推理可能比训练更难扛
外界谈大模型成本,最容易记住训练。
某家公司用了多少 GPU,训练了多少天,花了多少钱。这些数字很适合写进新闻标题,也确实昂贵。但从长期看,更持久压住数据中心容量的,可能是推理。
训练像建厂,推理像开工。
模型训练完,如果只是实验室成果,成本到这里基本就停了。可一旦它变成 ChatGPT、Claude、Gemini、Copilot、企业客服、代码助手、搜索入口、办公套件里的 AI 功能,推理成本就会随着每一次调用不断发生。
而且用户对 AI 的期待还在变重。
短文本问答已经不够了。用户希望 AI 读完整个代码库,分析几十页文档,实时处理语音,看懂图片,生成视频,调用工具,维持长期记忆,最好还能像同事一样连续干几个小时。
这一下味道就变了。
一次用户请求,背后可能是多轮规划、检索、模型调用、工具执行、结果验证。你看到的是一个回答,基础设施侧看到的是一串 GPU 账单。
这也是为什么推理优化会变成硬仗。模型蒸馏、缓存、路由、小模型协同、专用芯片、量化、批处理、边缘推理,本质上都在解决同一个问题:怎么用有限的数据中心容量,撑住更多真实需求。
能源会变成 AI 公司的隐形护城河
以前评价一家 AI 公司,常看模型能力、产品体验、人才密度、融资规模。
接下来可能还要加一条:它有没有能源能力。
这里说的能源能力,不是简单地付得起电费,而是能不能长期、稳定、低成本地拿到可扩展电力。电力合同、可再生能源配置、区域电价、并网速度、备用电源、碳排约束,都会慢慢进入 AI 竞争的核心账本。
这会让产业格局变得更现实。
云厂商天然占优,因为它们本来就有全球数据中心网络、基础设施团队和资本开支经验。大型科技公司也占优,因为它们可以提前锁土地、锁电力、锁供应链。反过来,纯模型创业公司即使研究能力很强,也可能在扩张阶段被基础设施卡住。
模型能力可以通过论文、人才流动和开源社区扩散得很快,数据中心能力没那么容易复制。
你可以挖研究员,可以买 API,可以复现训练方法;但你不能凭空变出一座已经并网、已经冷却、已经部署好高密度 GPU 的数据中心。
所以能源和数据中心会成为新的护城河。它不如模型榜单显眼,但更接近产业竞争的底层现实。
中美电力格局会影响 AI 产业节奏
聊 AI 数据中心,不能只看全球总量,还要看电力结构。美国和中国是两个最关键的 AI 市场,但它们面对的电力约束并不一样。
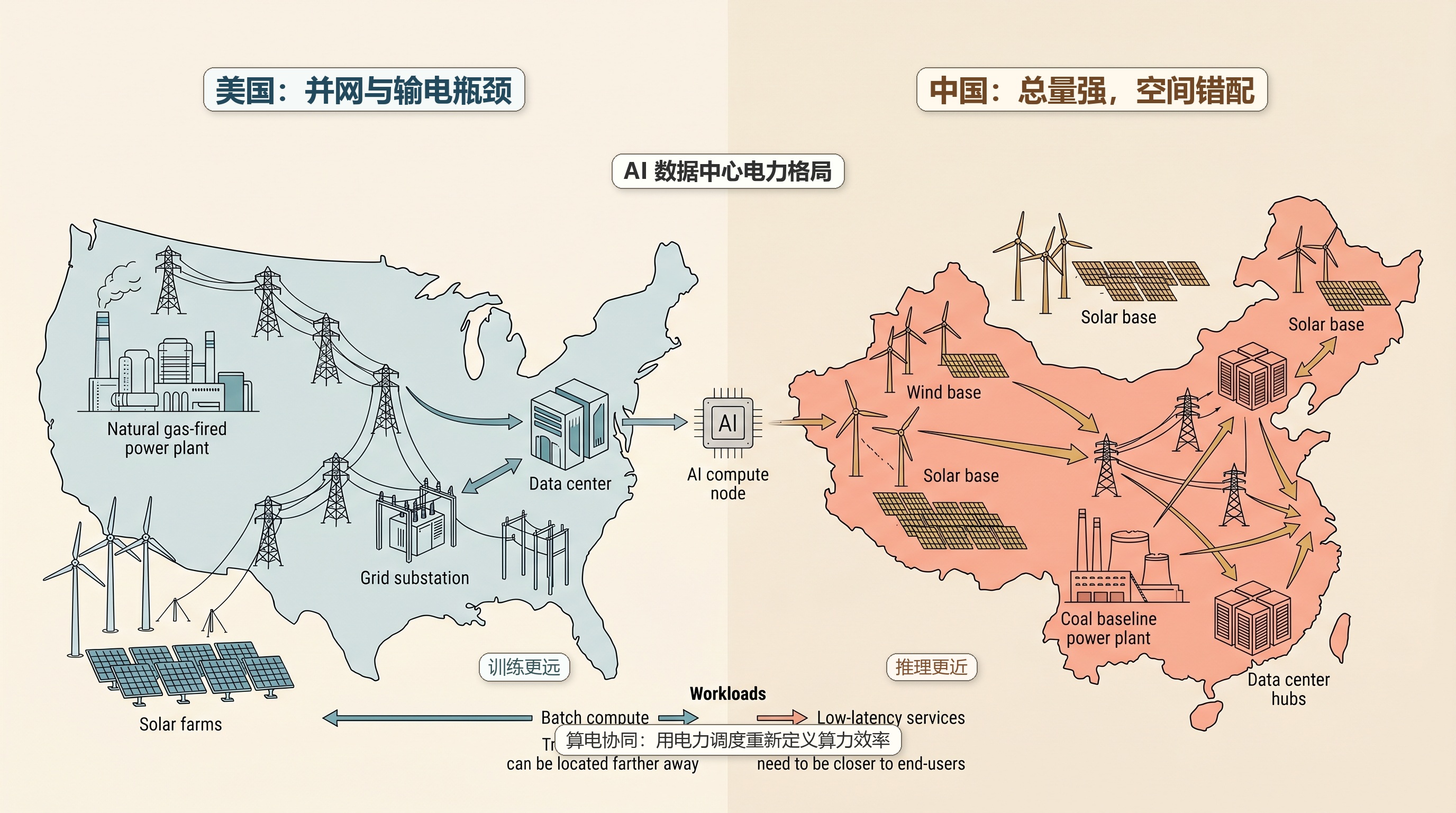
美国的问题更像是“新增负荷突然回来了”。
过去十多年,美国整体电力需求增长相对平缓,电网、发电侧和输电侧都习惯了低速增长。AI 数据中心、制造业回流、电动车和电气化一起出现后,负荷曲线突然变陡。EIA 的短期展望也提到,商业部门是美国电力需求增长的重要来源,其中就包括数据中心;Texas 等地区还同时承接了数据中心和制造业增长。
美国的优势是天然气发电占比高,调峰能力相对灵活,数据中心也更容易通过长期购电协议锁定风电、光伏和核电。但短板也明显:输电项目审批和建设周期长,很多数据中心不是缺理论电量,而是缺足够快接入电网的能力。对 AI 公司来说,选址会越来越像能源项目选址,不只是离用户近不近,也要看当地有没有可用电力、输电容量和政策配合。
中国的情况更像是“总量强,但结构和空间错配”。
中国有全球最大的电力系统,煤电提供了很强的基础负荷能力,风光装机增长也非常快。这个组合让中国在承接大规模算力时有一个明显优势:电力供给的绝对规模足够大,工程建设和产业配套速度也快。
但中国的难点在于东部需求和西部能源之间的距离。AI 应用、互联网企业、金融和制造业客户更多集中在东部沿海,而便宜电力、土地、风光资源和自然冷却条件更多在西部、北部。于是“东数西算”的逻辑就出来了:把一部分对时延不那么敏感的训练、离线分析、批处理任务放到西部,把需要低时延交互的推理和业务系统留在靠近用户的区域。
这会带来一个很现实的分工:训练可以更远,推理最好更近。
大模型训练任务对时延不敏感,更适合放在电价低、土地足、冷却条件好的地方;但搜索增强、办公助手、代码补全、语音交互这类在线推理,对网络延迟和服务稳定性更敏感,很难全部搬到偏远地区。也就是说,中国能通过算力枢纽缓解一部分压力,但不可能把所有 AI 负载都简单“西迁”。
中美还有一个共同点:AI 数据中心都会倒逼电力系统更市场化、更精细化。
过去数据中心关心的是 PUE,是机房内部效率。接下来更关键的是“算电协同”:什么时候训练,在哪里训练,用什么电训练,能不能跟风光出力、储能、峰谷电价和电网调度配合。谁能把算力任务调度和电力系统调度结合起来,谁就能把同样一度电榨出更多模型能力。
所以,中美竞争不只是模型竞争,也不是简单的 GPU 竞争。美国要解决并网、输电和新负荷增长问题;中国要解决能源空间分布、低碳转型和东西部算力协同问题。两边都绕不开电力,只是瓶颈长得不一样。
基础设施约束会改写产品形态
数据中心瓶颈不会只留在后台,它会一路传导到产品设计里。
免费 AI 会越来越难维持。只要每一次高质量回答都对应真实计算成本,平台就必须在体验和成本之间做选择。免费用户看到的限额、更慢的响应、更弱的模型,甚至广告和商业化设计,本质上都是算力账单在前台露头。
模型路由会变成默认能力。不是所有问题都值得上最强模型。简单任务交给小模型,复杂任务交给大模型;本地能处理的在本地处理,必须上云的再上云;低价值请求压成本,高价值请求保质量。未来很多 AI 产品表面是聊天框,里面其实是调度系统。
企业 AI 也会重新评估私有化和混合部署。把所有请求都扔给云端大模型,早期最省事,但调用量起来以后不一定最划算。代码、客服、文档分析、内部知识库这些高频场景,只要规模足够大,本地化或者专属实例就会重新进入讨论。
产品设计也会变克制。视频生成、实时语音、多 Agent 协作、长时任务执行,都不是“能做就上”。每一个功能背后都有成本曲线。基础设施越紧,产品经理越不能只看酷不酷,还要看单位算力能不能换来足够价值。
AI 产品会从炫技优先,慢慢转向算力效率优先。
开发者和创业者要提前算这笔账
这个趋势看起来是巨头之间的战争,但普通开发者和创业者也躲不开。
如果你在做 AI 应用,不能只看模型效果。一个 demo 用最强模型跑得很惊艳,不代表它能在真实用户规模下成立。早期就要设计降级策略、缓存、任务队列、异步处理和成本监控。
如果你在做企业方案,混合架构会越来越重要。规则能解决的不上模型,小模型能解决的不上大模型,低敏数据上云,高敏数据留在本地。这个思路听起来不性感,但它决定项目能不能长期跑下去。
如果你是个人开发者,以后也会看到更多“算力分层”的产品体验。免费层、标准层、专业层之间的差异,不只是功能权限,而是真实算力资源的差异。
如果你关注 AI 产业链,视野也可以从模型公司往外挪一点。数据中心、能源、冷却、芯片封装、网络设备、调度软件,都可能成为下一阶段更扎实的位置。AI 的机会不一定只在“做一个更聪明的模型”,也在“让模型跑得更便宜、更稳定、更规模化”。
AI 进入了更重的阶段
数据中心成为瓶颈,不一定说明 AI 要熄火。
我反而觉得,这是 AI 从实验室技术变成工业系统的信号。只有需求真的起来,基础设施才会紧;只有用户持续使用,推理成本才会变成核心问题;只有产品进入办公、编程、客服、教育和内容生产这些日常场景,电力和机房才会突然显得这么重要。
很多技术都是这样走过来的。
早期大家问能不能实现,中期问能不能规模化交付,后期才开始拼单位成本、网络覆盖和供应链稳定性。铁路、电网、云计算、移动互联网,都有类似的阶段转换。
AI 现在大概正在跨过这个分水岭。
未来几年,模型能力当然还会继续进步。但决定 AI 普及速度的,不只是实验室里的下一代架构,也包括现实世界里的变电站、冷却塔、土地审批、光纤网络和数据中心工程队。
AI 的故事不再只发生在云端。
它也发生在一座座沉默的机房里,发生在电网负荷曲线里,发生在每一度电、每一台服务器、每一次并网审批和每一个机柜的散热能力里。
限制 AI 能跑多远的,可能不是发布会上的参数,而是这些不太上镜的线下基础设施。
参考来源
- IEA:《Electricity 2024》及执行摘要中关于数据中心、AI 和加密货币用电需求到 2026 年可能翻倍的预测。
- IEA:《Energy supply for AI》,关于数据中心相关发电需求从 2024 年约 460 TWh 增长至 2030 年超过 1,000 TWh 的情景分析。
- Goldman Sachs:《AI is poised to drive 160% increase in data center power demand》,关于 AI 推动数据中心电力需求增长的研究。
- Goldman Sachs:《AI to drive 165% increase in data center power demand by 2030》,关于全球数据中心功率需求、AI 工作负载占比和电网投资瓶颈的分析。
- McKinsey:《AI power: Expanding data center capacity to meet growing demand》,关于全球数据中心容量需求到 2030 年可能快速增长的测算。
- McKinsey:《How data centers and the energy sector can sate AI’s hunger for power》,关于美国数据中心电力需求、能源基础设施和投资机会的分析。
- U.S. EIA:《Short-Term Energy Outlook: Electricity, Coal, and Renewables》,关于美国电力需求、商业部门增长和数据中心相关负荷的预测。
- U.S. EIA:《New solar plants expected to support most U.S. electric generation growth》,关于美国天然气、煤电和可再生能源发电结构的说明。
- 中国信通院:《中国绿色算力发展研究报告(2024年)》,关于中国数据中心机架规模、用电量、PUE 和绿色算力发展的测算。
- 中国信通院:《绿色算力发展研究报告(2025年)》,关于 2024 年中国数据中心用电量、PUE、绿电使用和算能协同的分析。