
我将通过一个系列分享,手把手的教大家打造一个完全本地化的,免费的,企业级知识库问答系统
当使用外部模型或服务时,我们的私有数据,用户问题,都会被发送给第三方那我们就要面临私有数据暴露给别人的风险,甚至会导致数据泄露本地化会让我们的数据就更安全
另外随着我们的业务发展,如果模型不能很好的满足我们需求的时候我们可以很方便的对本地模型其进行微调以达到更好的适配
这样就既兼顾了安全,又兼顾了灵活性
知识库问答的使用场景其实非常多,我随便举 2 个商业系统的例子
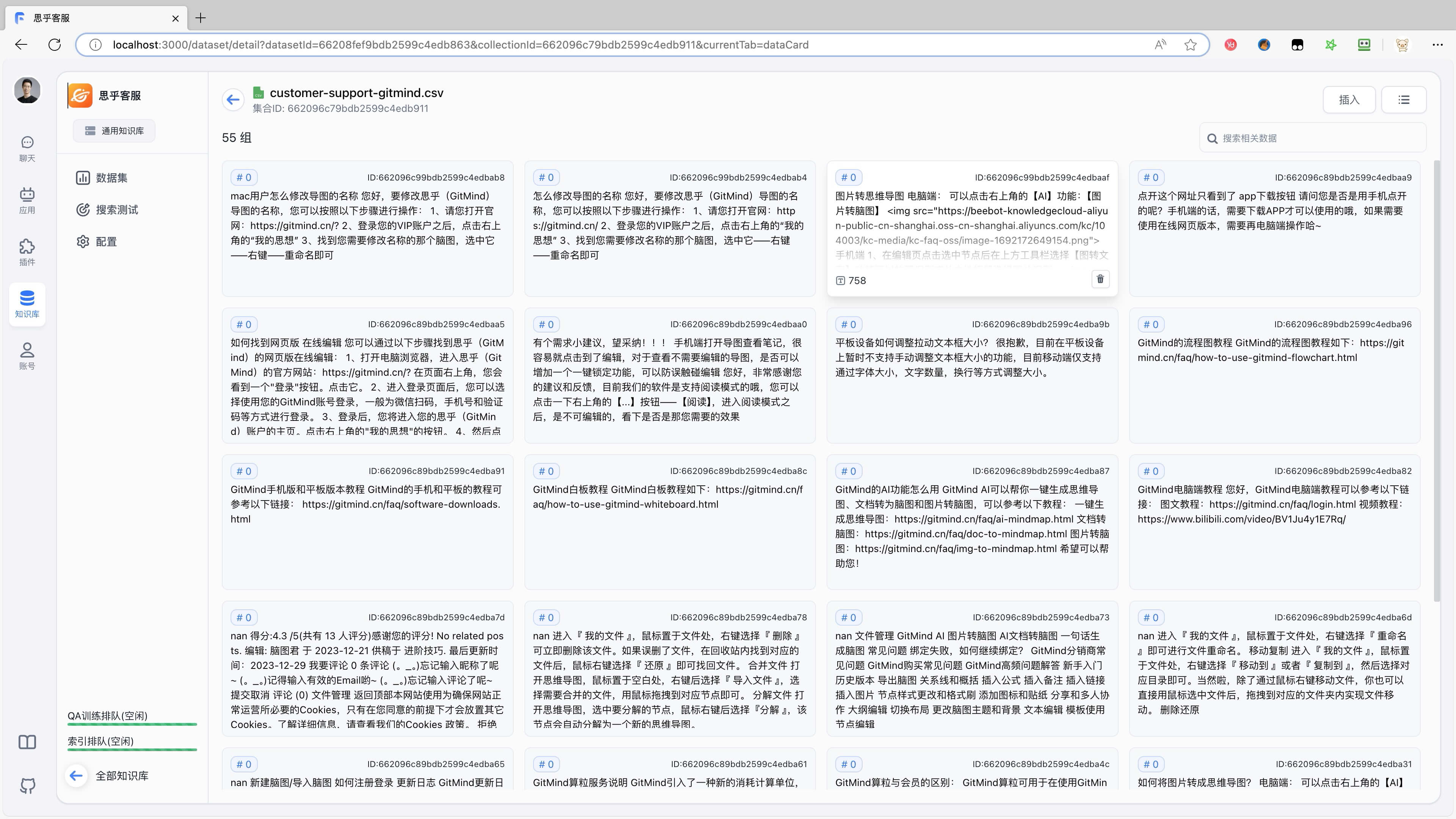
比如对个人,可以用来 整理笔记、论文解读、文献检索、文档问答 等等。这里我用轻闪 PDF 的文档对话 https://lightpdf.cn/chatdoc 来演示一下效果。
我们随便上传一个 PDF 文档,等文档解析完成后,我们就可以通过提问的方式,对文档里面的内容进行解读,可以很快的从文档中找到我们想要的内容, 大大提高我们查看文档的效率。
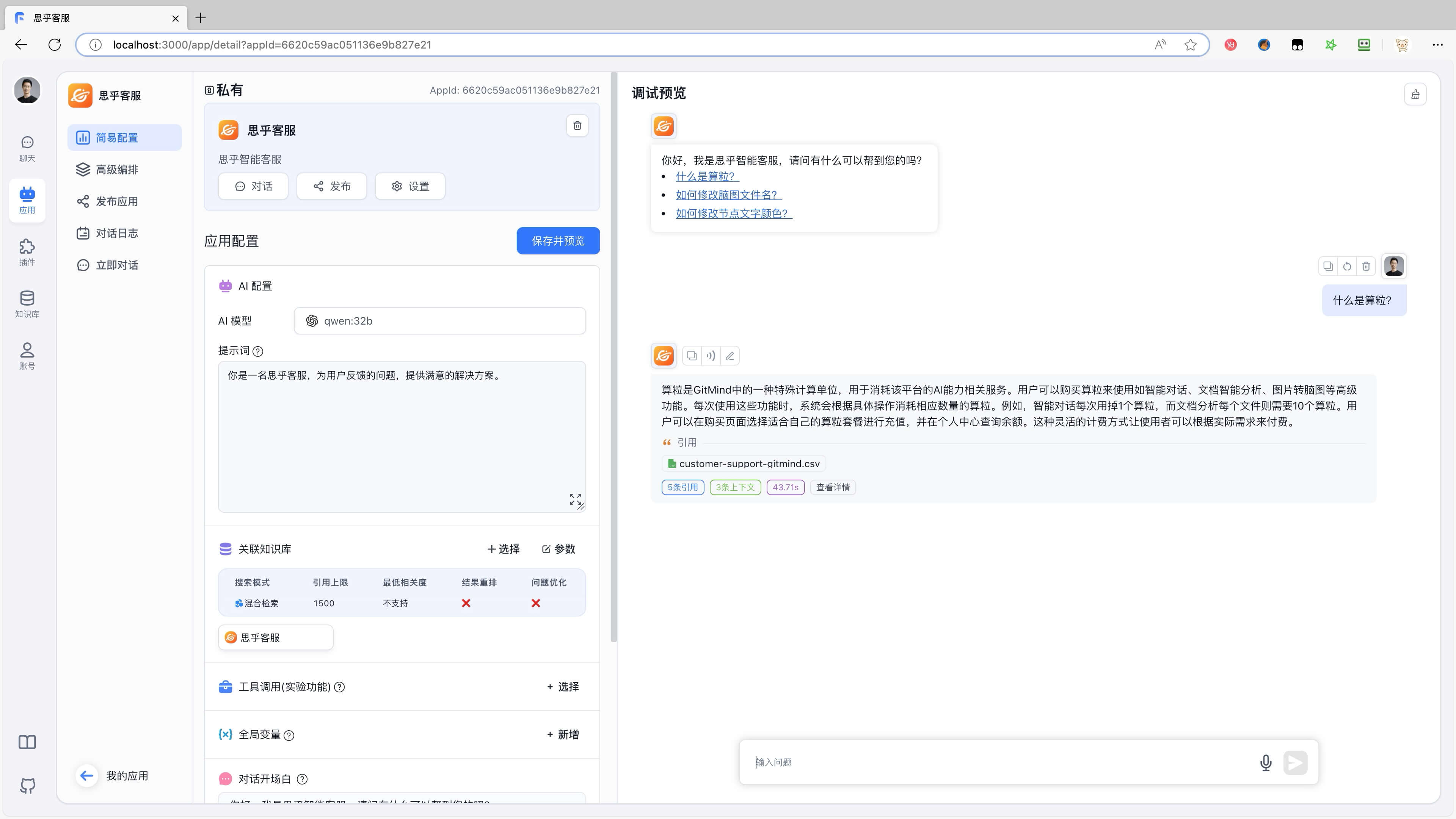
对企业,可以用来做 智能客服,数据沉淀 或者 数字员工 等等,同样我用思乎的在线客服 https://gitmind.cn 来演示一下。
我们可以向客服提问,AI 就会准确的回复我们的问题,而这些问题的答案,大模型本身是没有的。因为大模型既不了解我们的业务,也不知道我们的数据,这些 AI 回复的答案,都是从企业的知识库里面获取的。这样我们就实现了一个 7 x 24 小时的智能客服, 不仅为企业降本增效,还提高了客户的满意度。
| 环境 | 最低配置 | 推荐配置 |
|---|---|---|
| 测试 | 2 核 2 GB | 2 核 4 GB |
| 100 w 组向量 | 4 核 8 GB 50 GB | 4 核 16 GB 50 GB |
| 500 w 组向量 | 8 核 32 GB 200 GB | 16 核 48 GB 200 GB |
| 1000 w 组向量 | 16 核 48 GB 200 GB | 32 核 64 GB 500 GB |
整个的系统搭建,都是基于这个架构图来进行的
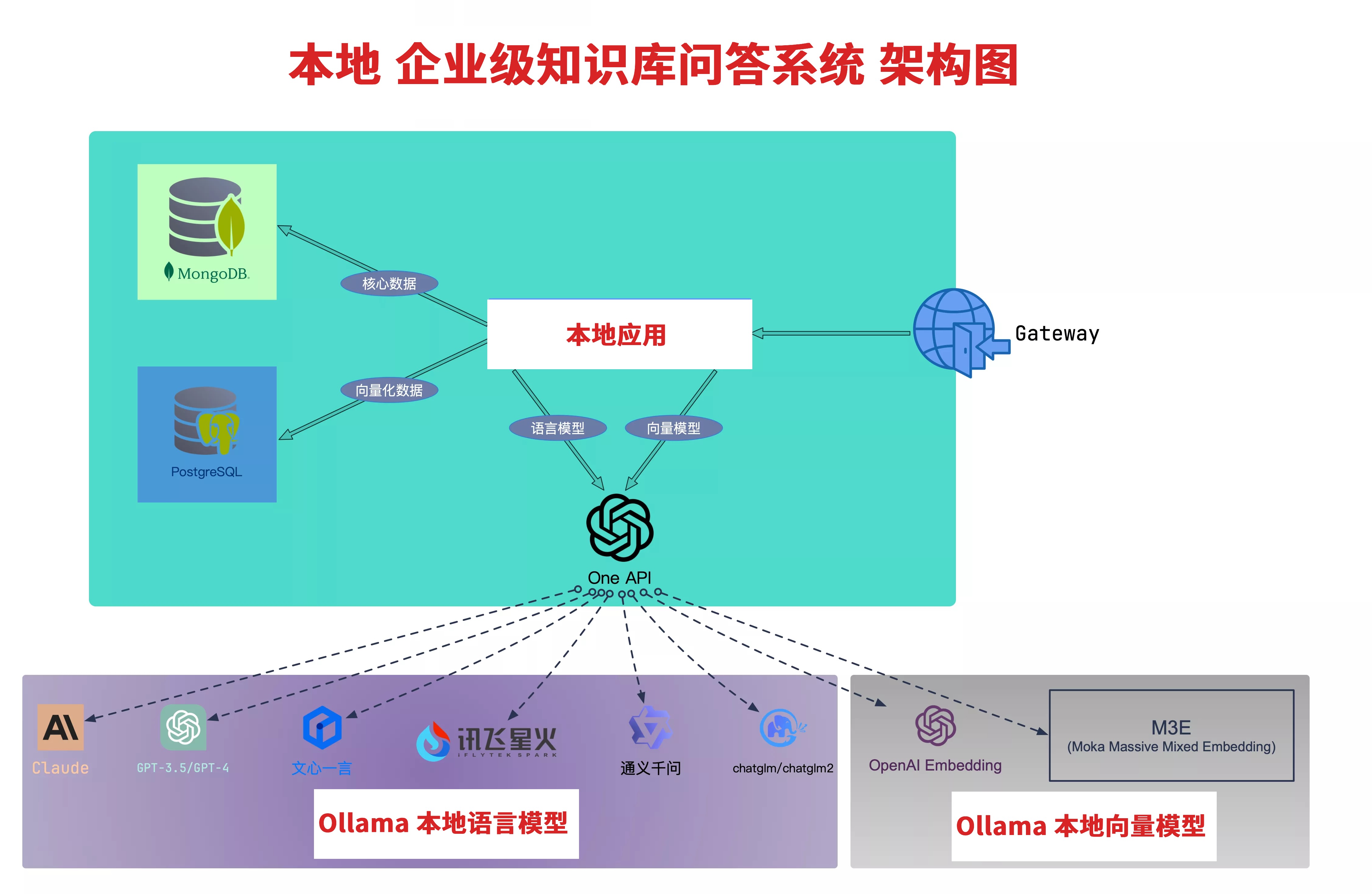
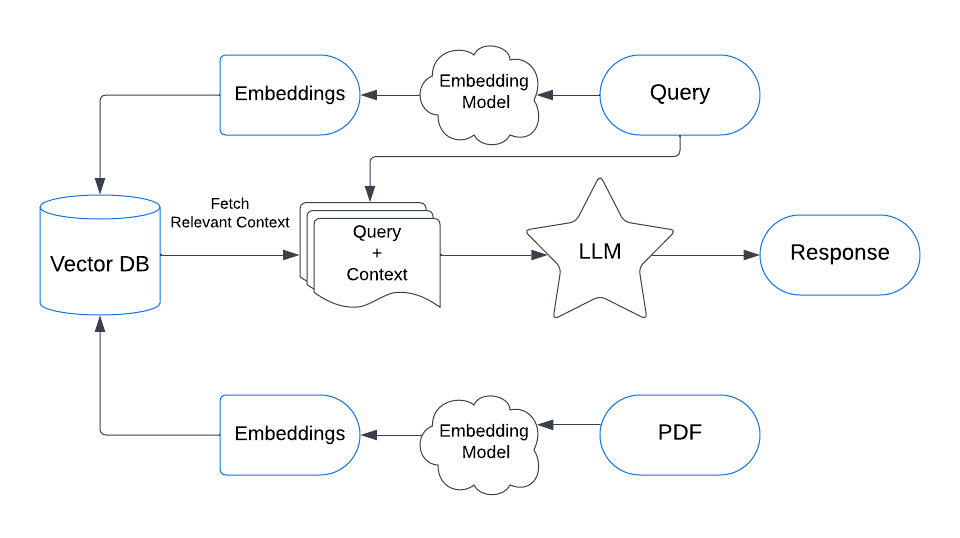
- 检索:Retrieval,通过向量模型,或者多种混合检索方式,从知识库中检索出相关的文档
- 增强:Augmentation,通过将检索到的文档,附加到提示词中,进行增强。也即 ICL(In Context Learning)
- 生成:Generation,通过大语言模型,生成答案
- 有助于减轻大模型的幻觉,提高大模型回复的准确性
- 与微调不同,RAG 提供了一定的可观察性和可检查性
- 成本低,好实施
下载 Docker 并安装 https://www.docker.com/products/docker-desktop/
下载 Ollama 并安装 https://ollama.com/
我使用阿里的通义千问作为演示,根据自己的电脑配置情况,选择合适的模型。
总体来说,模型是越大,效果越好,但是对电脑的配置要求也越高
- 4 b 模型要 3 GB 内存
- 7 b 模型要 8 GB 内存
- 13 b 模型要 16 GB 内存
- 70 b 模型要 64 GB 内存
特别注意:你如果要用于商业用途,需要申请授权,否则只能用于个人学习
申请商用授权: https://dashscope.console.aliyun.com/openModelApply/qianwen
下载模型
|
|
测试 API 请求
等模型下载和安装好后,执行下面的命令,测试 API 请求是否成功
Mac/Linux 下执行:
|
|
Windows 下执行:
|
|
下子 embedding 模型
我使用了 DmetaSoul 的中文 Embedding 模型,该模型 号称 在 MTEB 中文榜单取得开源第一的成绩: https://huggingface.co/DMetaSoul/Dmeta-embedding-zh/blob/main/README_zh.md
下载模型
|
|
测试 API 请求
等模型下载和安装好后,执行下面的命令,测试 API 请求是否成功
Mac/Linux 下执行:
|
|
Windows 下执行:
|
|
安装FastGPT及其依赖
1. 下载 docker 文件 和 config 文件
你可以手动下载,放到一个文件夹里面
- docker-compose. Yml: https://harryai.cc/kbqa/docker-compose.yml
- config. Json: https://harryai.cc/kbqa/config.json
也可以直接执行下面的命令,自动下载
|
|
2. 启动 docker
|
|
注意
- 第一次启动会有点慢,因为要拉取镜像,后面启动就会很快了
- 如果第一次启动失败,可以多次执行
docker-compose up
3. 访问 FastGPT 和 OneAPI
你第一次访问,系统里面是没有数据的,截图里面的数据,是我测试的时候已经创建好了的。
FastGPT
用户名 root,密码 1234(密码可以在 docker-compose.yml 环境变量里设置 DEFAULT_ROOT_PSW 进行修改)
OneAPI
用户名 root,密码 123456
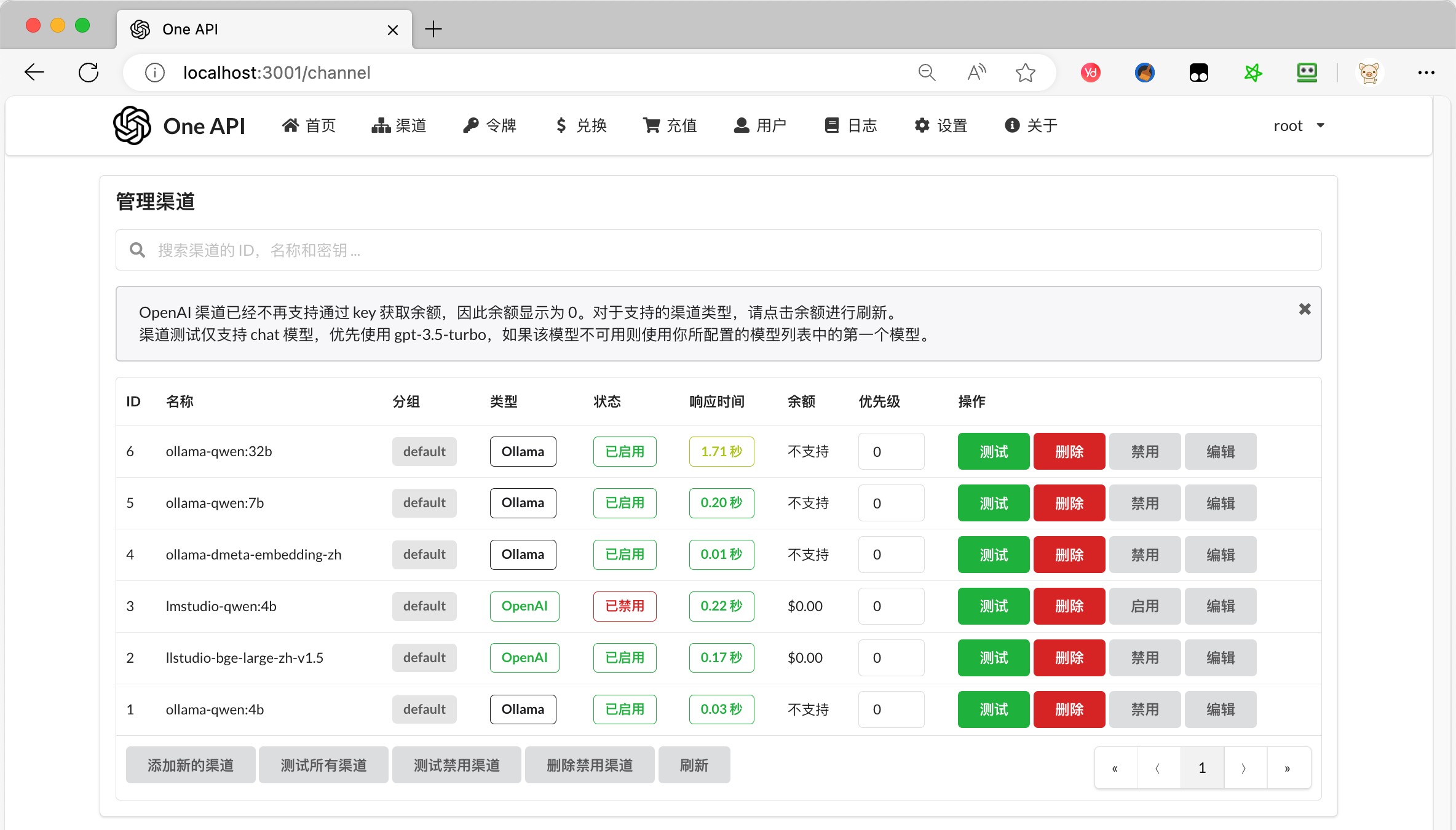
配置OneAPI
添加模型:http://localhost:3001/channel
1. 配置大语言模型
- 类型:Ollama
- 名称:ollama-qwen: 7 b
- 模型:输入自定义模型名称,
qwen:7b - 密钥:随便填,比如 123
- 代理:http://host.docker.internal:11434
2. 配置Embedding向量模型
- 类型:Ollama
- 名称:ollama-dmeta-embedding-zh
- 模型:输入自定义模型名称,
shaw/dmeta-embedding-zh**,比如 - 密钥:随便填,比如 123
- 代理:http://host.docker.internal:11434
特别注意:
- 模型 必须和 ollama 安装的模型名称保持一致,可以使用
ollama list命令查看 - 代理地址 必须是 http://host.docker.internal:11434,这样 OneAPI 才能访问到 ollama
默认情况下,Docker 使用的是桥接模式启动服务,即容器使用 Docker 自己创建的虚拟网络,容器之间可以相互通信,但是它们无法直接访问宿主机(即你的电脑)上的网络服务。
但是 Ollama 是运行在你的电脑上的,而 OneAPI 是运行在 Docker 容器里面的,所以 OneAPI 无法直接访问 Ollama。
Docker 官方提供了一种支持方案,可通过指向 host. Docker. Internal 来指向宿主机的 IP。
参见官方文档:从容器连接到主机上的服务
配置FastGPT
我们先创建一个简单的应用,实现一个基本的 AI 对话,目的是测试 OneAPI 的接口以及 Ollama 的接口是否正常。