
马斯克和 OpenAI 的官司,原本看起来又是一场典型的硅谷道德剧。
马斯克说 OpenAI 背离了当初的非营利承诺,从“造福全人类”走向了微软绑定和商业优先;OpenAI 则反击说,马斯克早就想把 OpenAI 纳入自己的商业版图,只是没能成功。
如果事情只停在这里,其实不算新鲜。
但最近庭审里出现了一个更有意思的细节:据 Semafor、36 氪等媒体报道,马斯克承认 xAI 的模型训练中曾“部分使用”OpenAI 模型相关能力。换成行业里更常用的说法,就是模型蒸馏。
这一下,事情的味道就变了。
当然,你可以把它理解成“马斯克翻车”:一边起诉 OpenAI,一边又让自己的 AI 公司向 OpenAI 的模型学习。这个角度很抓眼球,也确实有讽刺意味。
但我觉得更值得看的,不是马斯克这个人又制造了什么戏剧性场面,而是这件事暴露了大模型行业一个越来越尴尬的现实:领先模型本身,正在变成后来者追赶它的训练材料。
也就是说,大模型公司的护城河,可能正在被自己的输出一点点冲开。
蒸馏不是简单抄作业,而是让强模型当老师
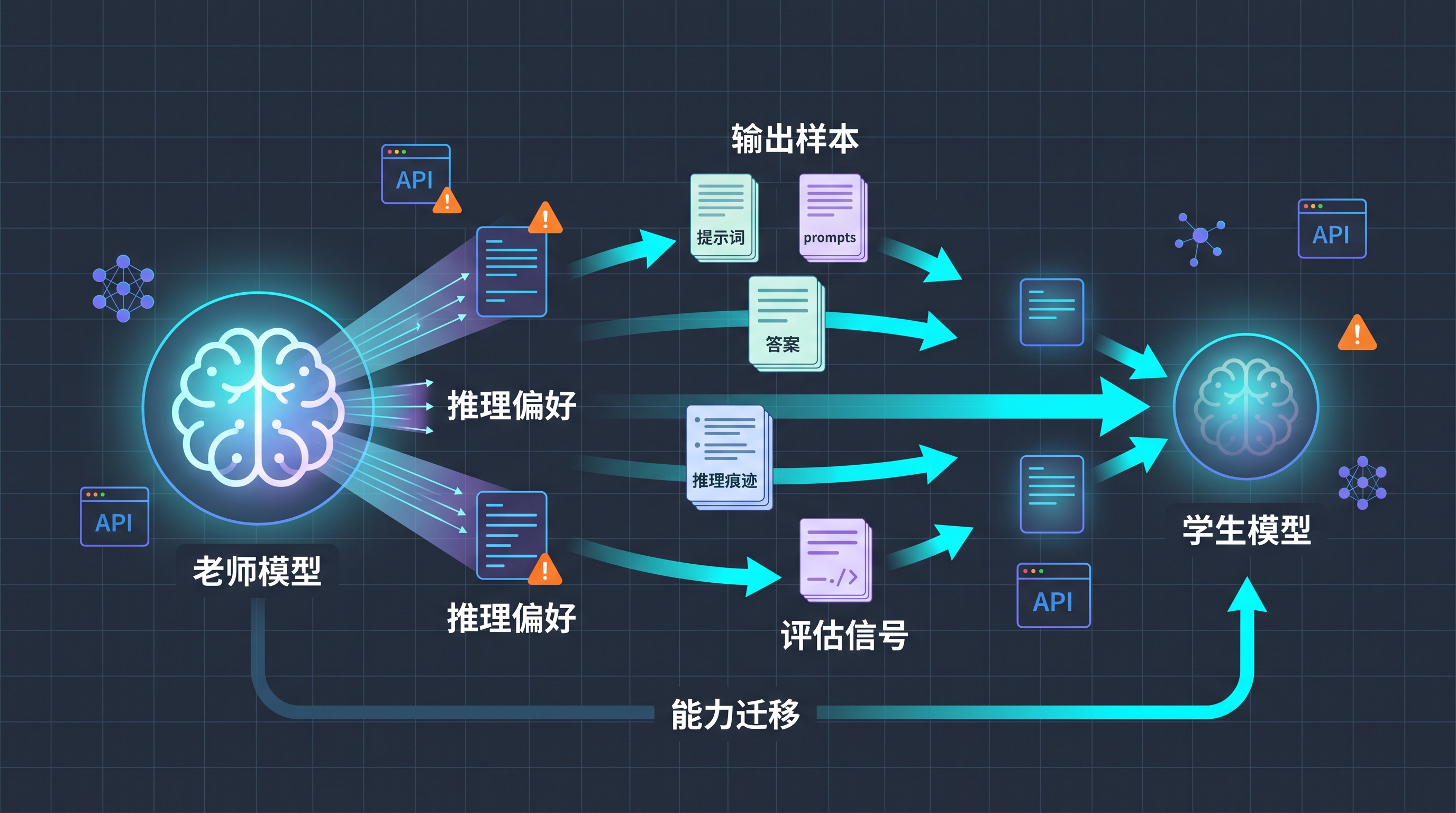
先说清楚,模型蒸馏不等于把 OpenAI 的模型参数偷出来,也不等于把 ChatGPT 原样复制一遍。
更准确地说,它是一种“学生模型向老师模型学习”的训练方式。
老师模型通常更大、更强,也更贵。学生模型未必能看到老师模型的内部结构,但可以通过大量输入和输出样本,学习老师模型在不同问题上的回答方式、判断偏好、推理路径和边界感。训练完成后,学生模型可能更小、更便宜、响应更快,同时在一些特定任务上接近老师模型的表现。
这件事在机器学习里并不新。过去它常被用来压缩模型、降低部署成本,本来就是一种很常见的工程手段。
问题是,到了大模型时代,蒸馏的商业含义变了。
今天的“老师模型”不再只是论文里的实验模型,而是价值数百亿美元、靠海量数据和算力堆出来的商业资产。它的 API 输出、聊天回答、代码生成、推理过程,背后都是公司投入巨大成本形成的能力。
如果竞争对手可以通过大量调用、收集输出,再拿这些内容训练自己的模型,那么领先者的优势窗口就会被明显压缩。
所以 OpenAI、Anthropic、Google 这些公司才会越来越在意 API 使用条款、批量抓取、自动化调用,以及模型输出能不能被拿去再训练。
过去平台担心的是内容被爬。
现在模型公司担心的是能力被爬。
这场争议最大的讽刺:所有人都在用别人的东西训练自己
xAI 被质疑使用 OpenAI 模型能力,乍一看是一个很清楚的道德问题:你不能一边骂别人,一边又拿别人当老师。
但如果把镜头拉远一点,大模型行业本身就站在一个更复杂的基础上:几乎所有大模型,都曾从互联网上吸收过海量人类内容。
新闻、论文、代码、论坛问答、博客、图书、图片、视频字幕、公开网页,这些内容共同构成了模型能力的底层土壤。很多创作者、媒体、开发者和机构,也早就问过类似的问题:你们训练模型时,有没有得到授权?有没有付费?模型生成的内容,会不会反过来挤压原作者?
所以,当一家模型公司指责另一家公司“用我的模型输出训练你的模型”时,它真正触碰到的问题其实更大:
AI 时代,到底什么样的学习算合理借鉴,什么样的学习算商业侵权?
模型读了公开网页,是学习还是盗用?
模型读了另一个模型的回答,是学习还是蒸馏?
一个开发者用 ChatGPT 生成大量样本,再拿去微调自己的开源模型,和公司级别的蒸馏相比,边界又在哪里?
这些问题没有那么容易回答。
更麻烦的是,大模型的学习不像传统软件那样好举证。代码抄袭可以比对函数、变量、结构;文章抄袭可以看文本相似度。但模型能力被“学走”之后,往往体现在概率分布、回答风格、评测表现和行为偏好里。
它不是一段一段复制过去,而是被吸收到另一个系统里。
这会让法律、合规和商业竞争都变得非常棘手。
大模型的领先窗口正在变短
这件事之所以重要,是因为它解释了一个我们已经能观察到的趋势:模型公司的领先窗口正在变短。
过去,一家公司如果训练出明显领先的模型,可能会拥有半年甚至一年以上的优势。后来者要重新收集数据、筹集算力、训练模型、调参评测,才能慢慢追上来。
现在情况不一样了。追赶路径变多了。
可以学习公开论文和开源社区的工程经验。
可以用合成数据,让强模型生成训练样本。
可以通过蒸馏,把领先模型在某些任务上的能力迁移出来。
也可以干脆绕开通用能力竞赛,专攻代码、搜索、客服、办公、法律、医疗这些垂直场景。
结果就是,模型领先不再像一座稳定的城堡,更像一段不断缩短的时间差。
你刚发布一个强模型,市场还没完全消化,竞争对手就已经开始研究你的输出、拆解你的能力、复刻你的行为模式。几个月后,类似能力可能就会出现在另一个模型里,价格更低,限制更少,甚至还会被包装成“更开放”“更中立”“更懂用户”。
所以今天的大模型公司,很难只靠一句“我的模型更聪明”长期建立壁垒。
聪明会被追赶,价格会被打下来,API 会被替换,评测榜也会不断刷新。
更难的是:你能不能把模型能力嵌进用户每天离不开的工作流里。
护城河会从模型参数转向产品和分发
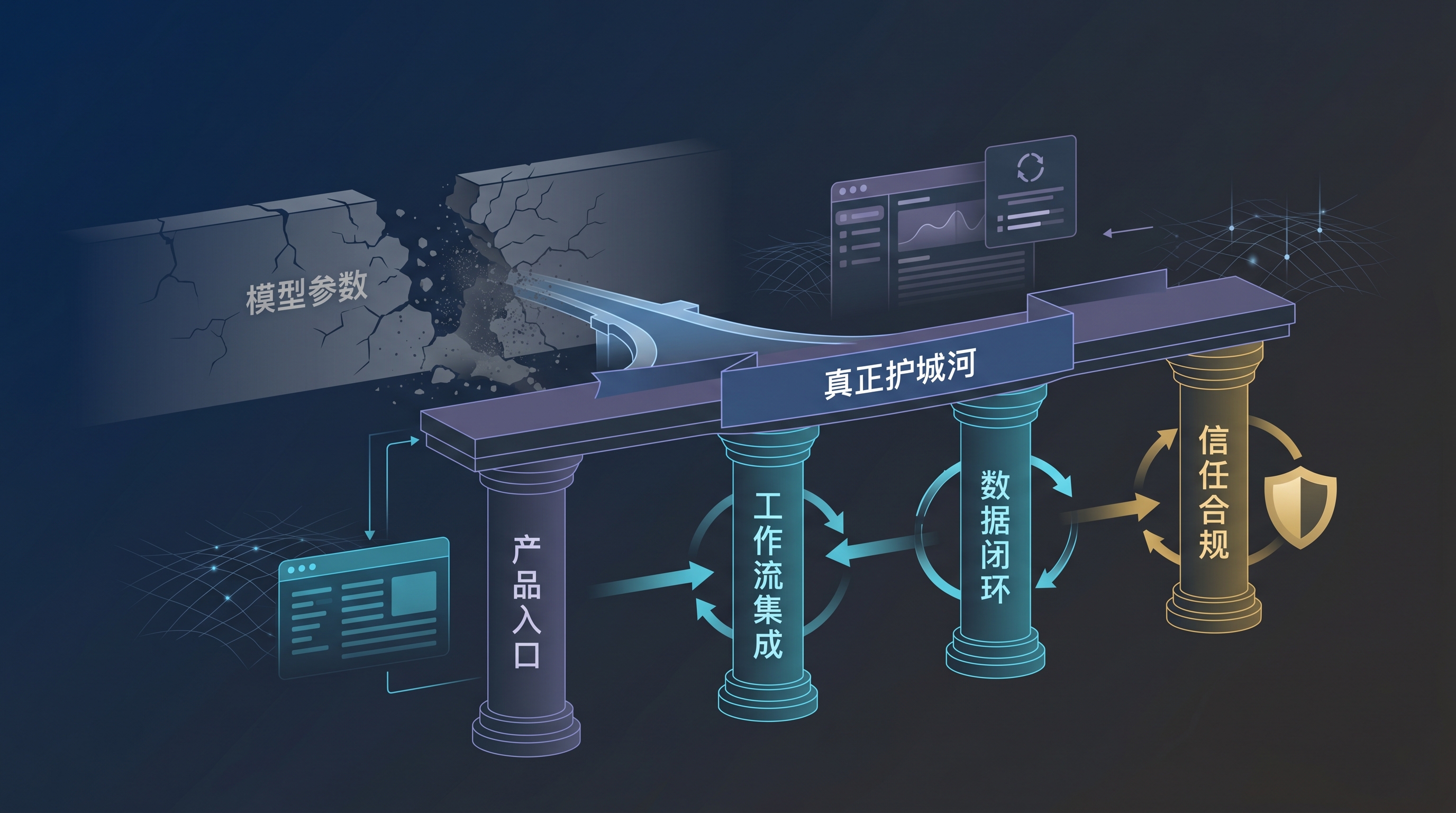
如果模型本身越来越容易被追赶,那么大模型公司的护城河会转向哪里?
我觉得至少有四个方向。
第一个是产品分发。
ChatGPT 的优势不只是模型强,而是它已经成了普通用户理解 AI 的默认入口。很多人并不会先关心 GPT-5、Claude、Gemini 的参数差异,他们只是养成了一个习惯:有问题,先打开 ChatGPT。这个入口本身就是壁垒。
第二个是工作流集成。
Claude Code、Cursor、Microsoft Copilot、Google Workspace AI,本质上都不是单纯在卖模型,而是在争夺工作流里的位置。模型一旦进入 IDE、终端、文档、邮件、会议和浏览器,就不再只是一个可替换的 API,而变成了用户完成任务的操作界面。
第三个是数据闭环。
谁拥有真实用户反馈、真实任务结果、真实企业场景数据,谁就能持续改进模型和产品。公开数据大家都能学,合成数据也能批量生成,但高质量的私有任务数据和反馈闭环,没那么容易复制。
第四个是信任和合规。
企业客户不会只问模型强不强,还会问数据会不会被拿去训练、审计能不能通过、权限能不能控制、输出能不能追责。在这些场景里,模型能力只是入场券,合规和交付能力才决定谁能拿到预算。
所以,蒸馏争议背后的结论可能是:模型参数本身越来越难成为长期护城河,真正的护城河会转移到入口、工作流、数据、合规和生态上。
OpenAI 不只做模型,还要做 ChatGPT、企业版、GPT Store、Agents 和各种集成,就是这个原因。
Anthropic 押注 Claude Code、MCP、Artifacts 和企业安全,也是同一套逻辑。
Google 把 Gemini 塞进搜索、Android、Workspace 和云服务,是因为它天然拥有分发场景。
xAI 也不可能只做 Grok,它必须绑定 X 的实时内容、分发网络和马斯克的商业生态。
模型像发动机,但平台才是车。
发动机领先,当然重要。但如果发动机只是摆在那里,很快就会被拆解、学习和追赶。只有当它装进一辆用户每天都要开的车里,才真正变成生意。
最后留下的问题:谁有资格指责谁?
马斯克承认 xAI 使用 OpenAI 模型相关能力,当然会削弱他在这场官司里的道德位置。
但这件事不应该只停留在“马斯克又打脸了”。它更像是一次行业自曝:大模型公司的竞争,已经进入了互相学习、互相借力、又互相指责的阶段。
每家公司都想保护自己的模型输出,不希望别人拿去训练竞争模型。
但每家公司也都在不同程度上受益于互联网、开源社区、用户反馈,以及前人模型留下的知识。
这不是一个能靠“谁更高尚”解决的问题。
接下来更关键的,可能是几条边界能不能慢慢建立起来。
比如,模型输出能不能被用于训练竞争模型,什么情况下需要授权。
比如,平台 API 如何识别和限制大规模蒸馏式调用。
再比如,模型公司如何向创作者、企业和用户说明自己的训练来源与数据使用方式。
在这些边界清晰之前,大模型行业大概率还会维持这种矛盾状态:大家都想保护自己的护城河,但也都在从别人的河里取水。
这才是这次 xAI 蒸馏争议最有价值的地方。
它提醒我们,大模型竞争的核心问题,已经不只是“谁的模型更强”。
而是当强模型本身也会变成训练材料时,谁还能守住真正不可复制的东西。