
这两天看 Anthropic 那篇长任务 Agent 的工程文章,我最先想到的不是“Claude 又能连续干几个小时了”,而是另一件事:我们可能太习惯把 AI 编程的问题归结为模型了。
模型不够强,所以换模型。结果不好,所以改 prompt。上下文不够,所以塞更多文件。过去几年,这几招确实有用。但当 Agent 开始被允许连续工作几个小时,问题会变得不一样。
Anthropic 这次反复提到一个词:Harness。
直译成“支架”有点生硬,但意思很准确:模型本身只是核心执行器,真正让 Agent 能稳定做事的,是围在它外面的一整套工程支架。工具、权限、沙箱、测试、浏览器、日志、规则文件、评估器、人工确认,这些都算。
换句话说,Prompt 关心“怎么问”,Context 关心“给它看什么”,Harness 关心的是:当 AI 开始替你行动时,它怎么被约束、怎么被验证、怎么被纠偏。
这才是长任务 Agent 最难的地方。
长任务的坏结果,通常不是一上来就坏
短任务里的 AI 错误很好抓。
让它写一个函数,测试红了就是红了;让它解释一段代码,讲错了你很快能看出来;让它改一个小 bug,diff 也不会太大。
长任务麻烦得多。
一个 Agent 连续工作 1 小时、3 小时、6 小时,它不一定会在第一步失败。它可能一开始方向没问题,后来逐渐偏离需求;中途为了补前面的坑,又引入几个新抽象;最后交付时,还能给你一段很完整的总结,说自己已经完成了。
这类失败最烦,因为它看起来不像失败。
Anthropic 在长时间应用开发实验里提到过几种典型现象:上下文会变脏,计划会漂移,模型会提前收尾,自我评价会过于宽松。BestBlogs 今日精选里对 AI Engineer 相关分享的概括更直白:长 session 容易出现 context rot、规划缺陷和输出 sycophancy。
这些词听起来像论文里的术语,放到日常开发里其实很熟悉。
你让 Agent 修一个 bug,它改到一半开始重构半个项目;你让它加一个小功能,它顺手加了你没要求的抽象层;你让它检查是否完成,它认真说“已经完成”,你打开页面发现按钮根本点不动。
这不是“模型完全不会做”。很多时候它确实做了一大半。问题在于,它缺少一个持续把它拉回正轨的系统。
这就是 Harness 的位置。
Agent 不是模型本身
O’Reilly 那篇《Agent Harness Engineering》里有一句话很直接:Agent = Model + Harness。
这个说法有点像废话,但我觉得它很有用。因为很多人聊 Agent 时,还是会不自觉地把 Agent 等同于模型。
模型强,Agent 就强。模型弱,Agent 就弱。
现实没这么简单。
一个裸模型不是 Agent。一个聊天框也不是 Agent。真正能做事的 Agent,至少需要一堆模型之外的东西:它能调用哪些工具,不能调用哪些工具;它能不能读日志;能不能跑测试;能不能开浏览器;能不能改数据库;失败之后有没有重试;完成之前有没有验收。
这和软件工程团队很像。
一个优秀程序员当然重要,但团队产出不只看个人能力。有没有测试,有没有 CI,有没有 code review,有没有监控,有没有回滚机制,有没有清晰的需求和验收标准,这些东西都会决定结果。
AI Agent 也是一样。
如果你只给它一句“帮我做完这个功能”,再给它一堆工具权限,然后等它自己判断完成,本质上是在让一个非常自信、又没有责任边界的实习生独自负责需求、设计、开发、测试、验收和上线。
它可能偶尔给你惊喜,但这不该叫生产流程。
Harness 做的事情,就是把流程重新搭起来。
把“写”和“评”拆开
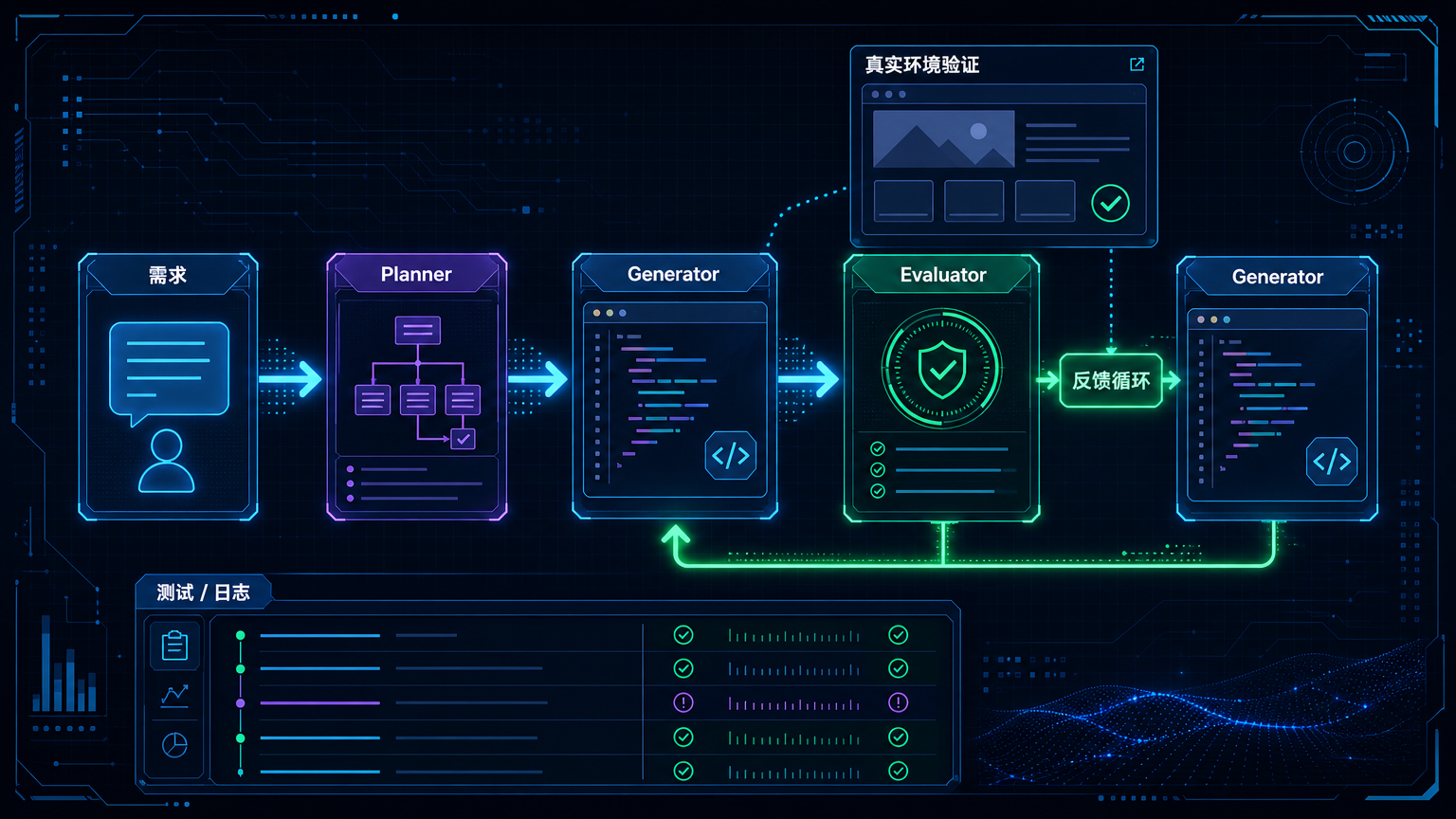
Anthropic 在长时间应用开发实验里用过一个三角色架构:Planner、Generator、Evaluator。
Planner 把用户几句话的需求扩展成规格;Generator 负责实现;Evaluator 打开应用、点击页面、检查状态、找问题,再把反馈交回去。
重点不是“用了三个 Agent”。多 Agent 本身没什么神秘的,做得不好只会更贵、更乱。重点是写代码和验收结果被拆开了。
单 Agent 模式里,一个模型既负责写,又负责判断自己写得好不好。这个安排天然有问题。人类写作者自己校对都会漏错,更何况模型还有一种很强的“任务完成倾向”:它很擅长解释为什么自己已经完成,而不是证明自己其实没完成。
独立 Evaluator 的价值就在这里。
它不继续写代码,只负责挑错。它可以被设定得更严格,可以用 Playwright 打开页面,可以检查 UI、路由、API、数据库状态,也可以按照一套标准打分。
这样一来,流程从“AI 自己说自己完成了”,变成“AI 必须通过另一个评审者的验收”。
这个变化比表面看起来大。
过去我们优化 AI 编程,第一反应往往是换更强模型、写更长 prompt、塞更多上下文。Harness 的思路刚好相反:先承认模型会漂移、会自信犯错、会提前宣布完成,然后用工程流程把这些失败模式包住。
它不是让模型变聪明一点,而是让模型没那么容易糊弄流程。
真实环境比“看起来没问题”重要
很多 AI 编程失败,不是代码语法错了,而是它只在“想象中的环境”里成立。
按钮看起来在页面上,但点了没反应。API 路由写好了,但鉴权状态不对。数据库字段改了,但迁移没跑。Kubernetes 配置显示成功,但生产环境里的网络策略、权限、存储、监控指标早就漂移了。
The New Stack 那篇关于云原生 Agent Harness 的文章,讲的就是这个问题。分布式系统里的反馈信号非常分散。Terraform 绿色不等于云上系统健康,Prometheus 没报警也不等于服务真的可用,CI 通过更不代表真实环境没有漂移。
人类工程师调试生产系统时,会同时看日志、监控、命令输出、用户反馈、历史经验和团队上下文。Agent 如果只看代码 diff 和测试输出,就很容易在局部正确的世界里做出全局错误的判断。
所以 Harness 不能只等于“跑测试”。
它要把真实反馈接进来:浏览器点击、命令执行、日志读取、状态检查、权限限制、成本记录、人工审批。越接近生产的任务,Harness 越不像 prompt 模板,越像一个小型控制平面。
这也是为什么 Anthropic 的示例里会强调 Playwright。浏览器验证不是为了炫技,而是代表一种朴素的工程态度:不要听 Agent 说页面能用,打开它,点它,看它是不是真的能用。
不是再写一句“请认真测试”
过去几年,我们很习惯用 prompt 解决 AI 问题。
模型不认真,就写“你是资深工程师”。模型会偷懒,就写“不要偷懒”。模型容易漏测,就写“请仔细测试”。模型容易幻觉,就写“如果不知道请说不知道”。
这些提示不是完全没用,但它们有明显上限。
任务短的时候,prompt 可以起到约束作用。任务一长,问题就会转移到系统层:模型什么时候该停?它如何知道自己偏题了?谁来判断完成标准?上下文太长时哪些信息应该保留?工具权限如何收紧?失败经验如何沉淀到下一次?
这些问题不是一句“请认真一点”能解决的。
举个最简单的例子。
如果你不希望 Agent 在没跑测试的情况下声称完成,最弱的方法是在 prompt 里写“请务必运行测试”。稍强一点,是给它一个完成检查清单。再强一点,是在 workflow 里要求测试命令必须成功。更进一步,是用 hook 或 CI 把测试失败直接变成无法通过的状态。
前面是提醒,后面是制度。
AI Agent 真要进生产,可靠性最终还是要靠制度,而不是靠提醒。
先别急着堆多 Agent
看到 Planner / Generator / Evaluator 这种架构,很容易得出一个粗糙结论:多 Agent 更强。
我觉得这反而容易把人带偏。
Anthropic 的实验里有个细节很重要:随着模型能力增强,他们会删掉一些不再必要的 Harness 结构。也就是说,Harness 不是越复杂越好。每个组件都应该证明自己还有价值。
对普通开发者来说,这一点更实际。
不要一上来就设计五个 Agent、十个角色、二十个工具。很多时候,你需要先看清楚它到底在哪里失败。
经常误解需求,就加需求澄清。经常写完不测,就加测试门禁。经常说完成但页面不能用,就加浏览器验证。经常被上下文污染,就把任务拆小,写 handoff 文件,必要时重置上下文。经常执行危险命令,就收权限,加人工确认。
Harness 的本质不是画出漂亮架构图,而是把真实失败固化成流程。
O’Reilly 那篇文章里有个原则很实用:每一次错误都应该变成一条规则。当然,这不是说把所有偶发问题都塞进文档,而是把反复出现、代价明确的失败,沉淀成可执行的约束。
Prompt 技巧追求的是一次性效果。Harness 工程追求的是可重复、可调试、可继承。
这两者不是一个层级的问题。
“AI 生码率”会误导管理者
BestBlogs 今日精选里还有一条 InfoQ 中文的线索:阿里云 CIO 复盘 AI 提效时,拒绝把“AI 生码率”纳入考核。
这个判断和 Harness 话题可以放在一起看。
如果只看 AI 生成了多少代码,很容易鼓励错误行为。Agent 可以生成很多行代码,但这些代码可能增加维护负担,可能没有测试,可能绕开原有架构,也可能只是把简单问题复杂化。
软件工程的目标不是更多代码,而是更稳定地交付价值。
Harness 关心的也不是 Agent 写了多少,而是它有没有按正确流程完成任务:需求是否清楚,变更是否最小,测试是否通过,风险是否可控,失败是否可追踪,结果是否能被验收。
当 AI 编程从个人尝鲜进入团队生产,管理者不能只问“用了多少 AI”“生成了多少代码”。更该问的是:AI 参与的变更有没有更高缺陷率?哪些任务适合 Agent?哪些权限不该开放?哪些失败模式反复出现?哪些规则已经自动化?
这些问题都不是模型排行榜能回答的。
答案大多在 Harness 里。
下一代 AI 工程师,不只是写 Prompt 的人
如果说 2023 年大家争着学 Prompt Engineering,2025 年开始谈 Context Engineering,那么接下来 AI 工程里会越来越多出现一种新工作:给 Agent 设计 Harness。
这个角色不一定真的叫 Harness Engineer,但工作内容会越来越清楚。
他不只是写 prompt,也不只是接模型 API。他要知道怎么给 Agent 设计工具,怎么控制权限,怎么构造上下文,怎么记录 trace,怎么写评估标准,怎么接入测试和浏览器,怎么把失败反馈变成下一轮改进。
他关心的不是“让 AI 回答得更漂亮”,而是“让 AI 在真实流程里更可靠”。
这也是开发者可以从 Anthropic 这次实验里带走的东西。
不要把 Harness 理解成大公司的复杂玩具。你自己的项目里也可以有很小的 Harness:一份清晰的 CLAUDE.md,一个必须运行的测试命令,一个禁止删除数据的权限规则,一个 PR 前检查清单,一个用浏览器验证关键路径的步骤。
这些东西单独看都不酷,但它们决定了 Agent 是偶尔惊艳的助手,还是可以反复使用的工程成员。
模型会继续变强。某些脚手架会被删掉,某些流程会变简单。但只要 Agent 开始替人连续行动,我们就绕不开那个问题:
你准备用什么系统来相信它?
Harness 的意义就在这里。
它不是再给 AI 多写几句提示词,而是给 AI 装上刹车、仪表盘、验收员和事故复盘机制。
参考来源
- Harness design for long-running application development
- anthropics/cwc-long-running-agents
- Agent Harness Engineering
- Why agent harnesses fail inside cloud-native systems
- Anthropic’s Claude Code adds a built-in evaluator to catch agents that quit too soon
- InfoQ: Anthropic Designs Three-Agent Harness Supports Long-Running Full-Stack AI Development