
过去一年,AI 编程工具的讨论总绕着几个问题转:Claude Code 和 Cursor 谁更好用?Codex 会不会反超?OpenCode 这种开源替代有没有机会?
这些问题当然重要,但也容易把注意力带偏。
真正发生变化的,可能不是哪个聊天框更聪明,也不是哪个 IDE 的补全更快,而是 AI Agent 的能力正在被重新打包。
以前我们谈 AI 工作流,常说 prompt、rules、MCP、subagent、上下文工程。现在,一个更具体、更工程化的东西开始冒出来:Agent Skills。
如果说 prompt 是一次性指令,rules 是长期偏好,MCP 是外部工具接口,那么 skill 更像是把一个真实工作流压缩成“可调用、可迁移、可验证”的能力模块。
它不是一句提示词,也不是一份说明书。它更像 AI Agent 经济里的最小封装单元。
为什么现在该重视 Skills?
最近 GitHub Trending 上,Addy Osmani 的 agent-skills 项目冲到 29K+ stars。它的定位很直接:Production-grade engineering skills for AI coding agents。
这不是“100 个神奇 prompt 合集”。它做的是把高级工程师在真实软件开发中的流程、质量门槛和最佳实践,封装成 AI Agent 可以稳定遵循的技能。
项目 README 里给出了一条典型的软件开发生命周期:
|
|
每个阶段都不是简单告诉 AI “认真一点”,而是规定它应该做什么:
/spec:先澄清需求,不要直接写代码/plan:把任务拆成小而可验证的单元/build:一次只实现一个垂直切片/test:用测试证明结果,而不是说“应该可以”/review:合并前做质量检查/ship:发布前确认回滚、监控和风险边界
这正好击中了 AI Agent 现在最大的短板。
很多 Agent 并不是不会写代码,而是太容易走最短路径。它会跳过需求澄清,跳过测试,跳过边界检查,跳过安全 review,然后给你一个看起来完整、实际上很脆的结果。
模型越强,这个问题越隐蔽。
弱模型犯错,你一眼能看出来;强模型犯错,经常是带着完整结构、漂亮解释和自信语气一起错。
所以 Agent Skills 的价值,不是让 AI “知道更多知识”,而是让 AI 按正确流程做事。
这两件事差别很大。
Skill 不是更长的 Prompt
很多人第一次看到 skill,会把它理解成“更长一点的 prompt”。
但这可能低估了它。
Prompt 更像你临时对一个人说:“帮我写篇文章,语气自然一点。”
Skill 更像你把一套成熟编辑流程写下来:什么情况下触发,第一步先判断什么,哪些内容不能跳过,常见偷懒借口是什么,输出前必须提供什么证据,失败时如何降级。
这就不是“指令”了,而是“操作规程”。
agent-skills 项目里对 skill 的结构定义很清楚:frontmatter、overview、when to use、process、rationalizations、red flags、verification。里面有两个设计尤其值得注意。
第一,Process, not prose。Skill 不是给 Agent 读的参考文档,而是要让 Agent 执行的工作流。
第二,Verification is non-negotiable。每个 skill 最后都要有证据要求,比如测试通过、构建输出、运行时数据。不能只说“看起来没问题”。
人类工程师的价值,很多时候并不体现在“知道一个 API 怎么用”,而在于知道什么时候该停下来、什么时候该验证、什么时候不能相信自己的直觉。
Agent Skills 试图把这种判断力写进流程里。
这也是为什么它比普通 prompt 更像资产。
Prompt 往往是一次性的。今天这个任务能用,明天换个上下文可能就失效。Skill 则可以持续迭代、版本管理、迁移到不同项目,甚至在团队内部共享。
AI 工具之争,会打到“工作流资产”这一层
过去比较 AI 编程工具,我们常看几个指标:模型能力、上下文窗口、补全速度、IDE 集成、价格。
这些指标仍然重要,但它们越来越像基础设施。
真正决定用户是否长期留下来的,可能是另一个问题:我的工作流资产能不能沉淀在这里?
这就是 Agent Skills 的战略意义。
如果一个团队已经把自己的需求澄清流程、代码 review 标准、测试策略、安全检查清单、发布流程都写成 skills,那么这些 skills 就变成了团队的 AI 原生资产。
模型可以换,IDE 可以换,Agent harness 可以换,但这些流程资产不应该每次重来。
agent-skills 项目不仅支持 Claude Code,还明确提到 Cursor、Gemini CLI、Windsurf、OpenCode、GitHub Copilot、Kiro、Codex 和其他 agents。它的底层假设是:skills 本质上是 plain Markdown,只要某个 agent 接受 system prompts 或 instruction files,就可以复用这些能力。
这件事的含义很大。
AI Agent 的竞争可能会分成三层:
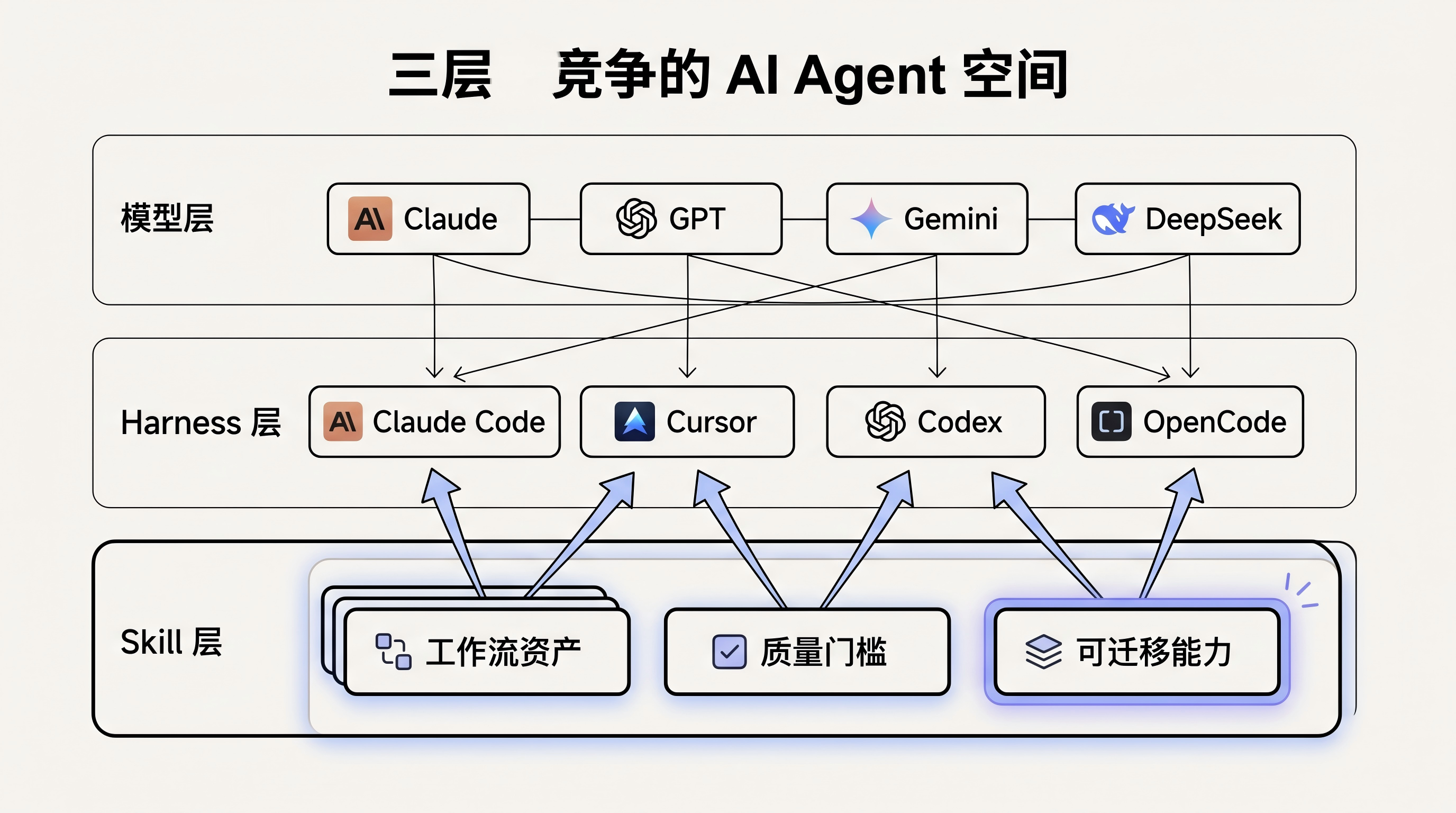
- 模型层:Claude、GPT、Gemini、DeepSeek、Qwen
- Harness 层:Claude Code、Cursor、Codex、OpenCode、Windsurf
- Skill 层:用户和团队沉淀下来的工作流能力
前两层你很难完全拥有。模型是厂商的,harness 也是厂商或开源社区的。
但第三层可能属于你。
你的代码规范、写作风格、选题流程、发布检查、客服话术、数据分析方法,都可以被封装成 skills。
换句话说,未来真正有价值的不是“我会用某个 AI 工具”,而是“我有一套可以迁移到任何 AI 工具里的能力资产”。
好的 Skill 应该像靠谱同事,不是一本手册
很多人做 skill,容易犯一个错误:把它写成知识库。
比如:
写代码要遵循 SOLID、KISS、DRY、YAGNI。要注意安全,要写测试,要保持可维护性。
这当然都对,但对 Agent 的帮助有限。
因为这些原则太抽象。AI 很擅长复述原则,也很擅长在违反原则之后解释自己为什么没有违反。
真正有用的 skill,需要把原则变成动作。
不是说“要写测试”,而是写清楚:什么时候必须先写测试,哪些场景可以不写,如果不写测试要给出什么替代验证,测试失败时不能继续推进,不允许用“只是小改动”作为跳过理由。
这就是 agent-skills 里 anti-rationalization 表的价值。
它不是假设 Agent 会严格自律,而是假设 Agent 会找理由偷懒,然后提前把这些理由堵住。
这很真实。
我们自己使用 AI Agent 时也经常能看到类似话术:
- “这是一个简单改动,不需要测试”
- “我已经看过代码,应该没问题”
- “为了节省时间,先跳过验证”
- “这个错误可能是环境问题”
这些话如果来自初级工程师,你会要求他停下来补证据;但如果来自一个语言流畅的 AI,我们反而容易被说服。
所以一个好的 skill,不应该只是知识说明,而应该像一个靠谱同事在旁边盯流程。
它会提醒你:先别急着写。需求没说清。这个改动范围太大。测试证据不够。安全边界没确认。发布前没有回滚方案。
这样的 skill 才有生产价值。
为什么说 Skill 是“最小封装单元”?
“经济”这个词听起来有点大,但如果把 Agent 当成未来的软件执行单元,那么 skill 很可能会扮演类似“插件”“包”“模板”“SOP”的混合角色。
它足够小,小到可以封装一个具体任务。
它又足够完整,完整到不只是描述结果,还包含流程、边界、验证和失败处理。
这让 skill 具备几种潜在价值。
第一,它可以复用。一个好的 code review skill,不应该只服务一个项目。稍作调整,它可以用于多个代码库、多个团队、多个 Agent。
第二,它可以组合。一个完整任务往往不是一个 skill 完成,而是多个 skill 串联。比如写一篇文章,可以是“热点采集 → 选题审核 → 素材入库 → 大纲生成 → 初稿写作 → 去 AI 味 → 发布检查”。每一步都是独立 skill,但组合起来就是一个工作流。
第三,它可以审计。相比临时聊天,skill 有文本、有版本、有规则。团队可以 review 它、修改它、追踪它为什么导致某类输出。这对企业使用 AI 很重要。
第四,它可以迁移。如果 skill 是 Markdown 或类似开放格式,它就不完全绑定某个平台。今天在 Claude Code,明天在 Gemini CLI,后天在 OpenCode,只要 agent 支持读取这些流程,它就有迁移空间。
模型负责推理,工具负责执行,skill 负责把人类经验封装成可重复调用的工作方式。
但 Skill 不是写得越多越好
Skill 不是银弹。写得不好,它也会制造新问题。
第一个风险是过度流程化。有些任务本来很简单,却被 skill 拆成十几步,导致 Agent 每次都像在走官僚流程。
第二个风险是规则冲突。一个 skill 说“保持简洁”,另一个 skill 说“充分解释”,第三个 skill 说“必须列出完整步骤”。如果没有优先级,Agent 会在冲突指令里摇摆。
第三个风险是维护成本。Skill 一旦多起来,就会像代码一样腐烂。旧规则不更新,路径失效,工具命令过时,项目结构变化后还在按旧流程做事。
第四个风险是权限扩大。当 skill 开始调用工具、操作文件、连接外部服务,它就不只是提示词,而是带执行后果的自动化流程。哪些动作需要确认,哪些动作可以自动执行,必须写清楚。
所以好的 skill 应该遵循几个原则:小而具体,有明确触发条件,有验证标准,有失败路径,能被版本管理和持续迭代,尽量用开放格式。
这和写软件其实很像。
一个函数如果职责太多、边界不清、没有测试、没人维护,最后一定会变成负担。Skill 也是一样。
先别急着装 100 个 Skills
看到 agent-skills 这种项目,很多人的第一反应可能是:我是不是应该把所有 skills 都装上?
可以装,但更重要的是另一件事:开始写自己的 skills。
不是为了炫技,而是为了把你反复做的工作沉淀下来。
最适合做成 skill 的任务,通常有几个特征:你每周都会重复做,你有明确偏好但每次都要重新告诉 AI,AI 经常在同一个地方犯错,任务有固定检查清单,输出质量可以被验证。
比如你经常写公众号文章,就可以先做一个“文章去 AI 味 skill”。
比如你经常做选题,就可以做一个“热点去重与角度判断 skill”。
比如你经常改代码,就可以做一个“发布前检查 skill”。
初版不用完美。写清楚什么时候用、分几步做、哪些事情不能跳过、最后输出什么,就够了。
然后每次使用中发现问题,再把规则补进去。
这才是 skill 真正有意思的地方。它不是一次性写完的 prompt,而是会随着你的工作经验一起成长的东西。
未来每个人都可能有两套资产
过去几年,很多人开始搭建自己的知识库。Obsidian、Notion、Logseq、NotebookLM,本质上都是在解决一个问题:我的信息如何被保存、组织、检索和复用。
但 AI Agent 普及之后,仅有知识库可能不够了。
因为知识回答的是“我知道什么”,skill 回答的是“我怎么做事”。
一个人的长期竞争力,可能会由两套资产组成:
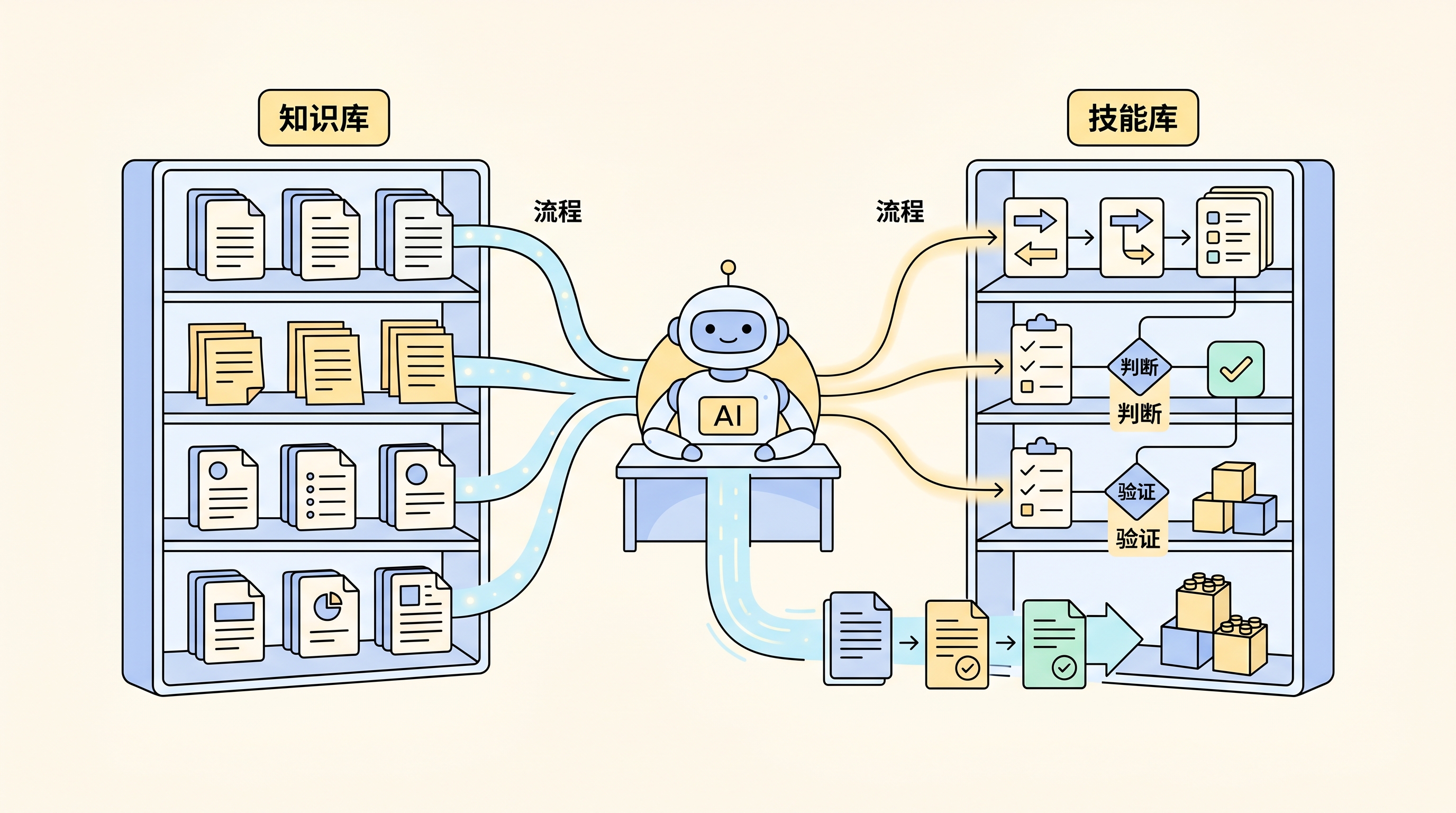
- 知识库:事实、资料、笔记、案例、经验
- 技能库:流程、判断、标准、检查、输出方式
前者让 AI 更懂你的背景。
后者让 AI 更像你的工作方式。
如果说知识库是外部大脑,那么技能库更像外部小脑。它不负责存储所有信息,而负责把动作变得稳定、协调、可重复。
大家现在还在问“哪个模型最好”。但再过一段时间,真正的问题可能会变成:
你的 Agent 学会了你哪些 Skills?
结语
AI 工具更新很快。今天 Claude Code 强,明天 Codex 反超,后天 OpenCode 又冒出来。模型价格会变,接口会变,厂商策略也会变。
但有一类东西不应该跟着每次工具迁移一起丢掉。
那就是你自己的工作流。
Agent Skills 的真正价值,不在于它让 AI 多会了一个技巧,而在于它把“怎么把事情做好”这件事,从一次性的对话里抽离出来,变成可以保存、复用、修改、迁移的资产。
AI Agent 经济如果真的会出现,它不可能只建立在模型 API 上。它还需要一层更贴近真实工作的封装:把专家经验变成流程,把流程变成技能,把技能变成可以组合的能力单元。
到那时,最重要的问题可能不再是:你用哪个 Agent?
而是:你的 Agent 学会了你哪些 Skills?