
企业开始认真使用 AI 写代码之后,最容易冒出来的第一个指标,往往是“AI 生码率”。
它太好理解了。
一段代码里,有多少是 AI 生成的?一个迭代里,有多少提交来自 Copilot、Cursor、Claude Code 或内部 Agent?如果比例越来越高,是不是就说明团队越来越高效?
这个指标听起来直观,也很适合写进汇报材料。因为它给了管理者一个看起来非常清楚的答案:AI 参与度正在上升,投资似乎正在见效。
但问题也在这里。
越是容易被汇报的指标,越不一定能解释真实变化。BestBlogs 今日精选里有一条 InfoQ 中文的复盘,标题大意是“CIO 正在抛弃 AI 生码率”。它传递出的信号不是企业不再相信 AI 编程,而是一些真正开始落地 AI 工程实践的团队,正在意识到:代码生成比例可能是最诱人、也最容易误导人的提效指标。
因为软件工程真正昂贵的部分,从来不只是“把代码打出来”。
如果一个团队让 AI 生成了更多代码,但需求理解没有变快,评审压力没有下降,缺陷没有减少,发布周期没有缩短,线上事故没有变少,那这个团队到底是更高效了,还是只是更快地制造了更多需要维护的东西?
这才是企业 AI 提效真正要回答的问题。
AI 写了多少代码,是最容易被滥用的指标
“AI 生码率”的问题,不是它完全没有价值。
它当然能说明一些事情。比如团队是否真的在使用 AI 工具,AI 是否已经进入日常开发流程,哪些业务线更愿意尝试新工具,哪些团队仍然停留在手工编码。
作为一个采用率指标,它有意义。
但如果把它当成提效指标,麻烦就来了。
因为“代码行数”本身就不是软件价值的稳定代理。一个优秀工程师可能删掉几百行代码,让系统更简单;一个糟糕改动也可能新增几千行代码,让未来所有人都付出维护成本。AI 加进来之后,这个问题只会被放大。
AI 最擅长的,恰恰是快速生成看起来像样的代码。
它可以把一个简单需求扩成完整模块,可以把一个小工具写出很多边界处理,可以快速生成测试、注释、适配层、配置文件。对管理报表来说,这些都很漂亮:代码变多了,AI 参与度提高了,产出似乎增加了。
但软件工程里,更多代码经常意味着更多接口、更多状态、更多依赖、更多评审点,也意味着未来更多理解成本。
如果团队被“AI 写了多少”牵着走,就很容易把 AI 用成一台代码增殖机器。
最后你得到的不是更快交付,而是一座更快长出来的代码森林。

编码只是软件工程的一小段
很多关于 AI 编程的讨论,都天然把焦点放在“写代码”上。
这很正常。因为代码最可见,也最容易展示。一个模型现场生成一个功能,比它帮你澄清需求、拆掉一个错误假设、提前发现设计风险,要更有戏剧性。
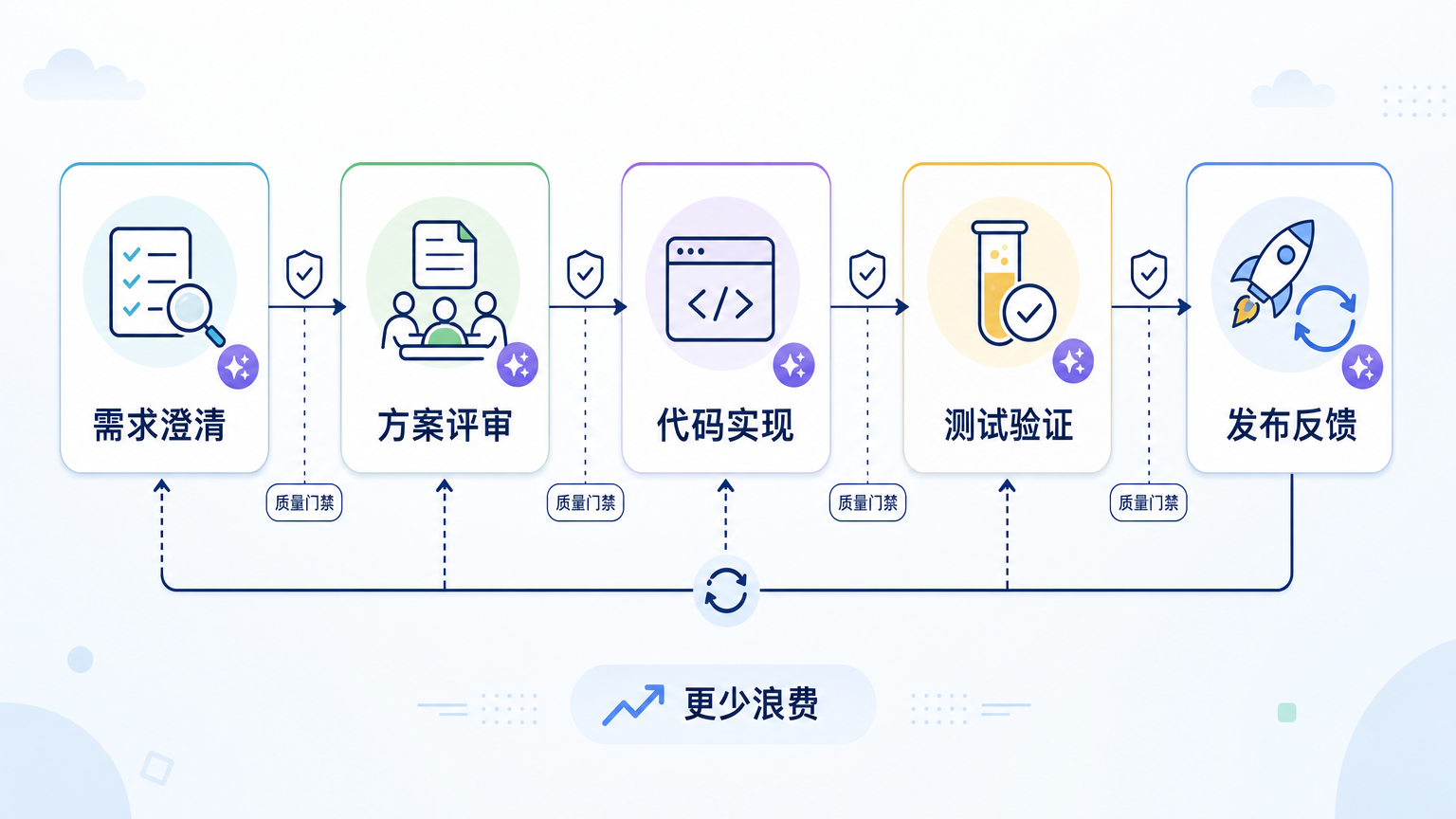
但企业里的软件交付不是从敲下第一行代码开始,也不是在生成最后一行代码时结束。
一个功能真正进入生产,通常要经过需求澄清、方案设计、接口协商、代码实现、测试验证、评审、安全检查、发布、监控、反馈修复。编码只是其中一环。
更现实一点说,在很多成熟团队里,真正拖慢交付的往往不是“没人会写这段代码”。
拖慢交付的是需求反复变,边界没人说清;是上下游接口没人对齐;是历史系统没人敢动;是测试环境不稳定;是评审排队;是发布窗口卡住;是线上问题回滚以后没人知道根因。
AI 如果只是在编码环节加速,当然有帮助,但它触碰到的只是链路中最显眼的一段。
所以企业衡量 AI 提效,不能只问“AI 替我们写了多少代码”,而要问:
AI 有没有让需求更快被澄清?有没有让方案评审更早发现风险?有没有让测试覆盖更贴近真实业务?有没有减少返工?有没有让新人更快理解系统?有没有让一次变更从提出到上线的总时间缩短?
这些问题比生码率难算,但更接近真实价值。
坏指标会把团队带向坏行为
指标从来不是中性的。
你量什么,团队就会优化什么。你奖励什么,团队就会生产什么。
如果一个组织把 AI 生码率当成核心指标,短期内可能会看到很好看的曲线。AI 生成代码比例上升,开发者使用工具更频繁,项目里出现更多由 AI 辅助完成的提交。
但这样的指标也会诱导三个副作用。
第一个副作用是代码膨胀。
当“生成更多”本身被视为进展,开发者会更少质疑“这段代码是否真的需要存在”。AI 给出的实现通常偏向补全和扩展,而不是删除和收敛。它很少主动说:这个需求不该做,这个抽象可以砍掉,这个模块应该合并。
第二个副作用是评审压力后移。
AI 写得越快,人类审得越慢。表面看编码阶段提速了,实际只是把成本从“写代码”转移到“理解 AI 写了什么”。如果评审体系没有变化,AI 生成越多,资深工程师越容易被淹没在看似合理但需要逐行确认的 diff 里。
第三个副作用是指标游戏化。
一旦生码率进入考核,团队就会学会迎合它。能让 AI 生成的就让 AI 生成,哪怕人类手写更简单;能留下的代码就不删除,哪怕删掉才是更好的工程决策。最后指标越来越好,系统越来越重。
这不是 AI 独有的问题。所有单一产出指标都有类似风险。只是 AI 把“制造产出”的速度提高了,所以坏指标的副作用也来得更快。
企业真正该量的是交付链路
如果不用 AI 生码率,那应该量什么?
更合理的方向,是把 AI 放回完整的软件交付链路里看。
第一类是周期指标。
比如从需求确认到上线用了多久,从 bug 创建到修复合并用了多久,从代码提交到通过测试用了多久。AI 的价值如果真实存在,应该能在这些链路时间里留下痕迹。它可能不是让每个环节都变快,但至少应该让某些瓶颈被削平。
第二类是质量指标。
比如千行代码缺陷率、回滚率、线上事故数、重复 bug 数、测试漏检率。AI 如果只是让代码变多,却让缺陷也变多,那不是提效,而是用速度换债务。相反,如果代码生成比例不高,但缺陷下降、返工减少、评审更顺畅,这反而更像真正的工程收益。
第三类是认知负担指标。
这类指标最难量化,却越来越重要。AI 是否让新人更快理解系统?是否让开发者更快定位问题?是否减少跨团队沟通成本?是否让文档、测试、变更说明变得更完整?这些变化不一定立刻体现在代码行数上,却会长期改变团队吞吐量。
第四类是系统性指标。
比如关键模块复杂度有没有下降,重复代码有没有减少,测试覆盖是否更有意义,依赖关系是否更清晰,告警是否更可解释。AI 如果只是局部提速,却让系统整体更难维护,长期看一定会反噬。
这些指标没有生码率那么漂亮,也不容易在一页 PPT 里讲清楚。
但企业真正需要的,恰恰不是漂亮指标,而是能指导决策的指标。
AI 提效不该只算“人省了多少时间”
很多公司评估 AI 工具时,还会落入另一个常见陷阱:把 AI 提效简单换算成人力节省。
比如一个开发者每天省 30 分钟,一个团队 100 人,每年节省多少工时,再乘以人力成本,得出一个 ROI。
这种算法不是完全没用,但它过于粗糙。
AI 在软件团队里的价值,不只是让某个人少敲几行代码。它更可能改变的是工作分布。
以前资深工程师要花很多时间回答重复问题,现在 AI 可以承担一部分上下文解释。以前排查 bug 要先翻日志、查文档、找历史 PR,现在 AI 可以把线索初步串起来。以前测试用例经常被省略,现在 AI 可以先生成一版,再由人类筛选和修正。
这些价值很难直接换算成“省了几分钟”,但它们会改变团队的节奏。
一个更健康的问题是:AI 是否让高价值的人类注意力,从低价值重复劳动里释放出来?
如果 AI 只是让团队更快写样板代码,却没有减少等待、返工和沟通噪音,那它节省的时间很可能会在后续环节重新花掉。
从生码率转向验收率
企业想要更稳妥地衡量 AI 提效,可以先做一个小转向:少看生成率,多看验收率。
不是问“这段代码是不是 AI 写的”,而是问“这次 AI 参与的工作,最后有没有被顺利验收”。
验收可以很朴素:需求是否一次说清,方案是否通过评审,测试是否覆盖关键路径,代码是否少返工,发布后是否少回滚。它不需要一开始就变成复杂平台,也不需要马上引入一套庞大的 AI 管理系统。
对一个普通团队来说,第一步可以只是把 AI 使用记录和交付结果放在一起看。
同样是用了 AI,哪些任务更顺?哪些任务反而返工更多?AI 适合写测试,还是适合读日志?适合生成初稿,还是适合做评审清单?不同团队的答案可能不一样。
这比单纯追生码率更有价值。
因为它能帮助团队形成自己的使用边界。
有些任务适合交给 AI 扩展,有些任务适合让 AI 做检查,有些任务只适合让 AI 辅助理解,不能让它直接改。真正成熟的 AI 工程实践,不是每个环节都让 AI 参与,而是知道哪些环节值得让 AI 参与。
最终目标不是更多代码,而是更少浪费
企业采用 AI 编程工具,当然是为了提效。
但“提效”这个词很容易被误读成“更快生产更多东西”。在软件工程里,这个理解很危险。因为软件不是一次性产物,而是长期系统。今天多写出来的每一行代码,明天都可能变成别人要理解、测试、迁移和修复的负担。
所以 AI 提效的终点,不应该是更多代码。
它应该是更少不必要的工作。
更少反复解释同一个需求。更少因为上下文缺失导致的返工。更少没人敢动的历史逻辑。更少写完才发现方向错了的功能。更少为了证明自己在用 AI 而制造出来的代码。
如果一个团队用了 AI 之后,代码生成比例提高了,但系统更难维护,那它只是把问题加速了。
如果一个团队用了 AI 之后,代码未必显著变多,但交付更稳、返工更少、评审更轻、知识流动更快,那才是真正的提效。
企业 AI 的下一阶段,关键不在于证明 AI 会写代码。
这件事已经不需要证明了。
真正要证明的是:AI 参与之后,软件工程这条链路有没有变得更健康。
别再只问 AI 写了多少代码了。
该问的是:它有没有让我们少做那些本来就不该浪费时间的事。