
Anthropic 最近有一个内部案例:Claude 现在已经处理了 Anthropic 内部 95% 的分析查询(analytics queries)。相关摘要里还提到,Anthropic 把这个结果主要归因于数据治理、语义定义和运营纪律,而不是单纯归因于模型能力升级。
这个说法需要先画一条边界:我没有看到 Anthropic 发布的完整白皮书或可复现实验数据,公开可见的信息主要来自网络和 X 上的二次转述。有人在 X 上补充说,Claude 在有组织上下文时分析准确率可以到 95% 左右,而在缺少上下文时只有 21% 左右。这个数字我会当成“案例线索”来讨论,不把它当成独立验证过的行业基准。
但即便只把它当成线索,它也很有意思。因为它把企业 AI 落地里一个经常被忽略的问题摆到了台面上:公司真正缺的,可能不是更聪明的模型,而是能让模型正确工作的上下文。
过去一年,很多公司谈 AI 提效,最爱问两个问题:AI 写了多少代码?省了多少工时?这些问题不是没有意义,但它们很容易把企业 AI 带偏。写代码只是知识工作的一个切面,工时也只是结果的粗糙代理。真正贵的部分,往往藏在更日常、更无聊的地方:有人想知道上周某个产品线的留存为什么掉了,有人要查某个区域的销售转化,有人要解释广告投放为什么变贵,有人要给老板写一份“能不能继续投”的判断。
这些工作不是简单问答。它们需要知道公司内部有哪些表,每个字段是什么意思,哪些指标口径已经被财务和业务确认,哪些数据还没清洗,哪些人有权限看,哪些答案必须留下审计记录。模型再强,如果只被扔进一个没有说明书的数据仓库,也很容易一本正经地胡说。
企业最先被 AI 接管的,可能不是创意工作
很多人想象企业 AI 的画面,是一个员工对着聊天框说“帮我写一个营销方案”,然后模型吐出一篇像样的文案。这个场景当然存在,但它不是最值得下注的地方。
企业里更高频、更刚需的需求,是“帮我查清楚一件事”。
这件事可能很小:昨天哪个渠道的注册用户质量最好?这个月退款率上升是不是某个地区造成的?新版本上线后,老用户使用频率有没有变化?销售团队说某个行业线索质量下降,到底是线索少了,还是转化慢了?
过去做这些事,通常要经历一条很长的链路。业务同事先问数据同事,数据同事确认口径,去数据仓库写 SQL,跑出结果,再解释图表。如果中间发现问题,还要来回改查询。最后得到的可能是一张截图、一段 Slack 回复,或者一份临时做出来的表格。
这条链路慢,不是因为大家懒,也不是因为 SQL 特别难,而是因为每一步都需要上下文。数据在哪里,字段叫什么,口径怎么定,异常值要不要排除,权限能不能给,结果是否可信,这些都不是模型从互联网上学一学就知道的。
如果 Claude 真能处理 Anthropic 内部 95% 的分析查询,那它改变的就不是“写报告的效率”,而是把这条分析链路压短了。业务人员不一定要先排队等数据同学,不一定要把问题翻译成 SQL,也不一定要在一堆 dashboard(仪表盘)里找入口。他可以直接问一个被接入组织上下文的 Agent(智能体)。
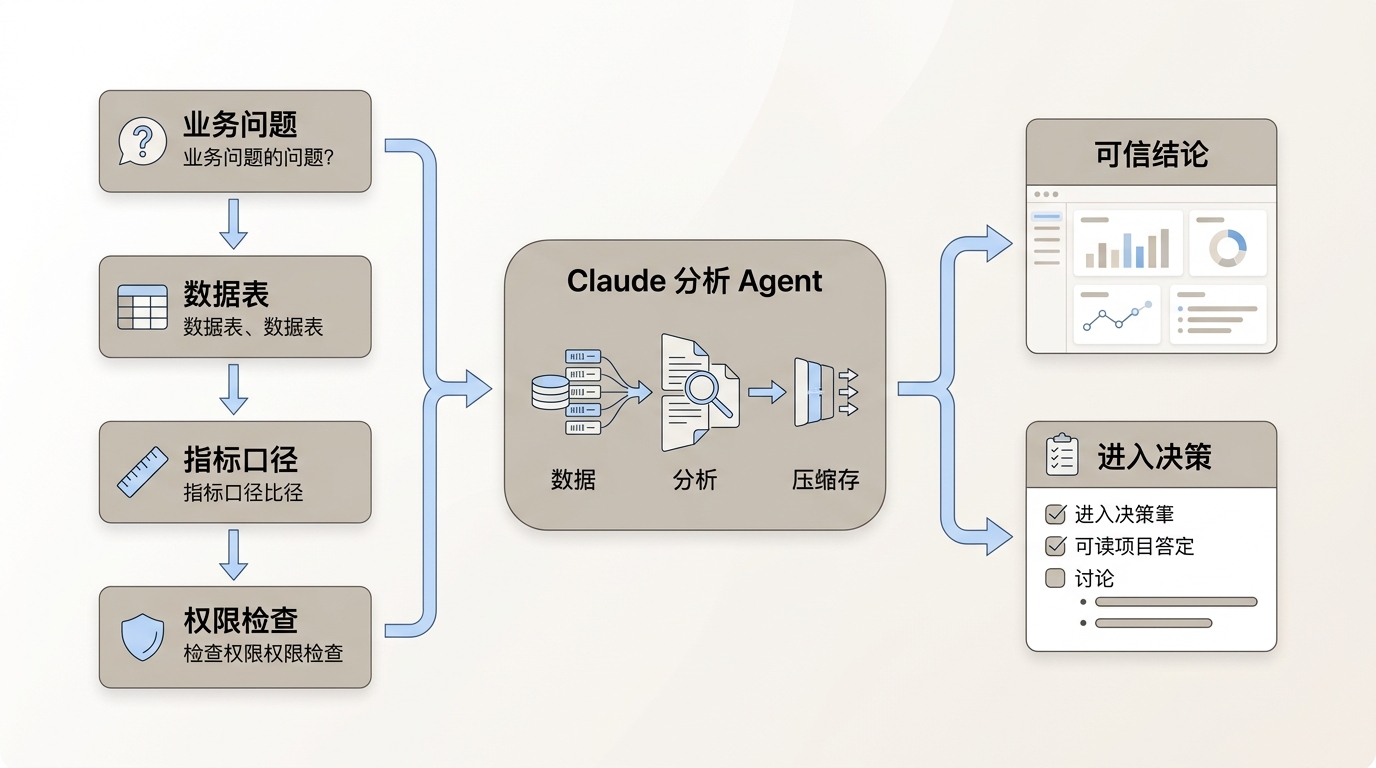 图:从业务问题、数据表、指标口径到权限检查,内部分析 Agent 的价值不是替人写一段报告,而是把原本要反复沟通的查数链路压短。
图:从业务问题、数据表、指标口径到权限检查,内部分析 Agent 的价值不是替人写一段报告,而是把原本要反复沟通的查数链路压短。
这才是企业 AI 比较现实的落点:不是先替掉某个岗位,而是先吞掉公司内部大量“查数、解释、归因、汇报”的中间环节。
21% 到 95%,差的不是提示词
如果那个“无上下文 21%、有上下文 95%”的说法大体成立,它最有价值的地方不是 95% 这个数字,而是两个数字之间的落差。
很多公司看到 AI 答得不好,第一反应是换模型,或者让员工学 Prompt Engineering(提示词工程)。于是内部培训变成“如何写好提示词”,文档里堆满了角色设定、输出格式、few-shot 示例。这样做有用,但只解决了很小一块问题。
企业分析不是高考作文。它不是你把问题写清楚,模型就能凭常识答对。它需要三个层面的上下文。
第一层是数据上下文。模型要知道能查哪些数据,表之间怎么关联,哪些字段已经废弃,哪些字段只是临时口径。比如“活跃用户”到底按登录算、按核心行为算,还是按付费行为算,不同公司、不同团队可能完全不同。
第二层是业务上下文。同一个指标变化,在不同业务阶段的含义不一样。新增下降,在成熟产品里可能是危险信号;在主动收缩低质量渠道时,反而可能是健康信号。模型如果不知道公司当前策略,就会把每个波动都解释成通用模板。
第三层是组织上下文。谁能看什么数据,什么结论可以直接对外说,什么结论只能内部讨论,哪些数字需要财务确认,哪些分析必须保留来源。这些东西看起来像流程问题,其实决定了 AI 能不能进入真实工作。
所以,企业 AI 的关键不只是 Prompt Engineering,而是 Context Engineering(上下文工程)。提示词解决“我怎么问”,上下文工程解决“模型凭什么知道我在问什么”。前者更像个人技巧,后者才是公司能力。
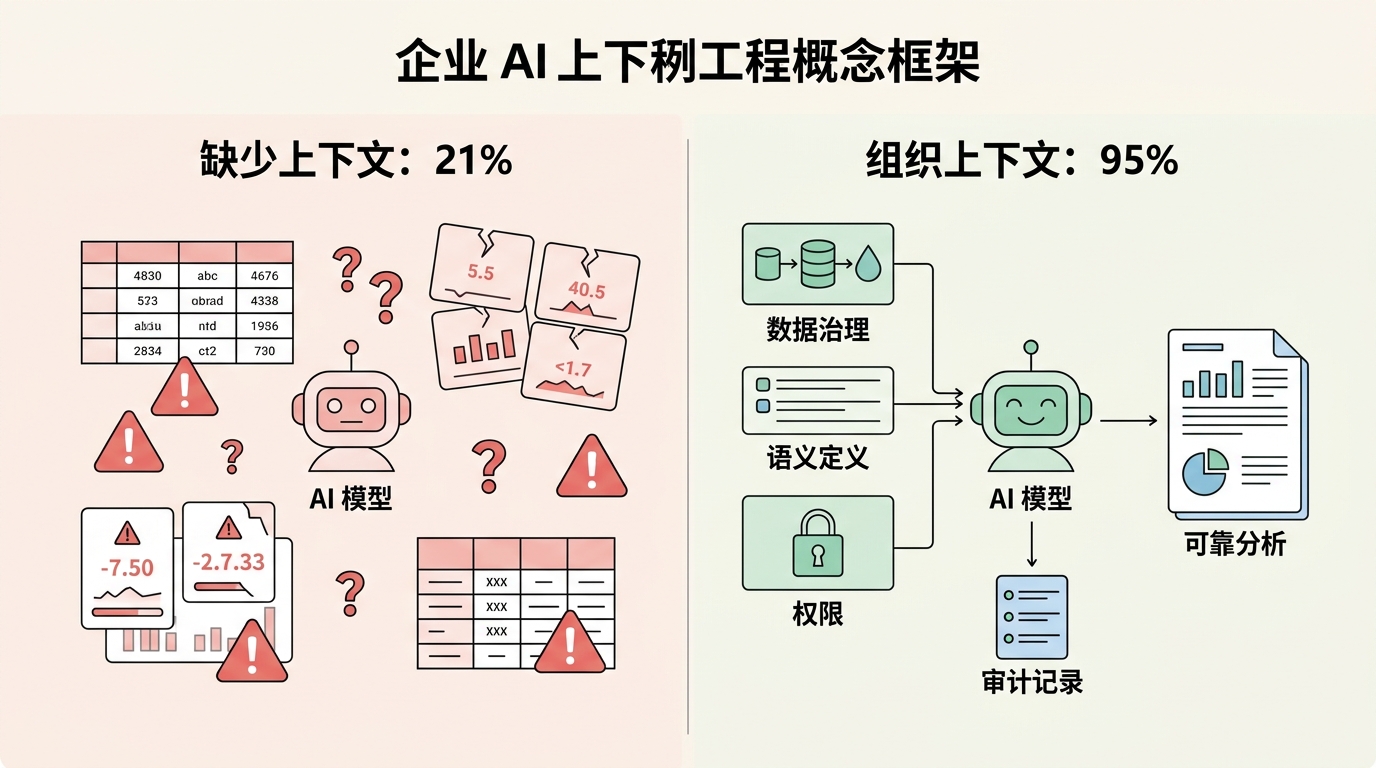 图:同一个模型,放在混乱数据里只能猜;接入数据治理、语义定义、权限和审计记录后,才可能输出能进入决策的分析。
图:同一个模型,放在混乱数据里只能猜;接入数据治理、语义定义、权限和审计记录后,才可能输出能进入决策的分析。
数据治理听起来无聊,但它决定 AI 能不能上桌
“数据治理”这四个字很容易让人犯困。很多公司一提数据治理,就想到建数仓、定指标、做权限、写文档,都是看起来不性感、很难发朋友圈的工作。
但 Anthropic 这个案例的启发恰恰在这里:越是想让 AI 进入核心业务,越绕不开这些无聊工作。
原因很简单。聊天机器人可以犯一点小错,内部分析 Agent 不行。它一旦回答“这个渠道 ROI 最高”“这个客户群值得继续投”“这个产品功能导致留存下降”,后面可能接的是预算、绩效、资源分配,甚至组织调整。这个时候,老板不会满足于一句“根据我的分析”。他会问数据从哪里来,口径是什么,能不能复算,为什么不是另一个结论。
如果公司没有统一指标口径,AI 会把不同团队的定义混在一起。如果权限体系混乱,AI 可能把不该展示的数据展示出来。如果没有审计记录,出了错也不知道是模型推理错了、SQL 写错了,还是数据源本来就脏。
这也是为什么“让 AI 读数据库”听起来简单,真正上线却很难。一个 demo 可以连上 Postgres 跑查询,十分钟就能做出效果;但一个能在公司里长期用的分析 Agent,必须知道什么时候该查,查完怎么解释,不确定时怎么提示,遇到敏感字段怎么拒绝,结论怎么附上依据。
换句话说,企业 AI 的门槛正在从“能不能调用模型”,转向“公司有没有把自己的业务世界整理到机器能理解”。
真正的新 KPI:多少决策准备工作被 Agent 吃掉了
如果继续用“AI 写了多少代码”来衡量企业 AI,很容易低估这类内部分析 Agent 的价值。
代码当然重要,尤其对软件公司来说。但很多企业每天消耗最多的,不是写代码时间,而是决策准备时间。一个会开完,大家发现还缺一张数据表;一个项目推进不下去,是因为没人能说清哪个指标是真的;一个季度复盘,三天都花在对齐口径上。
这些时间不会总是被记录成“工时浪费”,但它们真实存在,而且非常贵。
所以,一个更有意义的企业 AI 指标可能是:公司内部有多少查询、分析、归因和汇报准备工作,可以由 Agent 自助完成,并且结果能被人信任到足以进入会议。
注意,这里有两个条件:自助完成,以及结果可信。只有自助,没有可信,最后会变成更多噪音;只有可信,但每次都要数据团队手动兜底,也很难规模化。企业 AI 的价值,正是在这两个条件同时成立时出现的。
这也是 Anthropic 案例比普通“AI 提效故事”更值得看的原因。它不是在说 Claude 会写漂亮报告,而是在说一个组织把数据、语义、权限和流程整理到一定程度后,AI 可以承担大部分日常分析入口。
国内公司应该先抄哪一部分
如果国内公司要从这个案例里学东西,我不建议一上来就学“95%”。这个数字太漂亮,容易变成新的 PPT 指标。
更实际的做法,是先挑一个高频、低风险、口径相对清楚的内部分析场景。比如销售漏斗、客服工单、内容转化、广告投放、产品留存。不要一开始就让 AI 回答“公司战略怎么调整”,而是让它回答一类重复出现、数据来源明确、人工本来就会查的问题。
然后把这个场景拆成几件事:哪些表可信,指标口径怎么定义,谁能访问,回答必须带哪些引用,哪些问题应该拒答,哪些结论需要提示“仅供参考”。这些工作做完,再接模型,效果通常会比单纯换更贵的模型更稳定。
企业内部也要重新定义数据团队的角色。过去数据团队像“报表和 SQL 服务台”,别人提需求,它来查数。未来更像“AI 分析系统的运营者”:维护指标语义,清理数据源,定义权限边界,检查 Agent 的回答质量,处理失败案例。
这个变化可能比看上去更大。因为一旦业务同事可以直接问 Agent,数据团队的价值就不再是“我会写查询”,而是“我保证这套查询世界是可信的”。
模型负责推理,组织负责让推理有地方落脚
这件事最后可以落到一个很朴素的判断:企业 AI 不是把一个聪明模型接进公司就结束了。
模型负责推理,负责把自然语言问题转成查询、解释和判断。但组织要负责给它一个能落脚的世界。这个世界包括干净的数据、稳定的指标、明确的权限、可追踪的过程,以及人类愿意为结果承担责任的工作方式。
如果没有这个世界,模型越强,反而越危险。它会用更流畅的语言包装不可靠的答案,让人更难发现哪里错了。很多企业 AI 项目的失败,不是因为模型不够聪明,而是因为公司把一个擅长推理的系统,放进了一个口径混乱、权限模糊、数据没人负责的环境里。
Anthropic 这个案例提醒我们,企业 AI 的下一阶段不会只比谁买到了更好的模型。真正的差距会出现在组织内部:谁先把自己的数据、指标和流程整理成 AI 能稳定使用的上下文,谁就能先把 Agent 放进真实决策链。
所以,95% 这个数字可以先不急着崇拜。更值得问的是:如果明天把一个同样强的 Claude 接进你的公司,它能不能知道“收入”到底指什么,“活跃”到底怎么算,“异常”到底由谁确认,以及哪些答案不能随便说?
如果这些问题还答不上来,企业 AI 的瓶颈就不在模型。它在公司自己身上。
参考来源
- BestBlogs: Anthropic Reports Claude Now Handles 95% of Internal Analytics Queries
- BestBlogs Daily Brief 2026-06-22
- X: Anthropic internal agentic analytics summary
以上来源用于观察公开摘要和社区转述,不等同于独立基准测试。文中涉及的 95% 和 21% 主要作为案例线索使用,正式引用时仍应以 Anthropic 后续公开原文或完整报告为准。