
一个 23 岁的漏洞,和它背后的新战场
OpenAI 在 6 月 22 日发了一篇很长的官方博客,叫《Patch the Planet》。里面提到一件具体的事:自家的模型在 OpenBSD 内核里挖出一个存在了 23 年的 use-after-free(释放后使用)漏洞,位置在 System V 信号量的实现里。按 OpenAI 研究人员的复现,一个没有特权的本地用户可以借这个漏洞把权限提到 root。
这种事放在五年前,属于顶尖安全实验室花几周才能干成的工作。现在它被写在 AI 公司的月度战报里,和 Linux 内核 30 多万行代码里挖出 24 个本地提权 PoC(概念验证)、让 Pwn2Own 柏林站 6 个 Firefox 参赛队里 5 个退赛这些事,列在同一段落。
本文的素材主要来自 OpenAI 官方博客《Patch the Planet》、Trail of Bits 的同步说明,以及 CyberPress、FourWeekMBA 等媒体的转述。涉及 benchmark 数字和"影响多少网站"这类断言,我都标注了口径,没有把它们直接当作独立事实背书。读者可以把这篇当成对 OpenAI 发布口径和社区反馈的一次梳理,而不是一次独立基准测试。
一日五弹:不只是发一个模型
把 6 月 22 日 OpenAI 在 Daybreak(破晓)项目下放出来的东西摊开,至少有五件:
一是 GPT-5.5-Cyber 的完整版。这是 GPT-5.5 的网络安全特化分支,训练时就在防御性安全任务上放开得更宽。按 OpenAI 公布的 CyberGym 跑分,它拿到 85.6%,高于同源 GPT-5.5 的 81.8%,也高于 Anthropic Mythos 5 的 83.8% 和 Claude Opus 4 的 73.1%。在另外两个偏实战的榜单 ExploitGym 和 SEC-bench Pro 上,它对 GPT-5.5 的领先幅度更明显(39.5% 对 25.95%、69.8% 对 63.1%)。访问被限制在经过验证的防御者(verified defenders)范围内,不向公众开放。
二是 Codex Security 插件的升级。这个插件从 2026 年 3 月的研究预览到现在,按 OpenAI 的说法已经扫描了超过 3000 万次提交、覆盖 3 万多个代码库,人工标记为"已修复"的发现超过 7 万条,自动处理的还有 50 万条以上。新版本能直接在开发者环境里生成带验证证据的严重度排序结果、画攻击路径、建威胁模型、产出针对具体代码库的补丁,还能把结果以 SARIF 和 CodeQL 查询的形式导进既有的漏洞管理流水线。
三是 Patch the Planet。这是和 Trail of Bits 合办、HackerOne 和 Calif 协作的开源软件维护者计划。第一批参与的 30 多个项目里包括 cURL、Go、Python、Sigstore、pyca/cryptography、NATS Server、aiohttp、freenginx、python.org。维护者拿到 ChatGPT Pro、有条件的 Codex Security 访问权,以及用于核心开发、自动化和发布流程的 API 额度。一次 5 天的冲刺里,Trail of Bits 的安全工程师配合模型发现数百个问题,合并了数十个补丁。
四是 Trusted Access for Cyber 的政府合作名单。澳大利亚、加拿大、法国、德国、日本、韩国,以及含 ENISA 在内的欧盟机构都在列。OpenAI 还和 CAISI(Center for AI Standards and Innovation)一起做 GPT-5.5 和 GPT-5.5-Cyber 的部署前测试,和美国国家网络总监办公室(ONCD)、科技政策办公室(OSTP)一起落实 2026 年 6 月的 AI 行政令。
五是被官方反复强调的那条产品线口号:Daybreak 是 OpenAI “为全球每个组织提供安全工具"的总工程名。GPT-5.5-Cyber 是模型底座,Codex Security 是开发者侧抓手,Patch the Planet 是公共品入口,Trusted Access 是政府侧信用背书。这不是五个孤立产品,而是一套完整的打法。
为什么是这个时间点:对标 Anthropic 的 Glasswing
FourWeekMBA 在 6 月 22 日的分析里把话说得很直接:Daybreak 是 OpenAI 对 Anthropic Project Glasswing(玻璃翼)的正面对答。后者是 Anthropic 那边把 Mythos 模型以较原始形态开放给 200 个安全组织的项目,按公开数据已经累计发现 23019 个漏洞。一个值得注意的细节是,Glasswing 在美国政府叫停 Fable 5 之后仍然在运行。
两家头部 AI 实验室在同一个赛道里对垒,本身就是一种判断:在所有 AI 应用场景里,网络安全是前沿能力"最立即有用"又"最政治正确"的那一个。写诗、画画、聊天,都可以被监管来回敲打;但帮 cURL 修漏洞、帮 Linux 内核找提权链,没人会公开反对。FourWeekMBA 把这种逻辑叫 Permission Layer(许可层),意思是 AI 厂商靠防御性安全建立的不只是产品,而是一种政府信任牌照——它让模型在被监管收紧时仍有一个"不能被关掉"的运行理由。
从这个角度看,OpenAI 和 Anthropic 争的不是谁的模型更高 1.8 个百分点,而是谁能先把自己写进关键基础设施的安全供应商名单。Glasswing 比 Daybreak 早、合作机构多(200 对 8),但 OpenAI 这次把 Patch the Planet 摆出来,是在用"修互联网公共底座"这件事抢公共品站位,政府侧 Trusted Access 的七国名单则在补政治信用。
三轴并行的真正意图
把五弹归类,能看清 OpenAI 想做的事其实是三条轴同时推进。
模型轴上,GPT-5.5-Cyber 解决的是"能不能”。85.6% 的 CyberGym 说明在"复现已知漏洞"这件事上它已经超过同代所有对手。把模型限制在 verified defenders 范围内,既是合规姿态,也是制造稀缺——越不让随便用,越显得强。
工具轴上,Codex Security 解决的是"开发者用不用得上"。把漏洞扫描塞进 Codex 这个写代码的 Agent 里,等开发者用同一个工具既写代码又扫代码,OpenAI 就同时占住了 bug 的生产端和检测端。这个布局比单独卖一个安全模型更值钱,因为它卡在日常工作流里,迁移成本极高。
生态轴上,Patch the Planet 解决的是"公共品站位"。互联网的底层软件是共享设施,谁来修这些设施就有政治意义。OpenAI 出模型、Trail of Bits 出安全工程师、维护者出代码,三方合力把开源软件的漏洞存量往下压。这件事短期不赚钱,但它在监管层面换回的东西,是单纯的 benchmark 数字买不到的。
三条轴合起来看,OpenAI 不是在卖一个"AI 安全产品",而是在搭建一套让政府、开发者、维护者都离不开的网络安全基础设施。Snyk 在 6 月 23 日紧接着发布 Evo Agentic Development Security,从防御侧做了类似的押注。赛道已经不只是 OpenAI 对 Anthropic,而是整个产业在把"AI for Security"当作下一阶段的确定增量。
那些被拿出来炫耀的实战结果
OpenAI 在博客里列了一批已经修掉或正在披露的漏洞,挑几个有画面感的:
- Linux 内核 3000 多万行代码里,模型标出安全相关组件,动态验证后产出 8 个内核指针信息泄露 PoC 和 24 个本地提权漏洞;
- OpenBSD 那个 23 年的 use-after-free,可以让无特权本地用户提到 root;
- FreeBSD 一轮专项里确认 34 个漏洞,产出 7 个本地提权 PoC;
- dnsmasq 后续 2.92rel2 版本修掉的 6 个 CVE 里,Codex Security 独立命中了其中 4 个;
- Calif 用 Codex 找到的"HTTP/2 Bomb",是一种影响 NGINX、Apache、IIS、Pingora 等主流实现的拒绝服务手法,按 Calif 的分析,有 88 万以上暴露在公网的网站运行着受影响的服务器软件;
- 浏览器侧,Chrome V8 报了 5 个可利用漏洞,Safari 一周内报了 10 个以上,Firefox 在 Pwn2Own 柏林站前两天被 Mozilla 补掉的那个 WebAssembly 漏洞(CVE-2026-8390),让 6 个注册的 Firefox 参赛队里有 5 个退赛。
这些数字里有一部分(比如 88 万网站、Linux 内核行数、Codex Security 扫描的 commit 数)来自 OpenAI 和合作方的口径,独立复核需要时间。但即便是按发布方自己的说法打折,量级也足以说明:模型在漏洞挖掘和补丁生成这件事上,已经从"能演示"进入"能交付"的阶段。
对国内厂商意味着什么
国内做安全大模型和 Agent 的厂商,过去大多把卖点放在"我们能扫代码"“我们能写安全报告”。OpenAI 这套打法的参照意义在于,它把竞争维度从"单点能力"拉到了"全栈站位"。
第一,模型层必须有特化分支。通用大模型在安全任务上的表现,和专门训练过的 Cyber 分支差距明显(GPT-5.5 对 GPT-5.5-Cyber 在 ExploitGym 上是 25.95% 对 39.5%)。国内厂商如果还指望用同一个通用模型打所有场景,在安全这条线上会被拉开。
第二,工具层必须嵌进开发者工作流。Codex Security 的价值不是它扫得准,而是它长在写代码的那个 Agent 里。国内做 IDE 插件、CI 流水线扫描的厂商,需要思考怎么把自己的能力绑进开发者每天都在用的工具,而不是要求开发者专门打开一个安全平台。
第三,生态层必须敢做公共品。Patch the Planet 修的是 cURL、Python、Go 这些全世界都在用的开源项目。国内厂商如果能组织起类似的开源软件维护计划,带来的政府关系和行业信任回报,会比单纯卖几个安全模型大得多。
第四,政府侧的合规布局要前置。OpenAI 把七国政府和 ENISA 拉进 Trusted Access,把 CAISI、ONCD、OSTP 拉进预部署测试和行政令落实,这些动作让它的安全模型在政策收紧时有缓冲。国内厂商面对的监管环境不同,但"把合规做成护城河"这个思路是通用的。
四个产品,到底各管什么
回到开头那个问题:OpenAI 一天发这么多东西,彼此到底是什么关系?
可以这么拆。Daybreak 是总工程名,它不直接面向用户,而是一把伞。GPT-5.5-Cyber 是伞下的模型底座,决定"能挖多深的漏洞、能写多准的补丁",是能力上限。Codex Security 是面向开发者的工具层,把模型能力翻译成 IDE 里点一下就能用的扫描和修复,是日常入口。Patch the Planet 是面向开源生态的公共品层,用模型加人力帮 cURL、Python 这些底层项目还技术债,是政治信用。Trusted Access for Cyber 是面向政府的合规层,让模型在七国和欧盟的关键基础设施里获得合法身份,是监管缓冲。
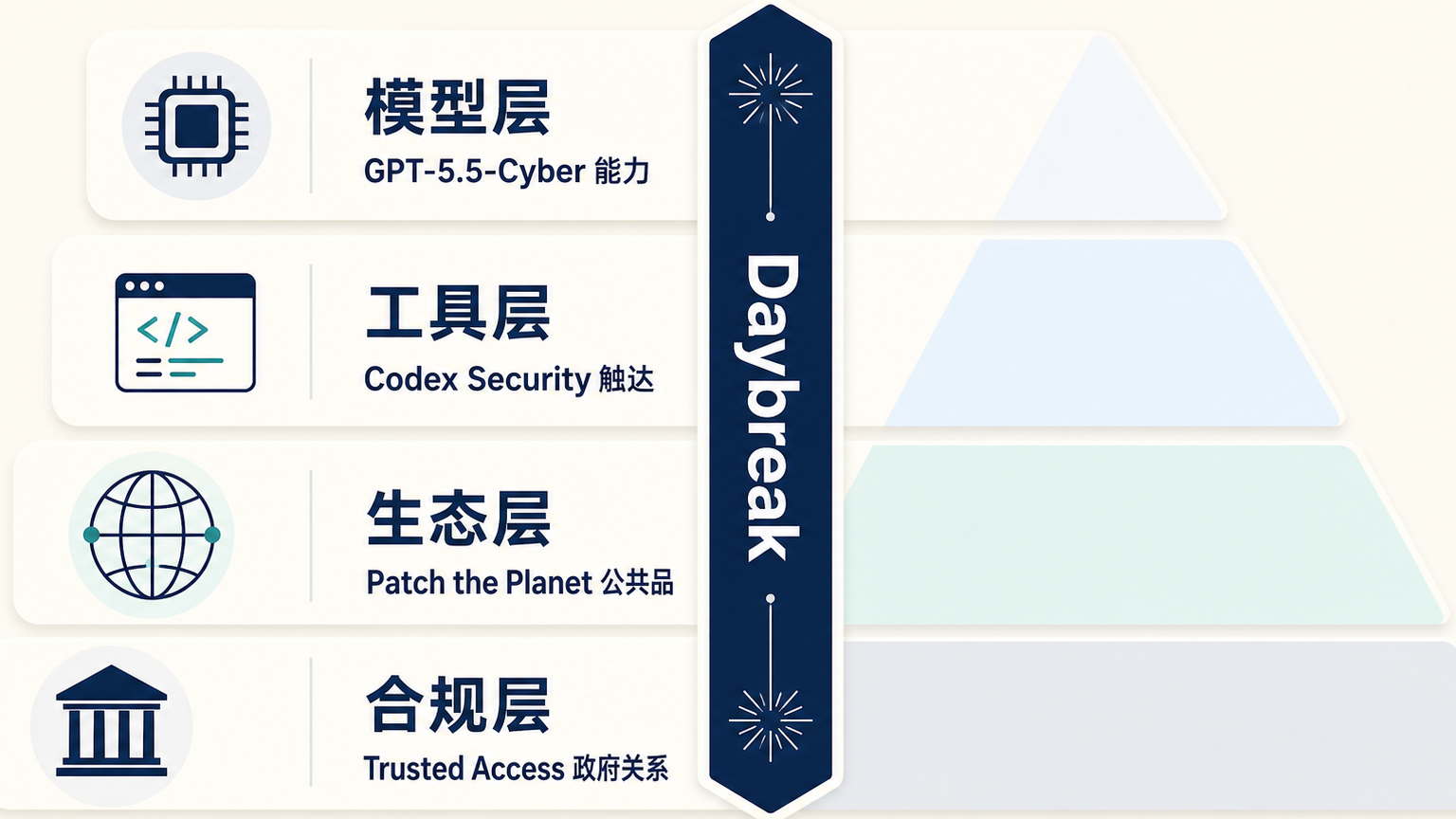
四者的分工边界很清楚:模型管能力,工具管触达,生态管公共品站位,政府关系管合规。任何一环单独拿出来都不够。GPT-5.5-Cyber 再强,如果没有 Codex Security 嵌进开发者工作流,它就只是个实验室跑分;Codex Security 再好用,如果没有 Patch the Planet 修开源软件、没有 Trusted Access 进政府名单,它在监管收紧时就没有"不能被关掉"的豁免理由。
这才是这次"一日五弹"真正值得看的地方。OpenAI 不是在发五个产品,它是在把网络安全这件事拆成能力、触达、生态、合规四层,然后一次性把每一层都占住。Anthropic 的 Glasswing 起步更早、合作机构更多,但 OpenAI 这一手的全栈意味更浓。接下来半年,看 Snyk、AWS、Google 怎么接这招,以及国内安全厂商里谁先意识到这场竞争已经不是"谁的模型扫得准"这么简单,会比看跑分有意思得多。
参考来源
- Patch the Planet: a Daybreak initiative to support open source maintainers(OpenAI 官方)
- Daybreak: Tools for securing every organization in the world(OpenAI 官方)
- OpenAI Launches GPT-5.5-Cyber for Automated Vulnerability Detection and Patching(CyberPress)
- OpenAI Launches GPT-5.5-Cyber and Codex Security — Daybreak vs Anthropic Glasswing(FourWeekMBA)
- OpenAI Daybreak Expands Patch Pipeline as Five Eyes Warns AI Attacks Are Months Away(TechTimes)
- Introducing Patch the Planet(Trail of Bits)
以上来源用于观察 OpenAI 与合作方的发布口径及媒体转述,其中的 benchmark 数字、漏洞数量、受影响网站规模等断言均为发布方提供,不等同于独立基准测试。模型能力的横向对比(CyberGym、ExploitGym、SEC-bench Pro)建议结合各榜单的评测方法论文再作判断。