
如果一个 AI 编程模型每秒能吐出 1200 个 token,我的第一反应其实不是兴奋,而是有点警惕。
等模型输出很烦,这大家都知道。以前让 AI 改一个稍微复杂点的功能,等几分钟很正常。等它打字的时候,人很容易切走,去看消息、喝水、处理别的事。回来的时候,屏幕上已经多了一大段代码,甚至改了好几个文件。
慢模型时代,这种习惯已经不太好;到了快模型时代,它会变得更危险。
Sarah Chieng 在 AI Engineer 的分享里讲到 Cerebras 和 OpenAI 合作推出的 Codex Spark。据她介绍,这个模型可以用每秒 1200 tokens 的速度生成代码。很多常见模型大概是每秒 40 到 60 tokens。换句话说,过去十分钟才堆出来的一大坨 diff,现在可能半分钟就出现。
这时问题就变了。不是“AI 太慢,影响效率”,而是“AI 太快,人还没来得及判断,它已经替你做完了好几个决定”。
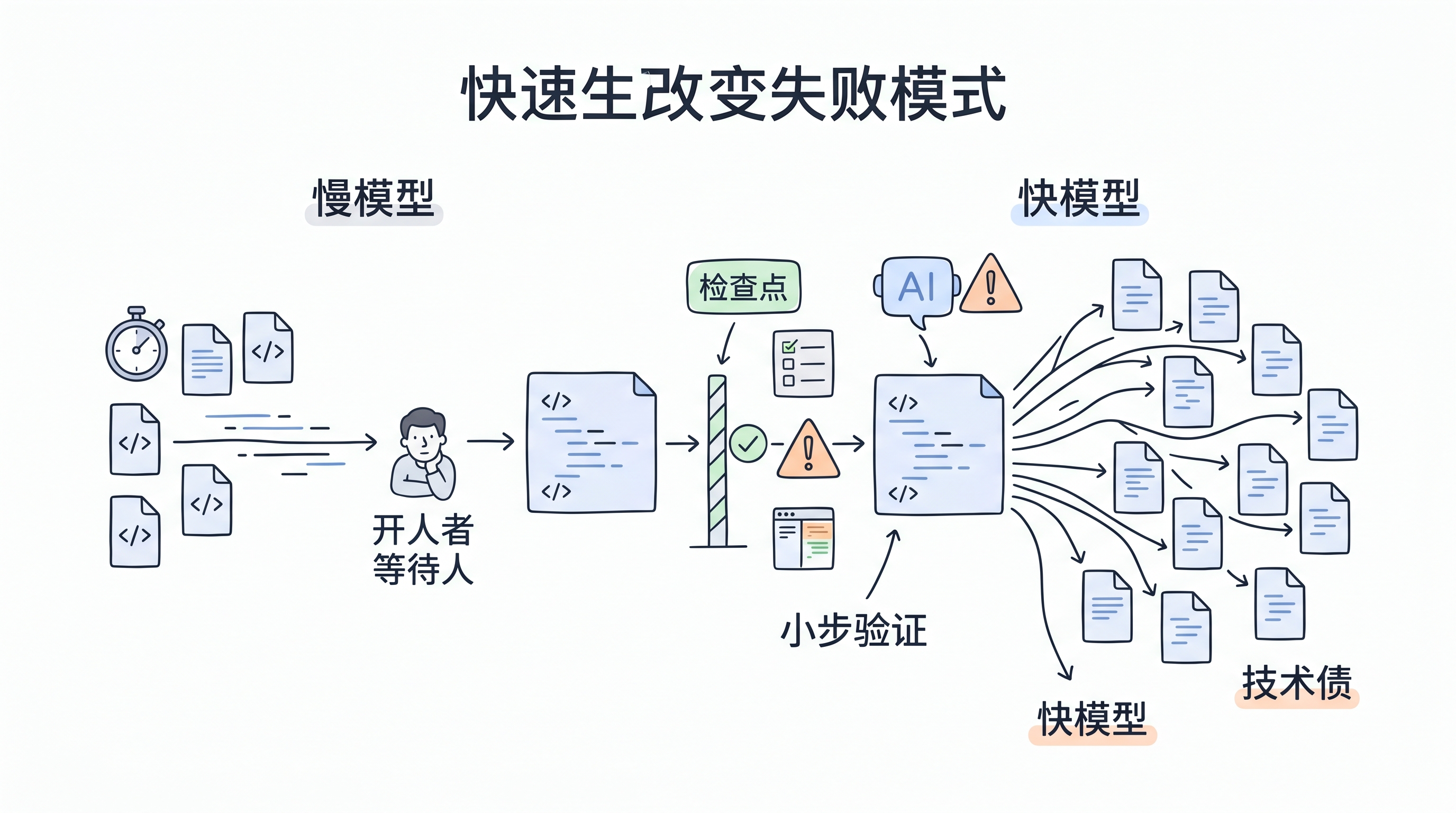
速度会改变出错的样子
以前我们习惯写一个很大的 prompt。背景、需求、约束、文件结构、注意事项,能塞进去的都塞进去,然后希望模型一次性给个完整结果。
这套办法为什么流行?因为等待很贵。既然等一轮输出要几分钟,那当然希望一轮多做点。
可一旦模型很快,这个逻辑就不太成立了。快模型适合短跑,不适合在没人看的情况下自己开车上高速。一个 agent 如果理解错了需求,它可以很快改完多个文件,顺手删掉旧逻辑,补几条看起来合理的测试,再把接口整理得像模像样。你打开 diff 时,甚至会觉得它挺认真。
麻烦就在这里。坏代码不一定长得很粗糙。AI 生成的坏代码,经常是语气很自信、结构很完整、命名也还不错,只是方向错了。
所以我觉得“快模型需要慢开发者”这句话,重点不是让大家少用 AI,而是提醒我们:不能再把 AI coding 当成“丢给外包,晚点验收”。它更像一台转速很高的机器。机器当然能提高产能,但你得盯着它切到哪里、有没有越界、有没有把不该动的地方也顺手磨掉。
现在真正贵的是判断
生成速度上来之后,便宜的是代码草稿,贵的是判断。
判断它有没有误解需求。判断它有没有破坏原来的接口。判断它是不是为了让测试通过,悄悄改了测试本身。判断它加的抽象是真有必要,还是只是看起来高级。判断它是不是把一个小问题扩成了一个“顺便重构”。
这些判断不会因为模型变快就自动消失。相反,模型越快,它们出现得越密集。
我现在更愿意把快模型当成“候选方案生成器”。比如做一个 UI 组件,与其让它一次写出最终版,不如让它给几种布局;写一个边界条件多的函数,也可以让它给两三种处理方式。然后人来选,选完再让它收敛。
这和演讲里提到的 cherry-pick 思路很接近。快模型的价值不是替你跳过审美和工程判断,而是让你有更多可比较的草稿。人的价值,也不再只是亲手敲每一行代码,而是知道哪一版更稳、更贴近需求、更不容易给未来挖坑。
测试别留到最后
我以前也常犯一个错:让 AI 先写完,最后统一跑测试。
这个习惯在快模型时代要改。原因很简单,代码几秒钟就能生成一轮,测试就不该等到最后才出现。否则你会得到一个很大的 diff,然后才发现第一步就走错了。
更舒服的节奏应该小很多:先划清任务边界,让 AI 只改一个局部;改完马上跑对应测试、lint 或类型检查;结果不对就立刻停下,缩小问题,再来一轮。没有测试的项目,也至少要让它给出可观察的验证方式,比如启动页面、检查输出、对比某个 API 返回。
这听起来慢,但通常会省时间。真正浪费时间的不是多跑几次测试,而是半小时后才发现 AI 从一开始就理解错了。
在高速 AI coding 里,验证不是保守动作,而是节奏的一部分。就像开车不是因为胆小才看后视镜,而是因为车速上来了,不看就太冒险。
规划和执行最好分开
Sarah Chieng 还提到一个分工:高智能模型负责规划,快模型负责执行。
我觉得这点特别适合放到 Claude Code、Codex、Cursor 这类工具里理解。并不是所有任务都应该交给最快的模型。速度适合明确的小任务:改一个组件,补一个测试,实现一个函数,生成几个候选方案。
但架构判断、需求拆解、跨模块迁移、兼容性边界,这些事情不该只追求快。它们需要更强的推理,也需要人先把边界写清楚。
一个比较稳的 AI coding 流程,通常会分成两段。
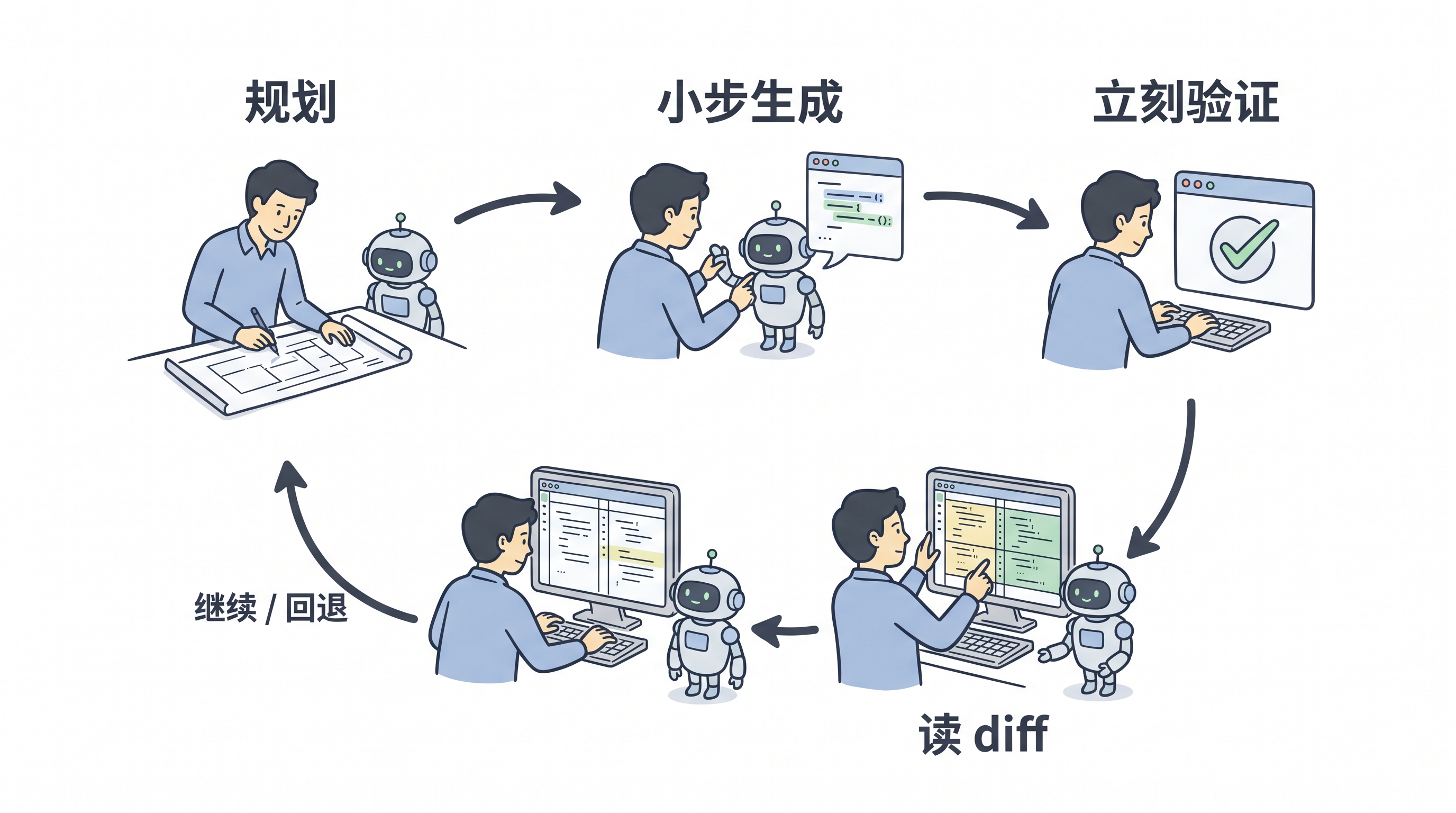
先做规划:这次到底改什么,不改什么,哪些接口不能动,哪些行为要保持,怎么证明改对了。这个阶段不用急,越急越容易漏约束。
再做执行:在明确边界里快速试错,生成代码,补测试,修 lint,跑局部验证。这里才应该吃速度红利。
很多翻车不是因为模型不会写某一行代码,而是你让它同时当产品经理、架构师、程序员、测试和 reviewer。它当然会省事,也当然会在某些地方糊弄过去。速度越快,这种糊弄越不容易被及时发现。
把上下文写进文件里
演讲里还有一个细节我很喜欢:用几个持久的 Markdown 文件管理上下文,比如 agents.md、plan.md、progress.md、verify.md。
这不是为了仪式感。快模型会更快吃掉上下文窗口。原来十分钟才触发的压缩,现在可能几十秒就遇到。上下文一压缩,早期说过的限制就可能被淡化,尤其是那些“不要做什么”。
把关键上下文写进文件里,就等于给 AI 留了一本项目手册。
agents.md 可以写角色和边界,plan.md 写目标和步骤,progress.md 记录已经做完什么、还卡在哪里,verify.md 写每一步怎么验收。不一定非得照搬这四个文件,但原则很简单:重要约束不要只留在聊天记录里。
尤其是这几类信息,最好落到文件:需求边界、禁止改动范围、验证命令、已知风险、已经做过但失败的方案。这样下一轮生成不是凭模型记忆接着猜,而是有明确的状态可以读。
我会怎么用 Claude Code
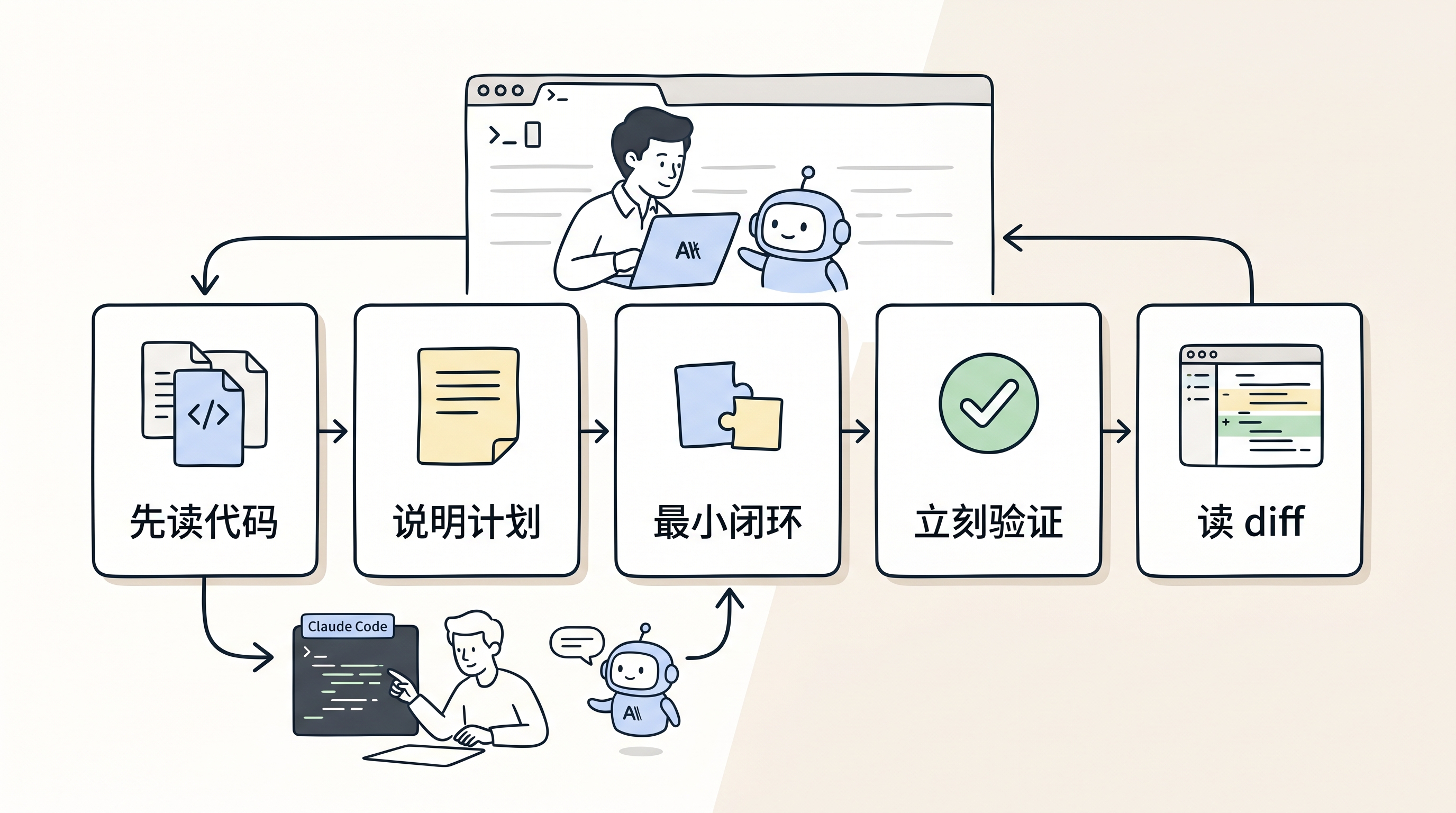
如果把这套想法落到 Claude Code,我会尽量把任务切得更短。
第一步先让它读代码,别急着写。让它说清楚准备改哪些文件、为什么改、怎么验证。这个时候重点看它有没有误解项目结构。
第二步只允许它做最小闭环。能改三行就不要改三十行,能补一个测试就不要顺手重构一片。AI 很喜欢“顺便优化”,但很多麻烦也来自顺手。
第三步,改完立刻验证。能跑测试就跑测试,不能跑测试也要有替代检查。不要接受那种“理论上应该可以”的交付。
最后看 diff 的时候,不只问“做了什么”,还要问“有没有改到不该改的地方”。这个问题比总结功能更有用。
慢下来,不是少用 AI
我不觉得“慢开发者”是在怀念手写代码。恰恰相反,只有真正用得多,才会意识到节奏控制有多重要。
AI 写代码越快,人越需要知道什么时候该停。什么时候让模型继续跑,什么时候要读 diff;什么时候让它生成多个候选,什么时候只允许它改一个文件;什么时候追求速度,什么时候必须先补验证。
以后熟练使用 AI coding 的人,可能不是 prompt 写得最长的人,而是最会设检查点的人。
快模型把可能性铺开,开发者负责把它收束成可以维护、可以验证、可以上线的工程结果。速度本身不是坏事,但没有边界的速度,很容易只是更快的技术债。