Agent 真正危险的地方,不在聊天框里
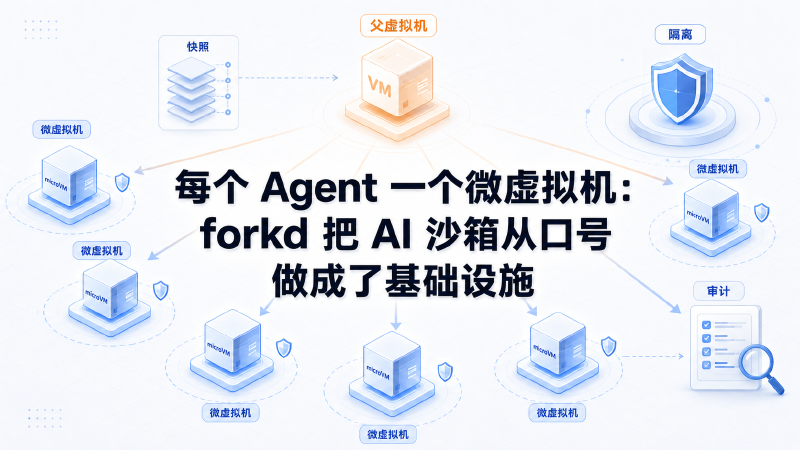
今天看到一个很适合接在 Harness Engineering(支架工程)和 Agent 沙箱主线后面写的开源项目:forkd。它的 GitHub README 把话说得很直接:Fork 100 microVMs in 101 ms。换成人话,就是从一个已经预热好的父虚拟机里,在很短时间内分叉出一批隔离的 microVM(微虚拟机),给 AI Agent 执行代码、跑测试、做工具调用。
这篇文章主要基于 forkd 的 GitHub README、设计文档摘要和今日收录线索整理。里面提到的 101 ms、0.12 MiB、56 ms p50 等数字都来自项目作者自己的 benchmark(基准测试),我没有在本地复测。读者可以把它当成一次技术方向观察,而不是独立性能评测。
为什么这个项目值得看?因为现在大家谈 Agent(智能体)安全,还是太容易停在“提示词护栏”“工具白名单”“审批按钮”这几层。它们当然有用,但只解决了 Agent 要不要做某件事的问题,没有解决 Agent 一旦开始做事之后,应该在哪里做、出错怎么回滚、不同任务之间怎么隔离、执行证据怎么留下。
换句话说,Agent 真正危险的地方不在聊天框里,而在它开始拥有 shell、文件系统、网络、依赖安装、测试运行和数据库连接之后。
这时再说“给它一个沙箱”就太粗了。什么级别的沙箱?容器够不够?每个用户一个长期环境,还是每次工具调用一个短环境?要不要继承前面的状态?要不要把中途推理和文件系统一起 fork 出来?这些问题才是 AI Agent 进入生产环境后会遇到的硬骨头。
forkd 正好切在这里。
forkd 到底做了什么
forkd 的定位是一个面向 AI agent fan-out(智能体扇出)的 microVM sandbox runtime(微虚拟机沙箱运行时)。它底层基于 Firecracker,每个 child(子实例)都是独立的 Firecracker 进程,由 KVM 提供硬件虚拟化隔离。
它的关键不是“能启动虚拟机”,而是启动方式。
传统做法是每个 sandbox(沙箱)冷启动一遍。你要跑 Python,就启动系统、拉起运行时、import numpy、加载依赖、准备缓存。一个 Agent 同时分出 100 条路径做代码解释、评测或测试 rollout(展开执行)时,这个冷启动成本会被放大很多倍。
forkd 的做法更像操作系统里的 fork(2):
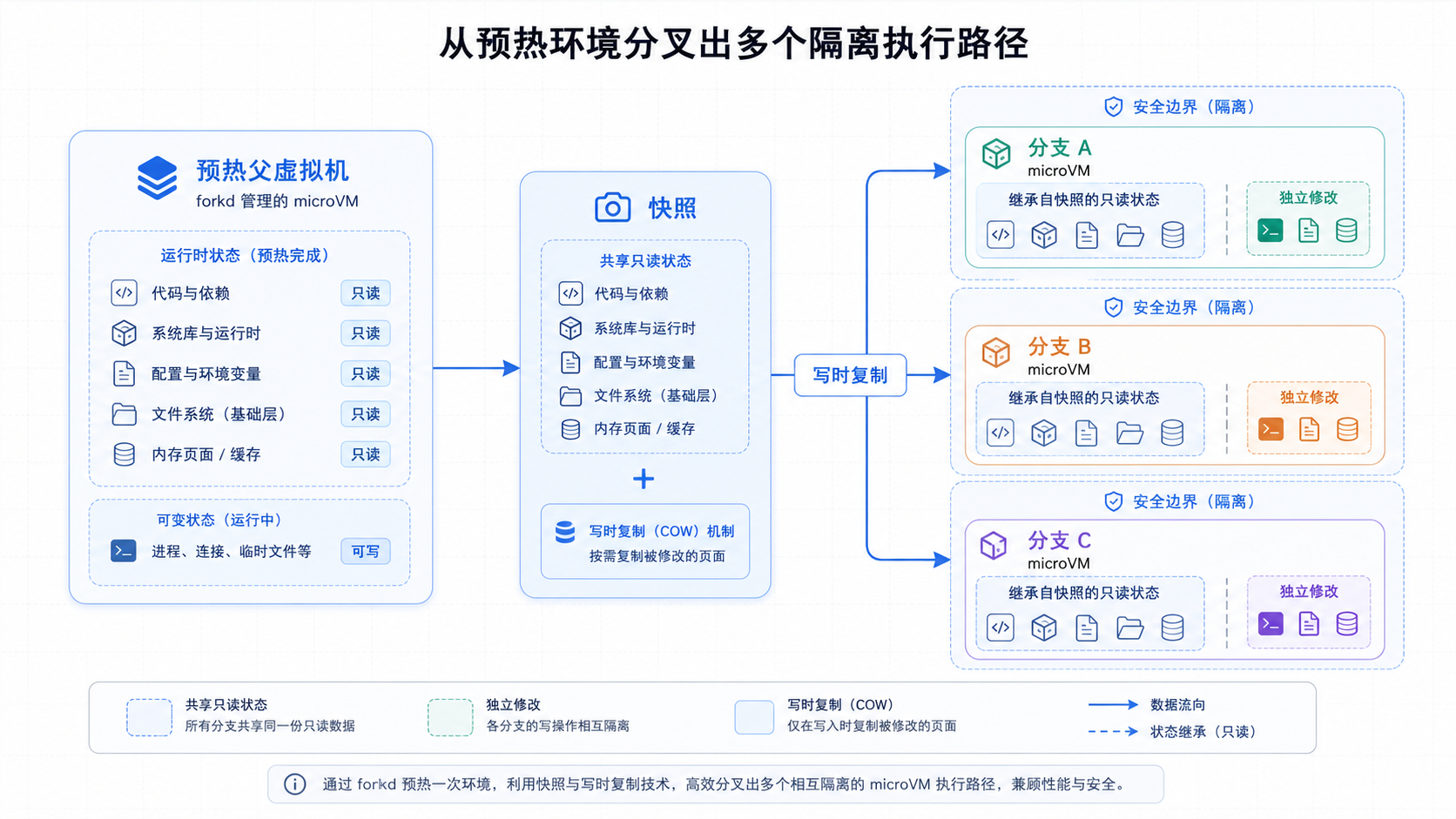
先启动一个 parent VM(父虚拟机),把 Python、依赖、JIT、模型权重或缓存都预热好,然后暂停并保存成 snapshot(快照)。后续的 child VM 从这个父快照恢复。内存不是完整复制一份,而是通过 mmap MAP_PRIVATE 让子进程共享父内存镜像,直到某个页面被写入时才 copy-on-write(写时复制)。
所以它想同时拿到两件东西:
一边是 microVM 的隔离级别。每个 child 都是自己的 Firecracker microVM,不是共用一个容器 namespace(命名空间)。README 里说得很直白:逃逸需要 hypervisor(虚拟机监控器)或 kernel(内核)漏洞,而不是普通的 runc 回归问题。
另一边是接近进程 fork 的启动成本。项目 README 给出的基准是,在 Ubuntu 24.04、Linux 6.14、20 vCPU、30 GiB、KVM 环境下,让 100 个 sandbox 各自执行 import numpy; numpy.zeros(5).tolist(),forkd 的 wall-clock(墙钟时间)是 101 ms,额外内存约 0.12 MiB / child。这个数值是否能在别的机器复现要另说,但它表达的方向很清楚:不要每次都冷启动,把预热成本摊到父实例上。
这和普通容器快照的区别在于,它不只是文件系统层面的复用,还把运行时内存状态也放进了继承链。
如果一个 Agent 要开 20 条路径分别尝试修 bug,最贵的可能不是那几行补丁,而是每条路径都要重新安装依赖、重新导入包、重新准备测试环境。forkd 想把这些准备动作变成一次性成本。
BRANCH:让 Agent 在“想了一半”时分叉
forkd 还有一个更有意思的能力,叫 BRANCH。
普通 snapshot(快照)更像是在任务开始前准备好一个干净环境。BRANCH 解决的是另一个场景:Agent 已经跑了一段,中途积累了推理上下文、文件系统变化、缓存状态、临时产物,这时你想从这个状态分出几个不同方向。
README 里的 LangGraph demo(演示)是一个旅行规划例子:source agent(源智能体)已经跑了 ReAct loop(推理-行动循环),然后在中途被 BRANCH 出三个 grandchildren(孙实例),每个收到不同 steering hint(引导提示)。三个分支继承此前的推理状态,但后续输出走向不同。
这件事听起来像“多问几次模型”也能做到,但 forkd 项目特别强调了另一个例子:coding-agent-fork recipe(编码智能体分叉配方)里,一个 50 MiB 的二进制 blob 会在 4 个 sandbox 之间 byte-identically(逐字节一致)继承。三个 grandchildren 分别对一个有 bug 的 Python 包做不同修复,__pycache__/ 和文件编辑彼此隔离,但前面的 50 MiB 状态是共享继承来的。
这就不是提示词能解决的问题了。提示词可以复制文字上下文,复制不了一个已经跑过安装、缓存、生成中间文件、打开项目目录的执行环境。
项目 README 提到,v0.4 live BRANCH 把 source-pause window(源实例暂停窗口)从约 200 ms 降到 56 ms p50 / 64 ms p90。这个指标同样来自项目自己的测试,但它说明 forkd 的目标不是“给 Agent 开一个长期云主机”,而是让 Agent 能频繁、廉价地在执行过程中分叉。
这对 AI Coding(AI 编程)很关键。因为 Agent 写代码时常常不是一条直线:
它可能先读完代码库,形成一个假设,然后同时尝试三种补丁;也可能先跑测试,发现失败,再分出“保守修复”“重构修复”“绕过修复”三条路径;还可能在安全审计里,让不同分支验证同一个漏洞是否可复现。
如果每条路径都从零启动环境,分叉就很贵。如果能从“已经读完仓库、装好依赖、跑过初始测试”的状态分叉,Agent 的探索成本会下降很多。
为什么这件事和 Harness Engineering 有关
过去几个月,OpenAI、Anthropic、社区文章都在讲 Harness Engineering。这个词容易被理解成“给 Agent 包一层脚手架”,比如工具调用、任务队列、评测、日志、人工审批。这个理解没错,但还不够。
真正的 Harness(支架)不只是在模型外面写几个 if else。它要决定 Agent 在什么环境里运行,能拿到哪些资源,失败后怎么复盘,结果怎么验证,状态怎么保存,什么时候可以继续,什么时候必须停下来。
从这个角度看,forkd 不是 Harness 本身,却像是 Harness 下面的一块运行时地基。
一个成熟的 Agent Harness 至少有几层:
第一层是意图层。用户说要修 bug、写报告、跑评测,系统要把目标拆成任务。
第二层是工具层。Agent 可以读文件、写代码、跑测试、访问网络、调用数据库。
第三层是验证层。每一步做完之后,要用测试、lint、schema、人工 review 或另一个 Agent 来判断是否可信。
第四层就是运行时层。工具调用到底在哪里执行?不同用户、不同任务、不同分支是不是互相隔离?出错能不能回滚?能不能重放?能不能留下审计日志?
很多讨论停在前三层。forkd 讨论的是第四层。
这也是为什么它的 README 里会强调 REST API、bearer token auth、Prometheus /metrics、append-only JSON audit log(追加式 JSON 审计日志)、systemd unit 这些看起来不那么“AI”的东西。对真实平台来说,这些反而是 AI Agent 能不能进生产的关键。
一个 Agent 如果只能在 demo 里跑,最重要的是模型会不会推理。一个 Agent 如果要替用户跑不可信代码,最重要的是它跑在哪里、权限有多大、日志留在哪里、出事后能不能定位。
容器为什么不一定够
很多人看到“沙箱”第一反应是 Docker。
Docker 很成熟,也足够好用。但在 AI Agent 场景里,容器有两个问题会变得更明显。
第一个是隔离边界。容器主要依赖 Linux namespace、cgroup、seccomp、LSM 等机制。它不是没安全性,但如果你要跑的是用户上传代码、模型生成脚本、自动安装依赖、联网请求、甚至未知二进制,风险模型会更接近“执行不可信代码”。这时 microVM 的隔离边界会更让平台团队放心。
第二个是状态继承。容器可以做镜像层、overlay、缓存,也可以用池化减少冷启动。但如果目标是“从一个正在运行中的 Agent 状态分叉出多个独立执行分支”,普通容器并不是天然为这件事设计的。
forkd 不是说容器没用。它更像是在说,AI Agent 的某些 workload shape(工作负载形态)和传统 Web 服务不一样。
传统 Web 服务追求长期稳定运行。Agent 执行更像短生命周期、高并发、强隔离、频繁分叉、频繁销毁。代码解释器、SWE-bench 风格评测、自动修复、CI 里的不可信测试、每个用户一次工具调用,都属于这种形态。
这类场景里,平台更需要“快速复制一个已预热、但彼此隔离的执行宇宙”。
v0.5 的 diff-snapshot chain 说明它在往哪走
forkd v0.5 提到 diff-snapshot chains(差分快照链)。这个功能看起来很工程细节,但其实能看出项目的方向。
假设一个 Agent 平台先准备了 python:3.12-slim,然后装了 numpy,再装 pandas,再装 scikit-learn。如果每一步都存一份完整 1.5 GiB 基础环境,存储和传输都会很浪费。diff-snapshot chain 的思路是,每一层记录 parent_tag 和内容哈希,spawn(生成)时沿着链条组装内存镜像。
这和 Docker 镜像层有点像,但对象变成了 sandbox 的内存和 VM 状态。
README 里的 Phase 5 benchmark 显示,在 512 MiB base 上,depth 0 的 flat base spawn p50 是 59 ms;加 numpy 后 751 ms;再加 pandas 到 1222 ms;再加 sklearn 到 1668 ms。作者也坦诚 per-link tax(每层开销)主要来自 SHA-256 校验,后续优化排到 v0.6。
这段数据反而让项目更可信一点。它没有假装所有场景都是 100 ms。它承认链条越深越有税,承认有场景需要 compact(压平)快照。
对 Agent 平台来说,这也是现实问题:你不可能只有一个万能父环境。不同任务需要不同依赖、不同语言、不同模型、不同浏览器状态。最后一定会出现一组“环境谱系”:基础 Python、数据分析 Python、浏览器自动化、Node 项目、某个代码库 checkout、某个测试 fixture。
能不能管理这些谱系,可能会成为 Agent 平台的基础能力。
它适合什么,不适合什么
forkd 适合的场景很清楚。
它适合 code interpreter(代码解释器)这类每次工具调用都想要干净执行环境、但又不想重复 import 大依赖的场景。
它适合评测系统。比如同时跑几百个 repo checkout 或测试 rollout,每个 child 互不污染,但共享预热父环境。
它适合不可信代码执行。比如 CI 里跑外部 PR、Agent 自动生成补丁后执行测试、用户上传脚本做数据处理。你希望它有真实 Linux、能 apt install、能联网,但又不想让它和宿主机贴得太近。
它也适合自托管团队。README 里反复强调 Apache 2.0、single-binary daemon、REST API、Python SDK、MCP server,这些都是在对平台工程团队说:你可以把它接到自己的 Agent 系统里,而不一定要依赖托管 sandbox SaaS。
但它也有明显不适合的地方。
如果你只需要一个长期 workspace(工作区),每个用户一个持久环境,Daytona、Codespaces 这类形态可能更合适。
如果你只需要极致函数级启动,且不需要真实 Linux、多 vCPU、完整网络、apt install,一些函数级 snapshot runtime 可能更快。
如果你没有 KVM、没有 Linux 宿主、没有运维能力,forkd 这类东西并不会比托管平台省心。
这不是一个“所有 Agent 都该用 forkd”的故事。更准确地说,它把一个问题摆到了桌面上:当 Agent 不再只是写文本,而是开始执行代码、安装依赖、访问网络、产生文件系统状态时,运行时本身会变成产品的一部分。
国内 Agent 平台最该补的是这一层
国内现在讲 Agent,很多时候还在卷模型调用、工作流画布、插件市场、知识库接入。再往前一点的团队,会谈评测、记忆、工具权限、MCP registry(MCP 注册表)。这些都重要,但如果缺少执行运行时,Agent 的能力还是会卡在“只能建议,不能安全地做”。
真正要落到企业场景,平台方迟早要回答几个具体问题:
用户让 Agent 跑一段 Python,在哪里跑?
Agent 自动 pip install 一个依赖,污染谁的环境?
Agent 同时尝试三种修复方案,文件系统怎么隔离?
Agent 访问外网下载包,网络出口怎么管?
Agent 生成了危险命令,拦截发生在提示词层、工具层,还是内核 / 网络层?
Agent 跑完后,日志、指标、文件 diff、网络访问记录和退出状态能不能被审计?
这些问题没有一个能靠“模型更聪明”自动消失。模型越能干,反而越需要这些基础设施把它关在合适的地方。
forkd 的启发在于,它把“Agent 沙箱”从产品口号还原成了一堆工程对象:Firecracker、KVM、snapshot、copy-on-write、network namespace、cgroup、REST、metrics、audit log。
这些词不性感,但它们决定 Agent 能不能被放心地放进生产系统。
Agent 负责执行,Harness 负责刹车和现场
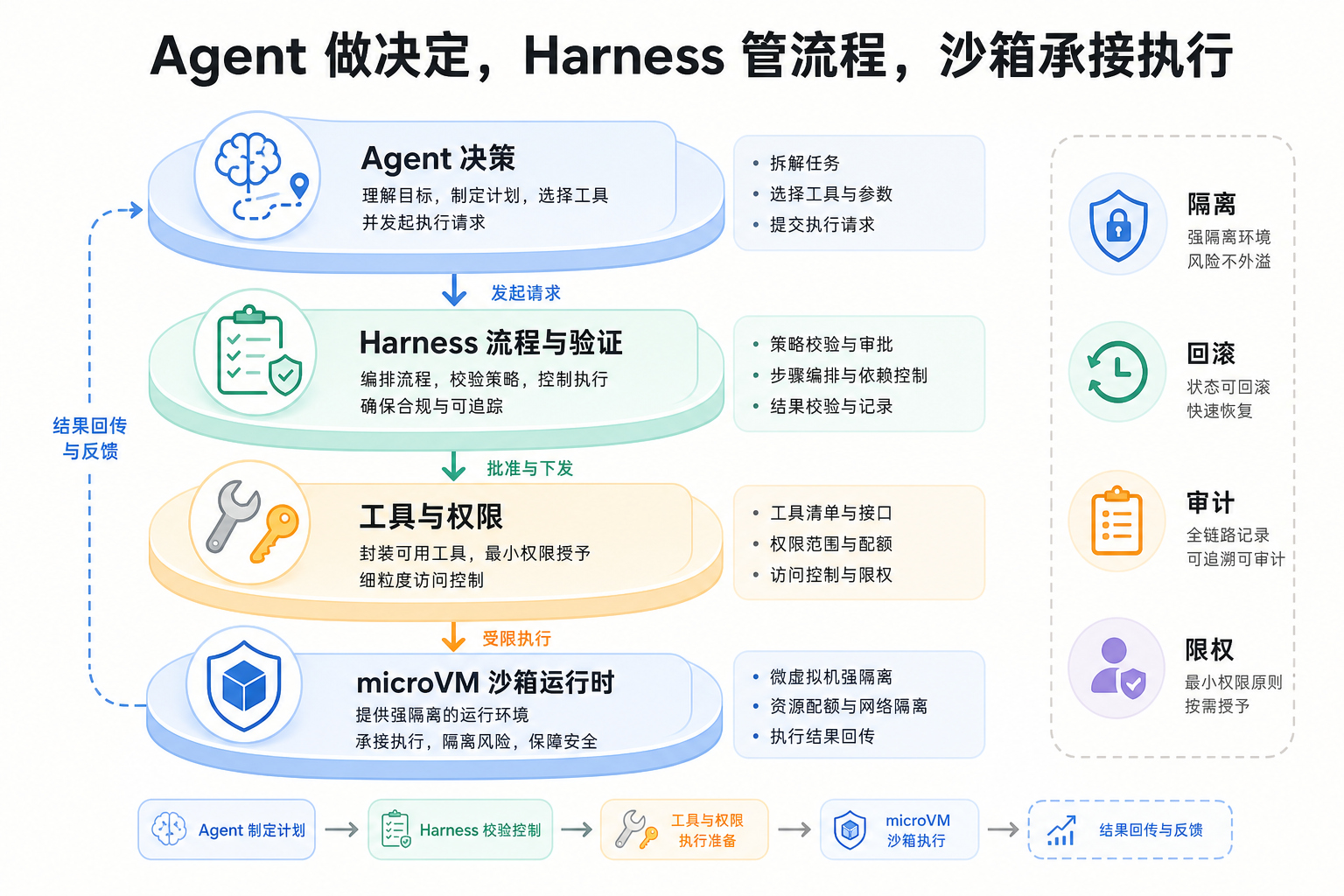
最后还是要回到 Agent 和 Harness 的关系。
Agent 负责提出行动、调用工具、观察结果、继续下一步。它像一个会自己想办法的执行者。
Harness 负责给这个执行者布置现场。它决定工具有哪些、权限到哪里、输出怎么验、失败怎么恢复、什么时候要人类确认。没有 Harness,Agent 很容易变成一个拿到 root 权限的实习生:很积极,也很危险。
forkd 补的是 Harness 里更靠底下的一层。它不判断一个补丁是不是正确,也不决定一个 Agent 应不应该访问某个 API。它提供的是“执行发生的地方”:一个可以快速复制、彼此隔离、继承状态、可观测、可销毁的 microVM 环境。
所以,Agent、Harness、sandbox(沙箱)不是三个并列概念。更像是三层关系:Agent 做决定,Harness 管流程,sandbox 承接执行。
如果未来的 AI Coding 平台只在模型层竞争,会很快进入同质化。真正拉开差距的,可能是这些不太显眼的底层能力:谁能让 Agent 更快地试错,谁能把每次试错隔离开,谁能在出事后知道它到底做过什么。
forkd 还很早,也不一定会成为最终标准。但它指向的方向很清楚:AI Agent 的安全不是一句“加个沙箱”就完了。沙箱会变成一整套运行时基础设施,而这套基础设施,很可能就是下一阶段 Agent 平台的护城河。
参考来源
- deeplethe/forkd GitHub README
- forkd DESIGN.md
- forkd v0.4 design
- forkd v0.5 diff snapshot chains design
- BestBlogs forkd 条目
以上来源用于观察 forkd 项目自身的技术设计、README benchmark 和社区收录口径,其中性能数字均来自项目方公开材料,不等同于独立基准测试。