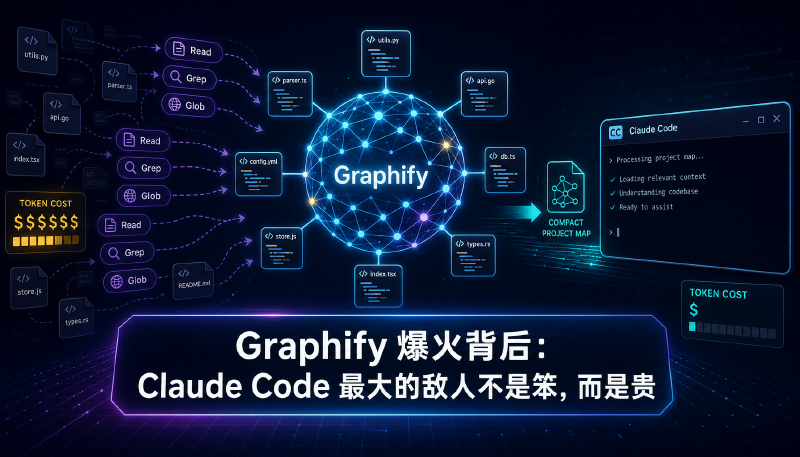
这两天,Claude Code 社区里有个工具被反复提到:Graphify。
它的卖点很直白:先在本地给你的代码库建一张知识图谱,再让 Claude Code 查询这张图,而不是每次都重新 Read、Grep、Glob 一遍项目。
作者在 Reddit 上说,/graphify 26 天拿到 45 万多次下载、接近 4 万 stars。Twitter 上也有人贴了实测:一个生产级 NestJS + Next.js SaaS 项目,同一个问题,不用 graphify-ts 时跑了 9 轮、96 秒、615K tokens;用了之后变成 3 轮、35 秒、234K tokens。
这些数字不一定能在每个项目里复现,但它戳中了一个很真实的问题:Claude Code 现在最贵的地方,很多时候不是写代码,而是反复理解代码。
AI 编程的瓶颈变了
刚开始用 Claude Code,最惊艳的是它终于能进代码库了。
它可以读文件、搜项目、跑命令、改代码、跑测试。以前 AI 像一个坐在屏幕外的顾问,你要把代码复制给它;现在它更像一个能进仓库干活的同事。
但项目一大,问题马上出现。
你问它:“这个登录流程为什么偶尔失败?”
它可能先搜 login,再读 auth 文件,再看 middleware,再看 session,再看数据库 schema,再看测试。中间哪一步不确定,它就继续读。第二天你换个角度问,它可能又来一遍。
这不是 Claude 不聪明,而是它没有一张可复用的项目地图。
人类工程师熟悉一个项目后,不会每次都从零开始读仓库。看到一个 bug,大概知道入口在哪、状态从哪来、哪些模块危险、哪些文件可以先跳过。AI 现在的问题是,它经常像一个很聪明但刚入职的工程师:能力够强,但每次都要重新 onboarding。
这就是 token 成本高、响应慢、上下文窗口紧张的根源。
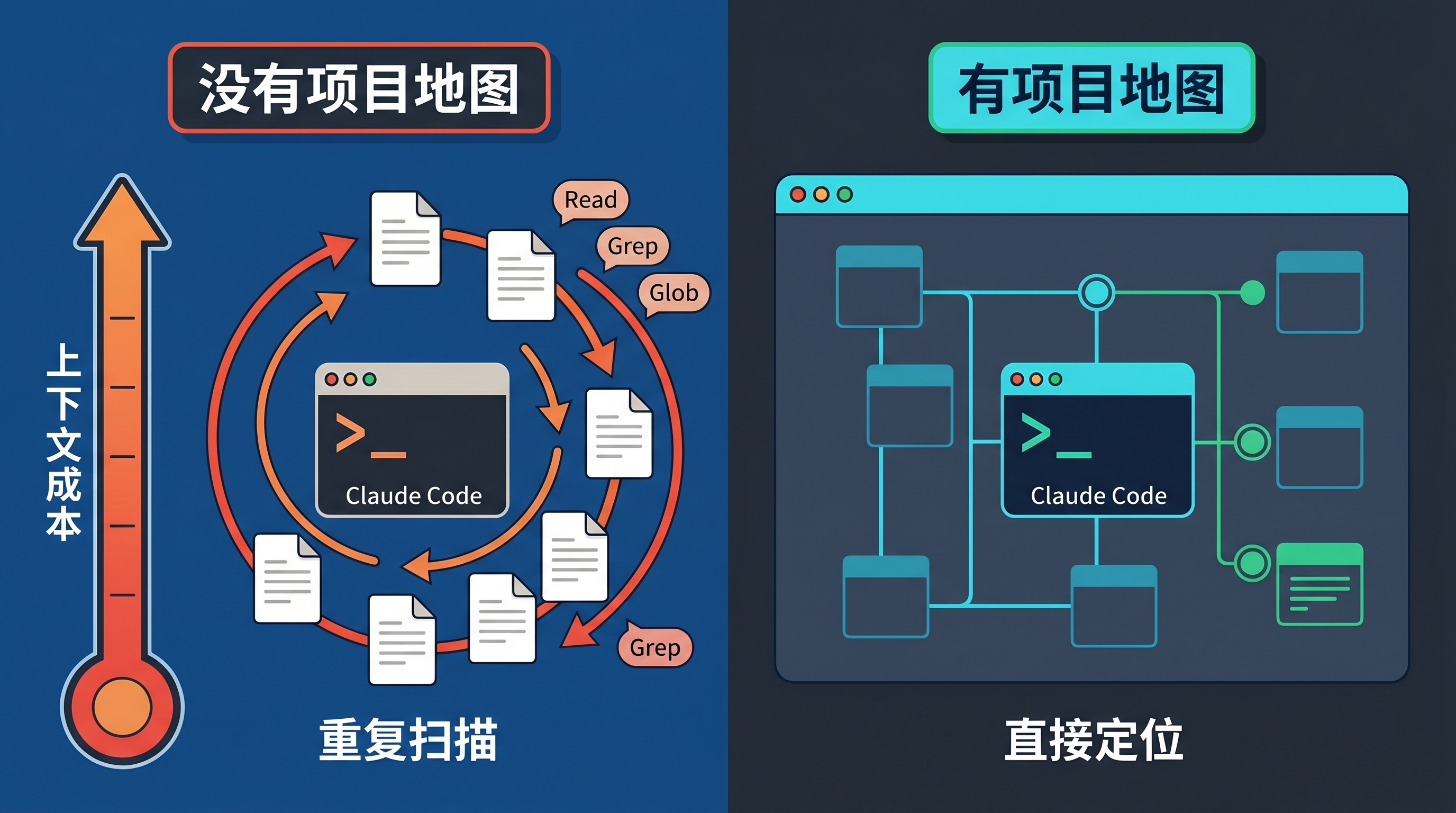
Graphify 想补的,就是这层“项目记忆”。
Graphify 到底做什么?
graphify-ts 的思路不复杂:
- 在本地扫描你的项目;
- 从代码、文档和项目文件里抽取结构;
- 生成
graphify-out/graph.json; - 通过 MCP 接入 Claude Code;
- Claude 遇到代码库问题时,可以调用
retrieve、impact、pr_impact等工具拿到结构化上下文。
它不是把代码上传到云端,也不需要 API key。按它的 README 说法,构建和查询都默认在本地完成:tree-sitter 解析、BM25 检索、图结构、可选本地 embedding,全都不走外部服务。
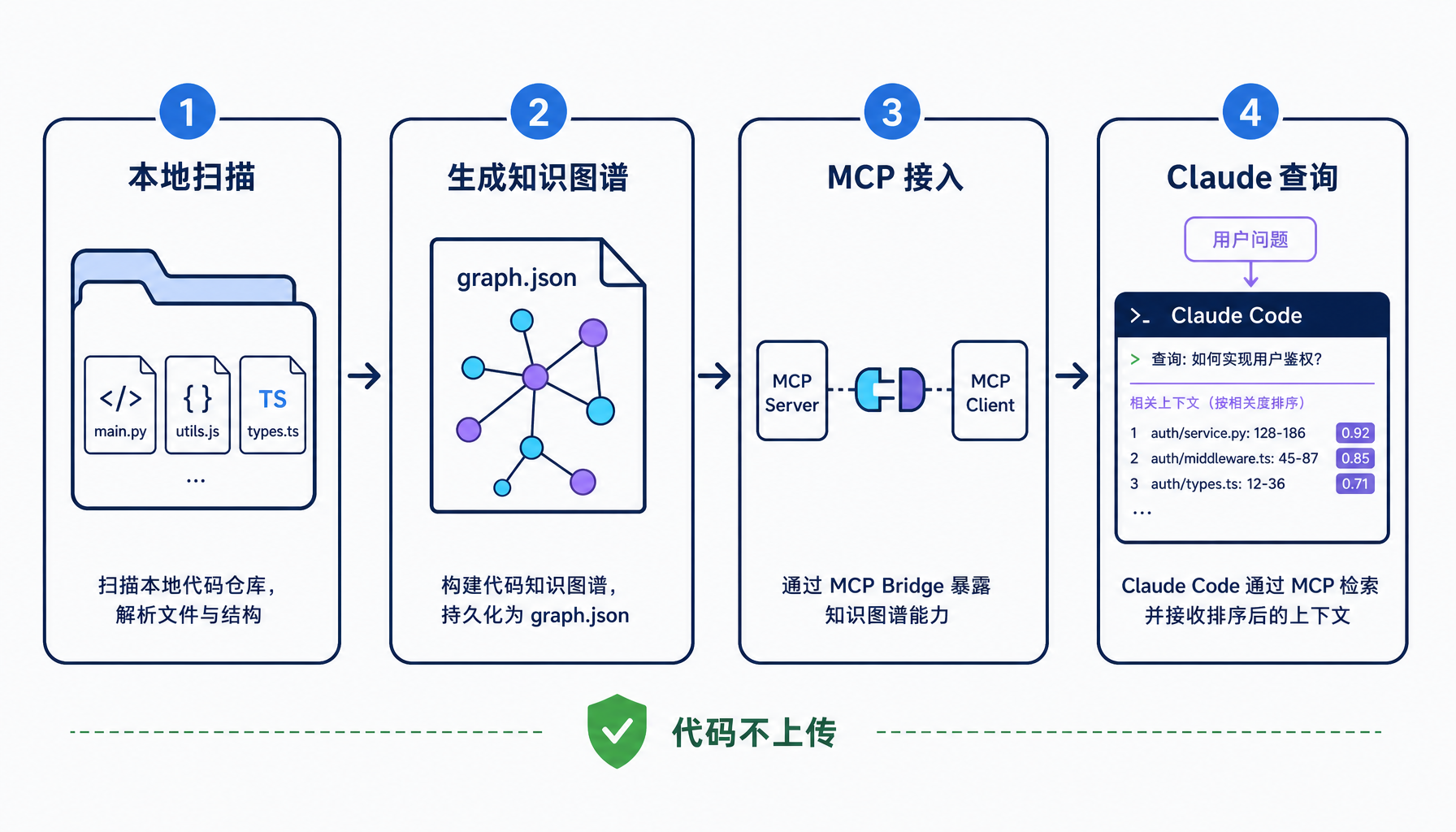
这点很重要。很多公司不是不想给 AI 做代码索引,而是不敢把代码库交给一个托管服务。Graphify 的吸引力就在这里:它走的是 local-first。
它和普通 RAG 也不完全一样。
RAG 更像是在文本里找相似片段。你问“登录失败”,它找看起来和登录相关的代码或文档。
但代码库不是普通文本。很多关键关系不在“语义相似”里,而在结构里:谁调用谁,哪个配置影响哪个运行路径,哪个测试覆盖哪个模块,哪个文件是某条链路的入口。
所以更准确地说:
grep解决“字符串在哪里”;- embedding 解决“相似内容在哪里”;
- Graphify 试图解决“项目结构关系是什么”。
这也是它适合 Claude Code 的原因。Claude Code 本来就擅长多步执行,但需要更好的起点。如果每次任务都从盲搜开始,成本自然高;如果先有一张项目图,它就能更快进入关键区域。
怎么安装和配置 Graphify
如果你想试,graphify-ts 的安装路径很短。前提是本机有 Node.js 20 或更高版本。
|
|
进入你的项目根目录:
|
|
这一步会生成:
|
|
然后把它接到 Claude Code:
|
|
完成后,在 Claude Code 里直接问项目相关问题即可。理想情况下,Claude 会通过本地 MCP 工具先查询 Graphify,而不是一上来反复扫文件。
常用命令还有几个:
|
|
用于文件变化后自动重建图。
|
|
用于对比使用 Graphify 前后的效果。
|
|
用于 PR review 场景的对比。
如果你不是 Claude Code 用户,它也提供其他安装入口:
|
|
不过我建议先别急着全项目长期接入。更稳的做法是找一个你熟悉的中型项目,先问几个固定问题做 A/B 对比:
- “这个认证流程从入口到数据库是怎么走的?”
- “如果我改这个模块,会影响哪些地方?”
- “这个 PR 最可能引入什么风险?”
看它是不是真的减少了 Claude 的搜索轮次、读取文件数量和响应时间。工具宣传的 benchmark 只能参考,自己的项目才算数。
它为什么会火?
我觉得原因很简单:Claude Code 用户开始算账了。
早期大家更关心模型够不够强。现在很多人已经把 Claude Code 放进真实项目里用,痛点变成了:一次任务要跑多少轮、读多少文件、烧多少 token、能不能复用上次的理解。
尤其最近 Claude Code 的定价和 Pro 计划争议很多,用户对成本更敏感。一个能减少重复上下文消耗的工具,自然会被放大。
Graphify 的火,也说明 AI 编程工具进入了第二阶段。
第一阶段是“让 AI 能做事”:读文件、跑命令、改代码、跑测试。
第二阶段是“让 AI 低成本地持续做事”:能复用项目结构,能理解长期上下文,能把任务拆成可验证的 workflow。
MindStudio 那篇关于 Claude Code workflow patterns 的文章也提到类似方向:复杂工程任务不是一次 prompt 能解决的,需要 sequential、operator、split-and-merge、agent teams、headless 这类不同工作流。Graphify 解决的不是完整工作流,而是其中非常关键的一层:让 agent 拿到更便宜、更结构化的项目上下文。
但别神化它
Graphify 不是魔法。
小项目可能用不上,直接 grep 和 Read 就够了。变化很快的项目,如果图不及时更新,反而可能误导 Claude。大量运行时动态生成、元编程、复杂框架约定,也不一定能被图完整表达。
而且图只能告诉 AI “关系可能在哪里”,不能替代验证。真正靠谱的 AI coding workflow,还是要跑测试、看 diff、做 review,涉及删除、部署、数据库写入这类高风险动作时必须保留人工确认。
我更愿意把 Graphify 看成一个上下文加速器,而不是自动编程外挂。
它解决的是“少绕路”,不是“永远不错”。
真正值得关注的是项目地图
Graphify 今天看起来像一个社区爆款工具,但它指向的可能是 AI IDE 的基础能力。
未来的 Cursor、Claude Code、Codex、JetBrains AI、VS Code Copilot,大概率都会内置类似的项目语义图。IDE 不只是保存文件树,还会持续维护一张项目地图:谁调用谁,哪些模块经常一起变化,哪些测试覆盖哪些行为,哪些文档解释哪些设计决策。
到那时,AI 编程工具的体验会变得不一样。
它不再每次都问:“这个项目是怎么回事?”
它会更像一个熟悉仓库的同事:知道从哪里下手,知道哪些地方危险,知道什么时候该读代码,什么时候该跑测试,什么时候该停下来问你。
所以 Graphify 这次火起来,表面上是一个工具传播。
更深一层,它提醒我们:AI 编程的竞争,正在从“谁的模型更聪明”,转向“谁能让模型更便宜、更稳定地理解真实项目”。
模型能力当然还重要。
但对每天写代码的人来说,下一阶段真正值钱的,可能是那张项目地图。