
我最近越来越觉得,很多 AI Agent 的问题不是“不够聪明”,而是“合作不了太久”。
刚开始用的时候,它确实像个新来的搭档。你把项目背景、写作偏好、目录结构、常用工具都告诉它,它能很快接住。你会有一种错觉:只要继续用下去,它会越来越懂你。
但过一阵子,味道就变了。
它还能回答问题,也能翻旧记录,可是很多判断接不上了。它不太记得上次为什么否掉某个选题,也不知道你后来改过哪些规则,更不会主动提醒你:这次的要求和上次定下来的原则有冲突。
这种体验很像和一个人连续合作了几周,结果每次开会前都要重新介绍一遍项目。
腾讯混元最近开源的 Hy-Memory,切中的正是这个问题。Hy-Memory 把长期 Agent 协作的痛点概括成一句话:第一周是思考伙伴,第三周沦为查询工具。它提出的办法,是给 Agent 做一个“第二大脑”:用 6 层记忆框架保存不同密度的信息,再用 System1 / System2 两套机制分别处理实时写入和后台整理。
我不想把它写成一篇“某某项目发布了什么功能”的新闻稿。更值得聊的是:为什么 Agent 明明有越来越长的上下文窗口,还是会在长期协作里变笨?
上下文窗口不是记忆

很多人第一次理解 AI 的“失忆”,都是从多轮对话开始的。
少数派最近有篇实践文章,作者从零做了一个 Raycast 形态的 AI Agent。他很快发现一个基础事实:模型并不知道上一轮发生了什么。所谓多轮对话,本质上是程序把前几轮消息重新塞回去,让模型在这一轮“看起来记得”。
这个办法当然能用。我自己做各种自动化脚本时,也经常这么处理。
但它有个问题:越往后越难收拾。
只塞最近几轮,早期信息会丢;塞太多历史,token 成本会涨,噪声也会变多;再往后只能压缩,把旧对话总结成摘要。摘要又会带来另一个问题:它通常能保留“发生了什么”,但很难保留“当时为什么这么判断”。
这就是上下文和记忆的区别。
上下文更像开会前临时翻出来的一沓资料。资料越厚,当然越不容易漏东西,但你也越容易被无关细节带偏。记忆不一样。记忆是你做过一个项目之后留下来的经验:哪些原则已经验证过,哪些坑不要再踩,某个方案当时为什么被放弃,用户后来为什么推翻了原来的偏好。
如果 Agent 只靠上下文,它每次都像重新入职。
你可以给它一份很厚的入职材料,但它仍然缺少“跟你一起做过事”的沉淀。
这也是为什么单纯扩大上下文窗口解决不了长期协作。100 万 token 的窗口当然很厉害,可如果里面混着旧需求、废弃方案、临时讨论、过时偏好和当前目标,模型仍然要在一堆互相打架的信息里猜哪条更重要。
真正麻烦的不是“能不能放进去”,而是“放进去以后,谁来判断它还值不值得影响下一次决策”。
真正该记住的,往往不是原话
把 Agent 记忆理解成“长期保存聊天记录”,其实低估了这件事。
聊天记录只是原料。长期协作真正需要留下来的,是从原料里提炼出来的经验。
比如我在这个 Obsidian 仓库里写 Hugo 博客,文章目录在 博客/content/post/,frontmatter 里 categories 要用文本格式,tags 要用数组。这个事实如果每次都忘,就会反复犯低级错误。
再比如,我更喜欢工程化、结构清楚、少一点口号感的文章;没有明确要求时,不要主动做 git commit;路径里有空格时一定加引号。这些不是某个任务的显式需求,但它们会持续影响合作质量。
更难保存的是决策背后的因果。
一个选题被淘汰,不只是因为“已经写过”。有时候是因为它和已发布文章在事件主体、来源 URL、核心角度上都重合。下次再遇到类似题目,Agent 应该记住的不是某个文件名,而是这个判断框架。
还有一种更微妙:偏好会变,规则会变,判断标准也会变。
一个靠谱的长期 Agent 不能只记住“用户曾经说过 A”,还要知道后来为什么从 A 改成了 B。否则它会把旧规则当成铁律,在新场景里制造麻烦。
Hy-Memory 的 6 层记忆框架,吸引我的地方就在这里。它从 L1 原始痕迹一路分到 L5 心智模型、L6 知识网络。这个设计至少承认了一件事:记忆有密度差异。
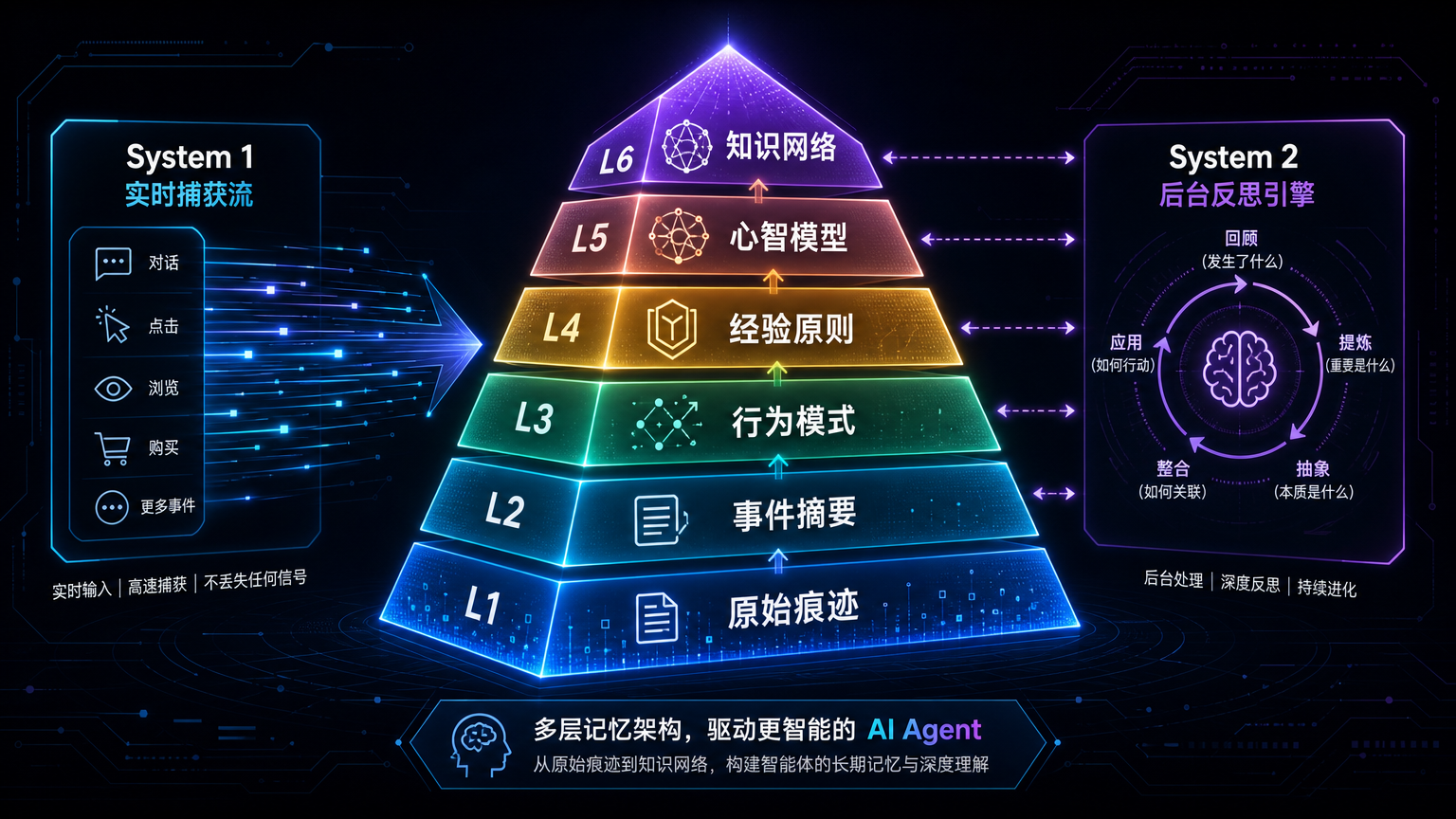
原始记录、事件摘要、行为模式、心智模型、知识关系,不应该混在同一个抽屉里。
底层回答“当时发生了什么”;中层回答“什么模式反复出现”;高层回答“这个用户、这个项目背后有哪些稳定原则”。如果没有这些区分,长期记忆很容易变成一个更大的历史垃圾堆。
“三周后变笨”,可能只是没有复盘
为什么一个 Agent 刚开始好用,后来反而变笨?
我的理解是:它没有把经历变成经验。
人不是这样工作的。你不会记住每次会议的每一句话,但你会记住某个同事特别在意上线风险,某个产品经理总会优先考虑转化率,某类需求以前踩过坑,某个技术方案被放弃是因为维护成本太高。
人会把大量经历压缩成模式和原则。
Agent 如果缺少这个过程,就会在两个极端之间摇摆。
一种是过度遗忘。每个 session 都像新对话,只能靠用户重新交代背景。
另一种是过度保留。所有旧信息都被塞回来,模型看似知道很多,其实分不清哪些还有效。它会引用一个已经废弃的方案,沿用一个已经被修正的偏好,或者把一次临时讨论当成长期规则。
用户感受到的“变笨”,很多时候不是推理能力下降,而是合作上下文没有被正确整理。新的经验没有晋升成稳定记忆,旧的记忆没有被降权,冲突信息没有合并,判断因果也没留下来。
Hy-Memory 提到的 System1 / System2,可以放在这里理解。
System1 像实时记账。用户刚说了什么,任务刚发生了什么,工具刚返回了什么,都要快速写下来,否则下一轮就断片。
System2 像复盘。它不追求马上响应,而是在后台慢慢整理:哪些只是一次性事件,哪些值得长期保存;哪些偏好反复出现,哪些旧判断已经被新事实推翻;哪些信息可以压缩,哪些因果链必须保留。
只有 System1,Agent 会越记越乱。
只有 System2,又很难接住当下任务。
长期协作需要的是两者配合:当下别忘,事后会想。
Skills 像菜谱,Memory 像经验
最近 Agent 产品里另一个常见词是 Skills。
少数派那篇文章里有个例子很典型。作者想让自己的 Agent 获取少数派最新文章。一开始让模型自己探索,结果它搜索、抓首页、找社媒、解析页面都试了一遍,失败好几次,最后才发现 RSS 是更稳定的路线。
于是作者把这条经验写成一个 skill:下次遇到同类任务,就按固定步骤走,读取 RSS,拿第一个链接,再抓正文总结。
这很像给 AI 一本菜谱。
Skills 的价值,是把可复用流程外置出来,减少模型自由发挥。处理少数派最新文章怎么走、发布 Hugo 文章怎么走、检查 Markdown 怎么走,这类事情很适合写成 skill。
但 Skills 解决的是“怎么做”,不是“为什么这么做”。
它能告诉模型处理少数派最新文章要读 RSS,却不一定知道为什么上次不用浏览器抓取,为什么用户更信任 RSS,为什么这条流程后来需要修订。如果少数派改版了,旧 skill 失败后应该怎么更新,这就不是一条菜谱能完全解决的。
Memory 的位置就在这里。
Skills 让 Agent 少走弯路;Memory 让 Agent 知道这些弯路为什么不该再走。
一个成熟的 Agent 系统,大概率需要两者同时存在。Skills 存放稳定流程,Memory 存放经验、偏好、因果和变化。前者像操作手册,后者更像项目老员工脑子里的那部分东西。
工具让模型能做事,Skills 让模型按更稳的方式做事,Memory 让模型在长期合作中慢慢知道为什么要这么做。
第二大脑也可能变成黑箱
不过,Agent 记忆不是越多越好。
一个能长期记住你的 AI,听起来很诱人,也有风险。
最直接的是隐私。长期记忆里会有项目资料、个人偏好、工作习惯、关系网络,甚至还有一些用户自己都没意识到的行为模式。如果这些数据没有清晰的存储边界、删除机制和可见性,所谓第二大脑就会变成一个难以审计的黑箱。
还有错误固化。
如果 Agent 把一次误解晋升成长期记忆,后面每次都会带着这个误解工作。它可能错误地判断用户“不喜欢技术细节”,以后写文章就持续变浅;也可能把某次临时要求当成永久规则,反复执行不合时宜的操作。
更麻烦的是过度个性化。
一个太懂你的 Agent,可能会越来越会迎合你。它知道你喜欢什么表达、讨厌什么观点、倾向什么判断,于是更容易给出让你舒服的答案,而不是让你重新检查假设的答案。
这和 AI 顾问的 sycophancy 问题是连在一起的。记忆越强,迎合也可能越精确。
所以,判断一个 Agent 记忆系统好不好,不能只看它记得多不多。我更关心几个朴素的问题:一条记忆从哪里来,能不能解释;它是事实、偏好、猜测,还是模型推断;新事实出现时,旧记忆能不能被修正;用户能不能查看、编辑、删除、禁用某些记忆。
如果这些问题没有答案,长期记忆不一定是能力增强,也可能是风险放大器。
先别急着做“全知助手”
如果你正在做 Agent 产品,Hy-Memory 这类系统最大的启发,不是马上照着做一个六层架构。
更现实的起点,是先问清楚:你的 Agent 到底需要记住什么?
客服 Agent 可能只需要记住工单状态、用户偏好和已经尝试过的方案。编程 Agent 更需要记住项目结构、代码规范、失败过的修复路线和用户确认过的技术决策。写作 Agent 则要记住选题边界、语气偏好、已发布内容和常用素材来源。
记忆系统应该从任务类型反推,而不是从架构名词出发。
一个最小可用的 Agent 记忆层,未必复杂。先把原始记录和长期规则分开,不要把聊天摘要直接当规则;给每条长期记忆保留来源和时间,让用户能追溯它为什么存在;允许记忆被更新和废弃,因为长期协作里的“忘记”和“记住”一样重要。
这些事情做扎实了,再谈更复杂的分层、后台整合和知识网络,才比较稳。
否则,记忆系统很容易变成新的 prompt 垃圾场。你以为自己在给 Agent 加第二大脑,实际只是给它塞了一个更大的剪贴板。
如果想自己试,Hy-Memory 怎么装
前面说的都偏原理。真要上手,目前 Hy-Memory 最直接的方式,是通过 OpenClaw 插件体验。
官方 quick start 里说得比较清楚:Hy-Memory 不是一个单独给终端用户打开的 App,而是以 OpenClaw 插件形式分发。插件启动时,会拉起一个本地 Python 子进程,对外提供记忆读写服务;OpenClaw 在对话前后调用它,完成自动召回和自动写入。
所以你需要先准备几样东西:本机能执行 openclaw 命令;Python 版本不低于 3.8;手上有一个可用的 LLM API Key;再准备一个 Embedding 服务。官方示例里,LLM 用的是通过 OpenRouter 调用的 Hunyuan 3.0 Preview,Embedding 用的是 SiliconFlow 的 BAAI/bge-m3。
安装命令很短:
|
|
如果你之前装过旧版本,官方建议先卸载再重新安装:
|
|
这里最刺眼的是 --dangerously-force-unsafe-install。它不是装饰。Hy-Memory 会随插件启动本地 Python 进程,OpenClaw 默认会拦住这类会拉起外部进程的插件,所以必须显式确认。
装完以后,推荐先走交互式初始化:
|
|
它会提示你填 LLM 和 Embedding 的 model、apiKey、endpoint。第一次接入建议用这个方式,少踩 JSON 格式错误的坑。
如果你想手写配置,核心大概是下面这样:
|
|
这几个字段不难理解。
userId 用来区分不同用户的记忆数据;autoRecall 决定每轮对话前是否自动召回相关记忆;autoCapture 决定每轮对话后是否自动抽取并写入新记忆;topK 是每次最多召回几条。llm 负责把对话整理成记忆,embedder 负责向量化,vectorStore 默认用本地 Chroma。
配置完成后,重启 OpenClaw 网关:
|
|
再检查状态:
|
|
如果一切正常,你会看到类似 registered、Status: healthy、VDB: ok、Embed: ok、LLM: ok 这样的信息。这里有几个关键点:registered 说明插件已经被 OpenClaw 识别;healthy 说明本地 Hy-Memory 服务正常;VDB 是向量库状态;Embed 和 LLM 则分别说明 Embedding 与模型接口可用。
装好之后,不需要每次手动告诉它“请保存记忆”。在 autoRecall 和 autoCapture 都开启的情况下,它会在对话开始前召回相关历史,在对话结束后抽取新的记忆。你真正需要调的,通常是召回数量、是否自动捕获、用户 ID,以及 LLM / Embedding 服务的稳定性。
还有一个容易混淆的点:腾讯同时有一个 TencentDB-Agent-Memory 项目,它更像是通用 Agent Memory 插件,支持 OpenClaw 和 Hermes,默认本地 SQLite + sqlite-vec,也支持 Docker 方式接 Hermes。它和 Hy-Memory 的目标接近,但安装包名、配置方式不一样。如果你看到 @tencentdb-agent-memory/memory-tencentdb,那是另一条接入路线:
|
|
这个插件可以零配置启用:
|
|
它默认用本地 SQLite + sqlite-vec 后端,启用后会自动完成对话录制、记忆提取、场景归纳、用户画像生成和下一轮对话前召回。它还提供了更工程化的短期记忆压缩、BM25 + 向量混合检索、Mermaid 任务画布等能力。
简单说,如果你只是想最快体验 Hy-Memory,就按 openclaw-hy-memory 的 quick start 走;如果你想看腾讯这套 Agent Memory 工程化插件的完整形态,可以再研究 TencentDB-Agent-Memory。
从“单次聪明”到“长期靠谱”
过去评价一个 AI,我们常常看它单次回答有多聪明:代码能不能写出来,文章能不能成稿,推理题能不能答对,工具能不能调用成功。
但 Agent 真正进入工作流之后,评价标准会变。
你不会只看一个同事第一天表现多惊艳。你会看他三周后还记不记得项目边界,三个月后能不能复用之前的经验,半年后会不会在新情况出现时修正旧判断。
AI Agent 也一样。
短期任务里,模型能力和工具调用很重要。长期协作里,记忆治理会变得同样重要。它决定 Agent 是一个每次都要重新培训的临时外包,还是一个能慢慢积累项目经验的长期伙伴。
Hy-Memory 的价值,不只是多了一个记忆插件,而是把一个迟早要面对的问题摆出来了:Agent 不只要会执行,还要能沉淀经验;不只要记住内容,还要记住内容背后的因果、偏好和变化。
如果说前两年的 Agent 竞争,主要围绕能不能调用工具、能不能完成任务,那么接下来更值得看的问题会是:它能不能在长期合作里,越来越像一个真正理解项目的人?
答案不会只来自更大的上下文窗口,也不会只来自更强的模型。
它更可能来自一套不太炫、但很难做好的记忆工程:该记的要记住,该忘的要忘掉,过时的要降权,冲突的要解释,重要的经验要从一堆聊天碎片里慢慢长出来。
这不像一次模型发布那样热闹。
但如果 Agent 真的要成为工作伙伴,这一步绕不过去。
参考来源
- Hy-Memory OpenClaw Quick Start
- TencentDB Agent Memory 中文 README
- 少数派:AI Agent 干中学,“造轮子”让我学会了什么?
- BestBlogs 今日精选:Hy-Memory 发布:打造记忆力超强的 Agent 第二大脑(资源 ID:
RAW_b4500725) - Paddy & Bora Jam: Agent Harness, Claude Code At The Beach, MCP, Agent Buying Stock?