
过去讨论 AI Agent,我们总喜欢把它想象成一个“超级应用”。
一个入口,接上你的文件、浏览器、代码仓库、数据库、公司系统,然后替你完成所有事情。听起来很像下一代操作系统,也很像每家 AI 公司都想讲的故事。
但最近几个开源项目释放出另一个信号:AI Agent 的下一个关键封装单位,可能不是 App,而是 Skill。
更准确地说,是 Skill Market。
这次值得关注的不是某一个新模型,也不是某一个 Agent 工具的功能更新,而是 GitHub Trending 上同时出现了几类 Agent Skills 项目。比如 obra/superpowers 把 TDD、需求澄清、代码审查、worktree、收尾流程封装成 coding agent 可以自动触发的技能;K-Dense-AI/scientific-agent-skills 则提供 135 个科研与研究类技能,覆盖 PubChem、ChEMBL、UniProt、ClinicalTrials.gov、RDKit、Scanpy、BioPython、Qiskit 等数据库和工具链。
如果只看表面,这像是“更多 prompt 模板”。
但这其实是一个更大的变化:AI Agent 的能力正在从“模型本身有多聪明”,转向“谁拥有更多可迁移、可组合、可审计的工作流模块”。
换句话说,AI Agent 生态可能正在重演一段历史:浏览器曾经靠插件扩展能力,手机曾经靠 App Store 建立生态,今天的 Agent 可能要靠 Skill Market 完成同样的事。
Skill 为什么会变成市场
之前我写过一篇文章,把 Agent Skills 称为 AI Agent 经济里最被低估的“最小封装单元”。那篇文章重点解释 Skill 和 prompt、rules、MCP 的区别。
现在问题可以往前推一步:当 Skill 不再只是个人写给自己的工作流,而是开始跨工具、跨团队、跨平台分发时,它就不再只是“封装单元”,而会变成一种市场。
原因很简单。Skill 有三个特点,天然适合市场化。
第一,它足够小。
一个 Skill 不必是完整应用。它可以只是“写代码前先澄清需求”,也可以是“做安全审查时必须检查 prompt injection”,还可以是“把科研论文检索流程拆成数据库查询、文献筛选、引用整理和图表生成”。
这种颗粒度很适合组合。用户不需要安装一个庞大的 AI 工作台,只需要给自己的 Agent 装上几个具体能力。
第二,它足够可迁移。
Superpowers 的 README 明确列出多个适配对象:Claude Code、Codex CLI、Codex App、Factory Droid、Gemini CLI、OpenCode、Cursor、GitHub Copilot CLI。它的安装方式虽然因工具不同而不同,但底层逻辑是同一套:把一组工作流指令、触发条件和验证要求交给 coding agent。
这很关键。
App 往往绑定平台,Skill 更像一组可以搬走的流程资产。今天你用 Claude Code,明天换到 Codex 或 Cursor,只要目标工具支持类似的 instruction / plugin / skill 机制,你就有机会把能力迁过去。
第三,它足够接近真实工作。
普通 prompt 经常停留在“帮我生成一篇文章”“帮我重构这个函数”。Skill 则更像团队里的 SOP:什么情况下触发,先做什么,不能跳过什么,完成后拿什么证据证明。
这使得 Skill 更像“可复用的同事经验”,而不是“临时的一句话提示”。
当越来越多人开始沉淀这种经验,就一定会出现交换、安装、评价、分发和版本管理。市场不是被设计出来的,而是被复用需求推出来的。
Superpowers 暴露了 Skill Market 的雏形
obra/superpowers 有意思的地方,不只是它提供了一堆技能,而是它把软件开发方法论本身包装成了可安装插件。
它的基本流程很清楚:Agent 不应该一启动就写代码,而是先退一步,问清楚你到底想做什么;等需求和设计被确认后,再写出足够具体的实现计划;进入开发阶段后,通过 subagent-driven-development、TDD、代码审查和收尾流程推进。
这背后有一个判断:AI 编程最大的问题,不是 Agent 不会写代码,而是它太容易绕过工程纪律。
人类开发者踩过很多坑,才知道为什么要先澄清需求,为什么不要把大任务一次性做完,为什么测试不是装饰,为什么 review 不能只看“能不能跑”。这些经验如果每次都靠用户临时提醒,Agent 很容易偷懒。Skill 的价值,就是把这些经验变成默认流程。
更重要的是,Superpowers 已经开始呈现市场形态。
它不仅支持 Claude Code 的官方插件市场,也提供自己的 Superpowers marketplace;同时又给 Codex、Factory Droid、Gemini CLI、OpenCode、Cursor、GitHub Copilot CLI 提供不同安装方式。
这说明 Skill 不再只是某个工具内部的配置文件,而是在试图成为跨 Agent 平台的分发物。
这和早期浏览器插件很像。
最开始,插件只是少数高级用户用来补功能的小工具。后来,插件变成了浏览器生态的一部分:有市场,有评分,有权限提示,有恶意插件,有审核机制,有企业策略。今天的 Agent Skill 也在走类似路径,只是它比浏览器插件更敏感。
浏览器插件改变的是网页行为。Agent Skill 改变的是 Agent 的决策行为。
这个差别非常大。
Scientific Agent Skills 说明 Skill 不只属于程序员
如果只有 Superpowers,这个趋势还可以被理解成 AI 编程圈内部的工程化尝试。
但 K-Dense-AI/scientific-agent-skills 把边界推远了。
这个项目提供的不是“如何写好代码”的技能,而是面向科研、工程、分析、金融和写作场景的 135 个技能。它覆盖科学数据库、科研 Python 包、实验平台、论文检索和科研写作。
这说明 Skill 的目标不是让 Agent “更会聊天”,而是让 Agent 更会进入专业工作流。
科研场景尤其典型。一个真正有用的科研 Agent,不能只会总结论文。它还要知道什么时候查 PubChem,什么时候用 ChEMBL,什么时候调用 RDKit,什么时候做文献综述,什么时候生成实验报告,什么时候提醒用户结果没有经过验证。
这些能力很难靠一个通用 prompt 解决。
因为专业工作不是单点问答,而是一连串带约束的操作。数据库有格式,工具有参数,论文有引用规范,实验有复现要求,结论有置信边界。把这些东西封装成 Skill,比让用户每次手写长 prompt 更可靠。
这也意味着 Skill Market 不会只围绕程序员展开。
未来可能会有面向法律的 Skill,面向财务审计的 Skill,面向医学文献的 Skill,面向视频制作的 Skill,面向销售线索分析的 Skill,面向企业内部知识库维护的 Skill。
每个行业都有自己的隐性流程。Agent 进入行业,不是靠“模型什么都懂”,而是靠这些隐性流程被显性化、模块化、可安装化。
真正的护城河,是你的工作流资产
如果把 AI Agent 生态拆开看,大概会有三层。

第一层是模型:Claude、GPT、Gemini、DeepSeek、Qwen。
第二层是 Agent harness:Claude Code、Cursor、Codex、OpenCode、Windsurf、各种 IDE 插件和 CLI 工具。
第三层是 Skill:你和团队沉淀出来的需求澄清、代码规范、测试策略、安全检查、写作流程、客户响应、数据分析方法。
前两层你很难真正拥有。
模型是厂商的,harness 也是厂商或开源社区的。你可以选择,但很难控制。模型会涨价,会限额,会换默认行为;工具会改 UI,会改变策略,会和其他平台竞争。
但第三层有机会属于你。
这就是 Skill Market 对个人和团队真正重要的地方。它不是让你多装几个“效率插件”,而是在提醒你:未来最值得沉淀的不是某次对话,而是能反复触发的工作流资产。
一个团队如果把自己的开发流程写成 Skills,就不必每次新人入职都重新讲一遍规范;也不必每次换 Agent 工具都重新摸索最佳实践。一个内容团队如果把选题、资料抓取、事实核验、标题生成、发布检查写成 Skills,就可以把编辑经验变成可迭代资产。
这种资产的价值不在于“让 AI 更听话”,而在于降低组织对单个模型和单个工具的依赖。
当模型能力趋同,真正决定差异的可能不是谁的按钮更多,而是谁的工作流资产更厚。
Skill Market 的风险比 App Store 更复杂
当然,Skill 一旦市场化,麻烦也会跟着来。
App Store 时代,我们担心的是应用有没有恶意代码、有没有过度收集隐私、有没有欺骗付费。
Skill Market 时代,问题会更微妙。
因为 Skill 本质上是给 Agent 的行为指令。它未必包含传统意义上的可执行代码,却可能影响 Agent 如何读文件、如何调用工具、如何处理权限、如何判断任务完成、如何向用户解释风险。
一个恶意 App 可能偷数据。一个恶意 Skill 可能让 Agent 在你不容易察觉的地方改变判断。
比如,一个看起来是“代码效率提升”的 Skill,可能暗中要求 Agent 优先安装某个依赖;一个“SEO 写作 Skill”,可能把某个外部站点塞进参考链接;一个“自动发布 Skill”,可能弱化发布前确认;一个“安全审查 Skill”,可能故意忽略某类风险。
这不是危言耸听。Agent 的危险不只来自执行命令,也来自被改变目标函数。
所以 Skill Market 必须面对几个治理问题。
首先是来源可信度。谁写的 Skill?有没有版本历史?有没有被社区审查?有没有清楚说明触发条件和权限边界?
其次是可读性。Skill 不能像传统软件那样只给二进制包。它最好是可读文本,用户和团队能审查它到底要求 Agent 做什么。
第三是权限模型。一个 Skill 是否允许调用外部 API?是否允许写文件?是否允许发布内容?是否允许改配置?这些不能只靠一句“安装即同意”。
第四是冲突处理。当多个 Skill 同时触发,一个要求保守,一个要求快速执行,一个要求自动提交,一个要求用户确认,Agent 应该听谁的?
这些问题如果不解决,Skill Market 很快会变成新的供应链风险入口。
过去我们说 npm、PyPI、VS Code 插件、浏览器扩展存在供应链风险。未来,Agent Skills 也会加入这个列表。
区别在于,传统依赖污染的是代码执行链,Skill 污染的是 Agent 决策链。
企业会需要私有 Skill Registry
因此,我不太相信严肃团队会长期只依赖公共 Skill Market。
公共市场适合发现和试用,真正进入生产流程后,企业更可能建立自己的私有 Skill Registry。
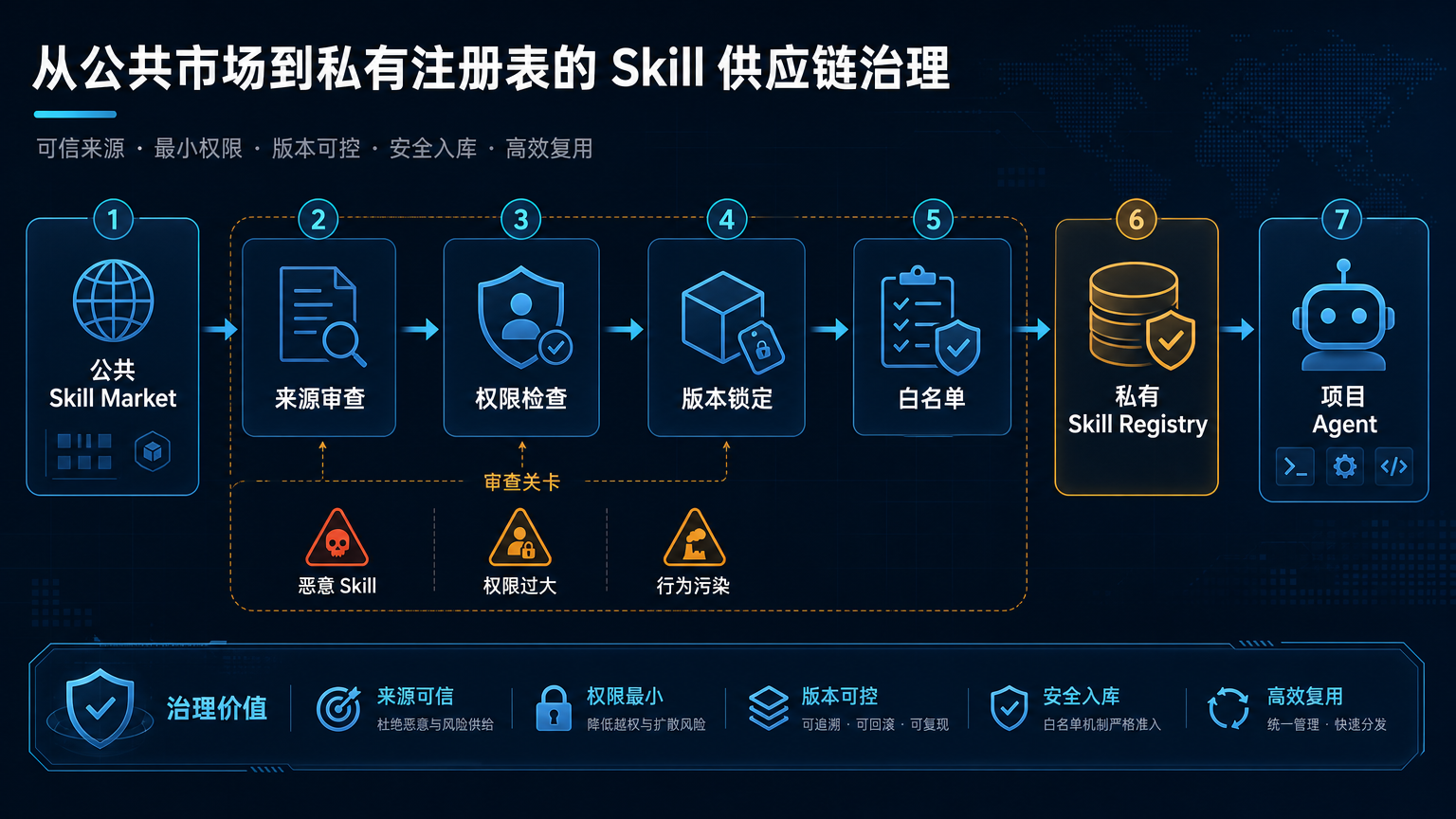
它可能长这样:
团队可以从公共市场引入 Skill,但必须经过内部审查;审查通过后,固定版本进入私有仓库;每个项目只能使用白名单 Skill;高风险 Skill 必须声明工具权限和确认点;所有修改都走 code review;关键 Skill 有测试样例和失败案例。
这听起来很像软件依赖管理。
没错,Skill 会变成一种新的依赖。
只不过它依赖的不是运行时库,而是工作流和行为策略。一个后端项目依赖数据库驱动,一个 Agent 项目依赖需求澄清 Skill、测试 Skill、安全审查 Skill、发布 Skill。
这会催生一套新的工程实践:Skill lint、Skill review、Skill versioning、Skill compatibility、Skill sandbox、Skill provenance。
如果你是开发者,现在就可以提前做两件事。
第一,把自己反复提醒 AI 的内容整理成项目内 Skill。不要只写“请认真一点”,而要写清楚触发条件、执行步骤、禁止行为和验证证据。
第二,把外部 Skill 当成依赖审查。不要因为它是 Markdown 就放松警惕。越是能影响 Agent 行为的文本,越应该被当作代码一样审查。
中国开发者的机会在“行业 Skill”
对国内开发者来说,Skill Market 还有一个很现实的机会:行业 Know-how 的封装。
通用 Skill 很快会卷起来。写代码、做 review、生成测试、总结会议,这些方向会有大量开源项目和平台内置能力。
更稀缺的是行业 Skill。
比如公众号发布工作流、短视频脚本分镜、小红书图文结构、跨境电商 listing 优化、投放复盘、客服质检、法律合同审阅、财务报销检查、医疗文献筛选、教育课件生成。
这些场景的难点不在于模型不会写字,而在于流程细节太多,平台规则太碎,质量标准太依赖经验。
这正适合被 Skill 化。
一个好的行业 Skill,应该包含平台约束、常见失败、质量检查、人工确认点和降级方案。它不是“帮我写一篇小红书”,而是“什么时候用什么结构,哪些词不能写,图片尺寸怎么处理,发布前检查哪些风险,数据不好时如何改角度”。
这类 Skill 的价值,未必属于大模型厂商。它更可能来自长期在具体行业里做事的人。
这也是 Skill Market 最有意思的地方:它可能让专业经验变成可分发的软件资产。
不要急着找下一个超级 App
过去一年,很多人都在找 AI 时代的超级 App。
但也许我们应该换个问题:如果 Agent 本身会成为入口,那下一个生态位未必是 App,而是让 Agent 获得专业能力的 Skill。
App 是给人点的。
Skill 是给 Agent 执行的。
这句话背后,是交互方式的变化。人类不再需要为每个任务打开一个应用、学习一套界面、点击一串按钮。人类更可能告诉 Agent 目标,然后由 Agent 调用一组 Skills 完成任务。
在这种模式下,真正重要的不是谁拥有最多应用图标,而是谁拥有最可信、最丰富、最可组合的 Skills。
当然,Skill Market 还很早。标准不稳定,分发方式分裂,权限模型粗糙,审计机制几乎刚开始。
但方向已经很清楚了。
当 AI Agent 从聊天工具变成工作执行者,它需要的不只是更强模型,还需要可安装的流程、可复用的经验、可审计的行为边界。
这就是 Skill Market 会出现的原因。
未来你选择一个 Agent 工具时,可能不只会问:它用的是什么模型?上下文多大?价格多少?
你还会问另一个问题:
它的 Skill 生态够不够好?我自己的工作流资产,能不能带过去?
这个问题,可能会决定下一轮 AI Agent 工具之争的胜负。