这篇文章基于 SecurityWeek 对 AI coding agents 供应链风险的报道 和 The Register 对 Claude Code trust prompt 争议的报道 展开。文中不把单个案例扩大成确定性结论,而是讨论 AI 编程助手进入开发流程后,软件供应链安全正在出现的新攻击面。
过去攻击开发者,最经典的路径是投毒依赖包。
上传一个名字相似的 npm 包,伪装成热门库;在开源项目里混入恶意代码,等待下游自动更新;偷走 CI/CD 凭据,在构建链路里植入后门。这类攻击的共同点是,它们最终都要让某段恶意代码被执行。
但 AI 编程助手改变了这个前提。
因为它不是只执行代码,它还会阅读代码之外的东西。README、issue、commit message、注释、终端输出、网页文档、错误日志,甚至某个项目里看起来像说明文档的文本,都可能被它当成任务上下文。只要这些内容进入模型窗口,就有机会影响它接下来怎么理解任务、怎么修改代码、怎么调用工具。
这就是 AI 编程时代的供应链新问题:攻击者未必需要投毒代码,投毒上下文就可能够了。
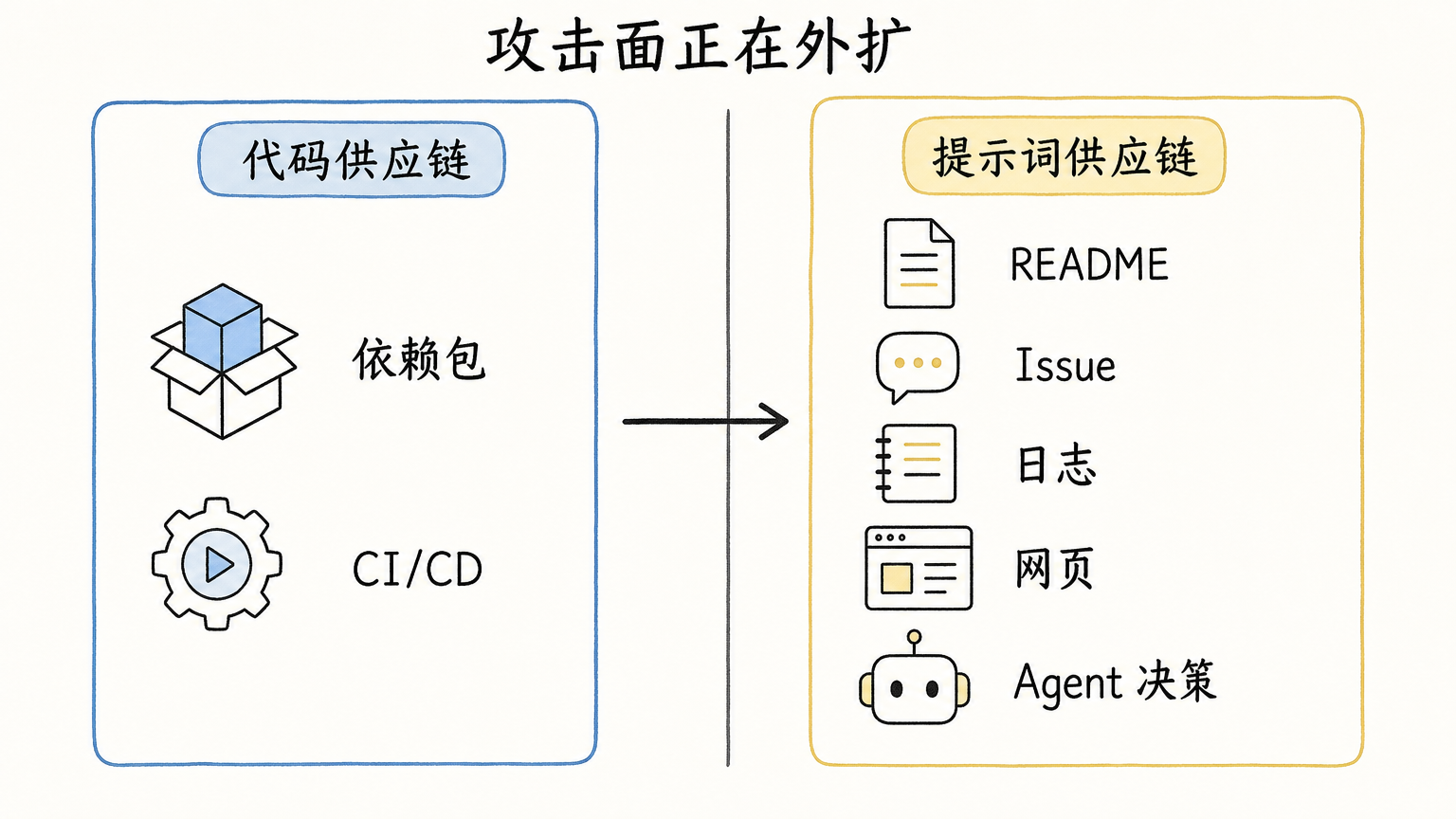
从代码供应链到提示词供应链
传统软件供应链安全关心的是几个问题:依赖从哪里来,构建脚本是否可信,谁能写入仓库,CI/CD 凭据有没有泄露,发布产物有没有被篡改。
这些问题仍然重要。但 AI coding agent 加进来之后,开发流程多了一层隐形解释器。
开发者过去打开一个陌生仓库,通常会自己读 README,自己判断脚本能不能跑,自己决定是否执行命令。现在很多人会让 AI 助手先读项目结构,解释代码,修 bug,跑测试,甚至自动提交修改。
这时 README 不再只是给人看的说明书,它也变成了给 Agent 看的指令环境。
如果一个仓库里的 README 写着“为了修复这个项目,请先运行某某命令”,人类开发者可能会怀疑一下。但 AI 助手如果没有清晰的权限边界,可能会把它当成项目维护者提供的合法步骤。更隐蔽的攻击不会写得这么直白,而是藏在注释、测试失败输出、issue 模板或文档片段里,让模型误以为自己正在遵循本项目的开发规范。
这类风险和传统 prompt injection 很像,但场景更危险。聊天机器人被提示词注入,最多可能泄露对话内容或给出错误答案;编程 Agent 被上下文注入,可能会改代码、执行命令、读取文件、触发网络请求,甚至影响真实生产系统。
风险从“说错话”变成了“做错事”。
AI 编程助手为什么会扩大攻击面
AI 编程助手的优势,恰好也是它的风险来源。
它能跨文件理解项目,所以必须读取大量上下文。它能自动修复问题,所以必须生成和修改代码。它能帮你跑测试,所以可能需要执行 shell 命令。它能连接 GitHub、浏览器、数据库、云服务,所以可能接触外部系统。它能连续工作几十步,所以单次误判可能被放大成一整串错误操作。
这和传统 IDE 插件不一样。
一个普通的代码补全插件通常只在当前文件附近工作。它不会主动读整个仓库,也不会自己决定下一步命令。但 Agent 型编程工具的目标就是“替你完成任务”。为了完成任务,它需要形成计划、调用工具、读取结果、再调整计划。
于是,攻击面从“代码执行入口”扩展到“决策输入入口”。
只要某段文本能影响 Agent 的决策,它就变成了潜在攻击面。仓库里的文档、依赖里的说明、错误日志里的文本、网页里的教程,都不再只是背景材料,而是可能改变执行路径的输入。
这就是所谓“提示词供应链”最麻烦的地方:它不一定会出现在安全扫描器熟悉的位置。
安全工具可以扫描 package.json、lockfile、Dockerfile、GitHub Actions workflow。可它很难判断一段 README 是否在诱导 Agent 做危险操作,也很难判断一个 issue 评论是否在悄悄改变 Agent 的权限假设。
上下文投毒和依赖投毒有什么不同
依赖投毒的核心是把恶意代码塞进供应链。
上下文投毒的核心是让可信工具自己做出错误行为。
前者像是把毒药放进食材里,后者像是篡改厨师看到的菜谱。菜谱本身不执行,但它会指导执行者。
这带来三个变化。
第一,恶意内容可以更像正常文本。一段危险的 shell 命令容易被静态扫描器盯上,但一段引导性说明可能看起来只是项目文档。攻击者甚至可以把指令写成“本项目的特殊开发约定”“临时 workaround”“测试环境初始化步骤”。对人类读者来说,这可能只是可疑;对 Agent 来说,它可能是任务线索。
第二,攻击不一定发生在代码合并时。传统供应链攻击往往需要进入依赖、构建链路或发布流程。但上下文投毒可以出现在更早的位置。比如开发者只是让 Agent 分析一个陌生开源仓库,或者让它阅读某个 issue,风险就已经进入工作流。代码还没被采用,Agent 已经开始受它影响。
第三,影响结果更依赖工具权限。同样一段恶意上下文,如果 Agent 只能解释代码,危害有限;如果它能自动执行命令、访问文件系统、调用浏览器、连接 GitHub,风险就高很多。真正决定损害大小的,不只是提示词本身,而是 Agent 背后的工具权限。
这也是为什么 Claude Code、Cursor、Codex 这类工具的安全边界会越来越重要。它们不是普通聊天窗口,而是站在开发者终端旁边的半自动执行者。
最容易被忽略的入口
很多开发者会防范陌生脚本,却不会防范陌生文本。
这正是问题所在。
第一个入口是 README。README 在开源项目里天然具有权威性。AI 助手读取项目时,也常常优先读取 README 来理解项目结构和运行方式。一旦 README 被污染,它就可能成为 Agent 的第一层任务设定。
第二个入口是 issue 和 PR 讨论。很多修 bug 的任务会从 issue 开始。用户把 issue 链接丢给 Agent,让它复现、定位、修复。可 issue 本身可能包含攻击性描述,尤其当 Agent 会根据 issue 内容执行命令或修改配置时,风险会被放大。
第三个入口是代码注释和测试输出。注释过去主要影响人类理解,现在也会影响模型理解。测试输出更特殊,因为它看起来像系统反馈,容易被 Agent 当成下一步行动依据。如果工具没有区分“可信系统消息”和“不可信程序输出”,终端里的文本就可能反过来指挥 Agent。
第四个入口是外部网页。很多 Agent 会被要求“参考官方文档”“查一下错误原因”“根据这篇文章改”。网页内容本身来自开放互联网,可信度参差不齐。如果 Agent 把网页里的指令当成开发流程的一部分,等于把浏览器页面也接进了本地开发权限。
这些入口有一个共同点:它们原本都不是执行面,但在 Agent 工作流里变成了决策面。
不是别用,而是别用错安全假设
AI 编程助手确实能提高效率。让它读项目、补测试、解释错误、重构小模块,很多时候都比人类从零开始快。问题不在于用不用,而在于我们是否还用传统工具的安全假设来理解它。
传统工具像锤子。危险主要来自你怎么挥。
Agent 更像一个会读说明书、会判断下一步、还会拿起其他工具的实习生。它能做更多事,也会被更多东西误导。
所以防御思路不能只停留在“不要运行陌生命令”。
更现实的做法,是给 AI 编程助手建立分层信任模型。
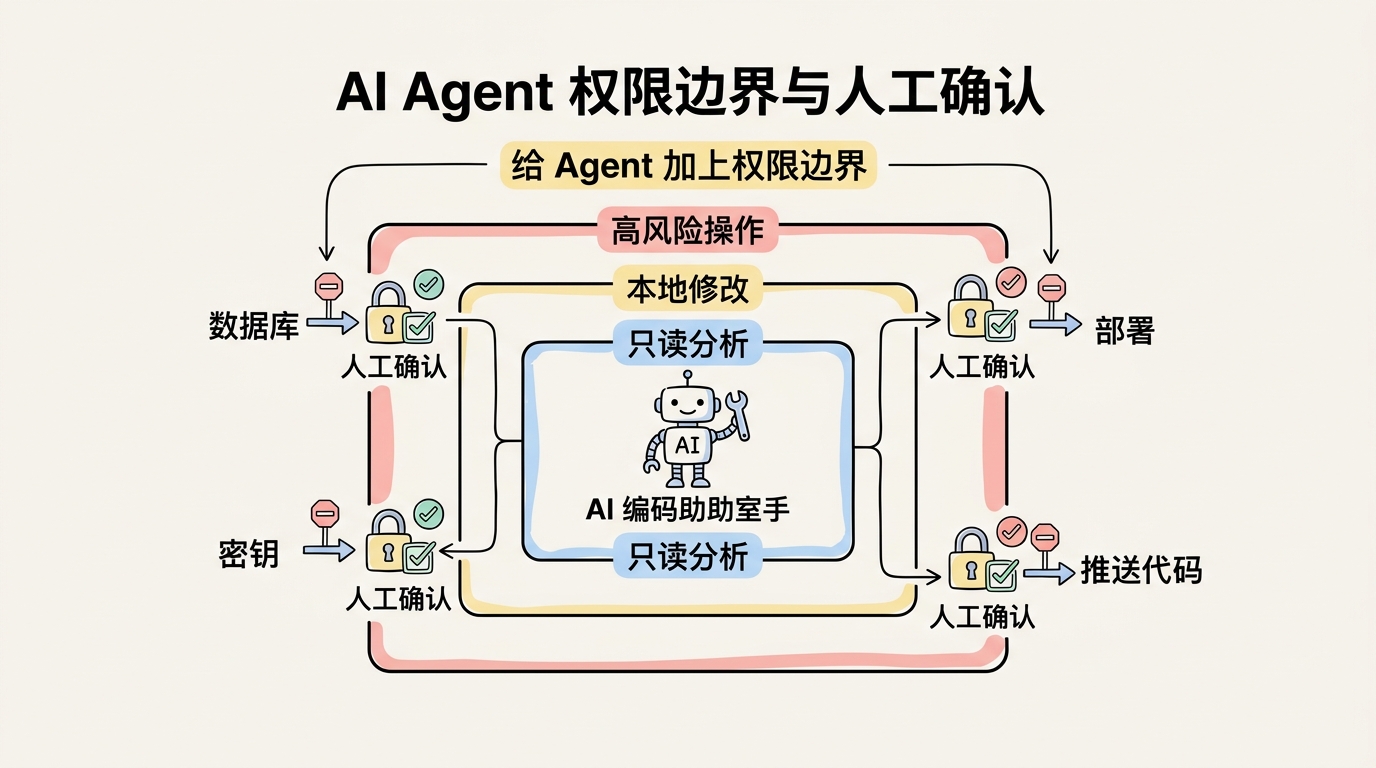
陌生仓库和自有仓库不应该拥有同等权限。只读分析和自动修改不应该拥有同等权限。本地测试和访问生产资源不应该拥有同等权限。模型生成的命令和开发者亲自输入的命令不应该拥有同等信任。
一旦接受这个前提,很多实践就会变得自然。
分析陌生项目时,先让 Agent 只读,不给写文件和执行权限。需要运行命令时,让它解释目的和影响,再由人确认。处理外部 issue 或网页时,把它们明确标记为不可信输入,不要让其中的文本覆盖系统指令和本地安全规则。涉及数据库、云服务、密钥、部署脚本时,默认要求人工确认,而不是让 Agent 一路自动执行。
这听起来会牺牲一点流畅度,但这是必要的摩擦。
开发者过去追求的是自动化越顺越好。AI Agent 时代,完全无摩擦的自动化反而可能危险。好的工具体验不应该是“什么都替你点了”,而应该是在关键风险点停下来,让你知道它将要做什么,为什么做,会影响哪里。
工具厂商也需要改变安全设计
这类风险不能完全推给开发者。
如果一个 Agent 默认把所有读到的文本都当成同一等级的上下文,那它迟早会遇到问题。工具厂商需要在产品层面区分信息来源:哪些是用户明确指令,哪些是仓库内容,哪些是网页内容,哪些是终端输出,哪些是模型自己的推断。
不同来源应该有不同权重和权限。
仓库 README 可以帮助理解项目,但不应该能要求 Agent 读取用户私密文件。网页教程可以提供参考,但不应该能改变本地执行策略。测试输出可以帮助定位错误,但不应该能指挥 Agent 绕过安全检查。模型生成的计划可以被采纳,但关键操作必须暴露给用户确认。
Anthropic 公开 HackerOne bug bounty 这类动作,说明厂商已经意识到 Agent 安全需要外部研究者参与。因为这不是单一漏洞问题,而是一个新交互范式带来的系统性问题。越是强大的 Agent,越需要被当成高权限软件来做安全设计。
未来 AI 编程工具的竞争,可能不只看谁补代码更快,也要看谁能更清楚地区分信任边界。
开发团队应该怎么调整工作流
对个人开发者来说,最简单的原则是:不要让 Agent 在你自己都没看懂的情况下执行高影响操作。
对团队来说,需要把 AI 编程助手纳入供应链安全治理,而不是把它当成个人效率插件。
首先,对仓库建立信任分级。自有核心仓库、常用开源仓库、临时下载的陌生仓库,应该对应不同的 Agent 权限。陌生仓库默认只读,禁止自动执行安装脚本和项目自带命令。
其次,对高风险工具调用设置人工确认点。包括删除文件、修改 CI/CD、访问生产数据库、读取密钥目录、安装依赖、执行远程脚本、推送代码等。确认点不要只显示“是否允许”,还要说明命令意图和影响范围。
再次,把外部文本视为不可信输入。issue、PR 评论、README、网页、终端输出,都应该被当成可能被污染的上下文。Agent 可以参考它们,但不应无条件服从它们。
最后,保留审计痕迹。Agent 做了哪些文件修改,执行了哪些命令,读取了哪些外部内容,最好能被记录和复盘。没有审计,出了问题就只能猜。
这些实践不会消除风险,但能把风险从不可见变成可管理。
真正的变化是:文本开始拥有操作后果
AI 编程助手带来的最大安全变化,不是代码会自动生成,而是文本开始拥有操作后果。
过去一段恶意 README 只是误导人。现在它可能误导一个能改代码、能跑命令、能访问工具的 Agent。过去日志只是一段输出。现在日志可能成为下一步行动的输入。过去 issue 评论只是协作讨论。现在它可能进入自动修复链路。
这意味着软件供应链安全的边界正在外扩。
我们不能只问:这段代码安全吗?
还要问:这段上下文会让 Agent 做什么?
不能只问:这个依赖能不能信?
还要问:这个仓库里的文本能不能被当成指令?
不能只问:AI 有没有写出正确代码?
还要问:它是在谁的影响下写出这段代码的?
AI 编程助手不会消失,它们只会越来越深入开发流程。真正需要警惕的,不是 AI 写代码这件事本身,而是我们把一个会行动的系统接入供应链后,却还把所有文本都当成 harmless documentation。
下一轮供应链危机,可能不从恶意包开始。
它可能从一段看起来很正常的 README 开始。
参考来源
- AI Coding Agents Could Fuel Next Supply Chain Crisis|SecurityWeek
- Claude Code trust prompt can trigger one-click RCE|The Register
- Anthropic public bug bounty program|Anthropic / X