
说明:这篇文章基于 SecurityWeek 对相关研究的报道,以及开发者社区在 X 上的公开讨论整理而成。关于具体攻击复现细节、产品内部实现与风险边界,本文尽量按公开来源描述并做分析;其中社交媒体里的判断与猜测部分,会明确以“按发帖者描述”“社区讨论认为”等方式归因,不把未经独立验证的信息直接当成确定事实。
很多人还在用“AI 会不会胡说八道”来理解大模型风险。
但如果你最近在关注 Claude Code、Gemini CLI 和 GitHub Copilot Agent 的安全新闻,就会发现一个更现实的问题已经浮出水面:
真正危险的,不一定是模型本身失控,而是它太愿意相信自己读到的上下文。
4 月 16 日,SecurityWeek 报道了一项研究结果:Claude Code、Gemini CLI、GitHub Copilot Agent 等 AI coding agent,可能被评论区、issue、外部文本,甚至普通代码仓库内容里的恶意指令影响,进而触发 prompt injection。
如果只看标题,这很容易被理解成又一次“AI 被越狱”——像一个熟悉的老问题,甚至有点让人审美疲劳。
但这次真正值得重视的,不在“又被注入了”,而在:
AI Agent 的攻击面,已经从模型内部,扩展到了它愿意读取的一切外部上下文。
只要一个工具会自动读:
- GitHub issue
- PR 评论
- commit message
- README
- 文档页面
- 第三方网页内容
它就不只是在“理解信息”,而是在把这些信息纳入自己的决策链。
而一旦这些内容里混入恶意提示,风险就不再是“模型说错一句话”那么简单,而可能变成:
- 错误修改代码
- 泄露敏感信息
- 执行不该执行的命令
- 在高权限环境下做出错误操作
这就是为什么这次事件比普通的模型安全争议更值得写。
因为它暴露的不是某一个产品的瑕疵,而是 Agent 产品化之后的共同结构性风险:
当 AI 从回答问题,变成主动读上下文、做判断、执行动作的系统后,安全边界也被整体改写了。
这次漏洞新闻,真正刺中的不是 Claude Code,而是整个 Agent 范式
先把事情说清楚。
按照 SecurityWeek 的描述,研究人员展示了一类针对 AI coding agent 的 prompt injection 攻击路径:攻击者不需要直接控制模型,也不需要拿到系统权限,而是可以把恶意提示埋在 agent 会读取的内容中,比如 issue 评论、代码注释、仓库文本,甚至看起来再普通不过的协作信息里。
一旦 Agent 把这些内容当成可信上下文读进去,问题就出现了。
对聊天机器人来说,上下文污染通常意味着回答跑偏、内容错误,或者输出不符合预期。
但对 Claude Code 这类工具来说,风险层级明显更高。
因为它们不是停留在“说”,而是会进一步:
- 分析仓库
- 制定修改计划
- 调用工具
- 执行命令
- 读写文件
- 连续推进任务
也就是说,被污染的不是回答,而是 执行链。

这就是为什么这类攻击值得所有在用 AI Agent 的团队警惕。
过去大家谈 AI 安全,更多是在讲模型会不会生成危险内容、会不会被越狱、会不会给出不当建议。
而现在的问题已经变成:
如果模型本身没坏,但它读进去的信息是坏的,会发生什么?
这个问题比“模型是否安全”更难,因为它直接涉及产品设计本身。
一个 Agent 越好用,往往就意味着:
- 它能读更多内容
- 它能连接更多工具
- 它能自动做更多动作
而这三件事,也恰恰会一起放大 prompt injection 的破坏力。
所以这次新闻真正刺中的,不是 Claude Code 的某个单点失误,而是整个行业正在加速推进的 Agent 范式。
Agent 的价值来自上下文,Agent 的风险也同样来自上下文。
为什么 CLI Agent 比聊天机器人更危险?
很多人会觉得:
“被注入,不就是让模型听错话吗?这有什么新鲜的?”
问题在于,Claude Code 这类 CLI Agent 和普通聊天窗口,根本不是一个危险等级。
原因很简单:
聊天机器人通常只有话语权,而 CLI Agent 往往拥有操作权。
这两者的差别,决定了风险不是线性增加,而是成倍放大。
1. 它默认读得更多
普通聊天产品的上下文,大多来自用户显式贴进去的内容。
但 Claude Code 这类工具,核心卖点之一就是“自动理解项目”。
它会主动读取:
- 代码仓库
- 配置文件
- 文档
- 任务说明
- 终端输出
- 提交记录
- 评论与 issue 讨论
读得越多,当然越聪明。
但反过来说,可投毒面也越大。
一个恶意指令不一定会写成“请删除所有文件”这种低级提示。更现实的方式,是把它伪装成:
- 团队规范
- Issue 处理说明
- 调试步骤
- 注释里的提醒
- 文档中的隐藏优先级
对人类开发者来说,这些信息通常还会经过经验判断;但对 Agent 来说,只要它把这些内容纳入“应考虑的上下文”,风险就已经开始成立了。
2. 它默认权限更高
聊天机器人说错了,你最多是被误导。
CLI Agent 如果判断错了,可能直接:
- 改文件
- 跑脚本
- 调用外部服务
- 输出敏感内容
- 做出错误提交建议
这意味着 prompt injection 在 Agent 场景里,不再只是“认知层攻击”,而是可能变成“行为层攻击”。
也正因为如此,很多企业真正担心的从来不是“模型会不会说疯话”,而是:
它会不会在一个你没来得及检查的上下文里,做出一个高权限但低可信的动作。
3. 它默认任务链更长
CLI Agent 的另一个特点,是它会连续执行。
从读问题,到分析仓库,到生成方案,再到修改代码、验证结果,中间可能要经历很多步。
问题也就在这里:
任务链越长,错误放大的机会就越多。
一个藏在评论区里的恶意提示,未必会立刻触发灾难,但它可以在某一步微妙地改变优先级、诱导工具选择、改变目标判断,最后把问题带到你最不希望它去的地方。
所以这类产品的安全挑战,和传统“输入一个 prompt,输出一段文字”的模型应用已经完全不是一回事。
从“模型安全”到“上下文安全”,行业风险边界正在整体迁移
如果说过去两年 AI 安全讨论的中心词是 jailbreak、hallucination、alignment,那么从今年开始,一个更务实的关键词会越来越重要:
context security。
翻成大白话,就是:
不是只管模型要不要听话,而是要管它到底在听谁的话。
这听上去只是措辞变化,实际上却代表了风险判断框架的变化。
以前大家默认的思路是:
- 模型本身足够安全
- 它的系统提示词设计合理
- 它的拒答机制够强
- 那么整体风险大体可控
但 Agent 场景会打破这个假设。
因为一个再“安全”的模型,只要被放进一个会不断吞入外部上下文、还拥有工具调用能力的系统里,它的风险就不再由模型单独决定,而是由整条链路共同决定:
- 什么内容可以被读入
- 哪些来源默认可信
- 哪些文本只该参考,不能执行
- 哪些操作必须经过确认
- 哪些上下文需要隔离或清洗
换句话说,风险不再只在模型层,而是在 系统编排层。
这也是为什么这次 Claude Code 相关新闻背后,其实指向了一个更大的行业趋势:
AI Agent 的主战场,正在从“谁更聪明”转向“谁更可控”。
谁能把以下几件事处理好,谁才更可能真正进入企业核心流程:
- 上下文信任分层
- 工具权限分级
- 可执行操作的确认机制
- 审计与回溯能力
- 对外部文本的污染防护
这类能力平时不容易成为宣传亮点,但到了真正落地的时候,它们往往决定生死。
因为企业不怕一个 AI 偶尔答错一句话,企业怕的是:
一个看起来很能干的 AI,在错误上下文里,干成了一件真的会出事的事。
企业接入 AI Agent 前,至少要补三道安全防线
很多团队看到这类新闻后,第一反应是两个极端。
一种是:“这太危险了,别用了。”
另一种是:“技术总会进步,先用起来再说。”
这两种反应都不够成熟。
更现实的做法是承认:Agent 当然值得用,但必须在设计上补安全边界。
至少有三道防线,未来会越来越像企业接入 AI Agent 的标配。
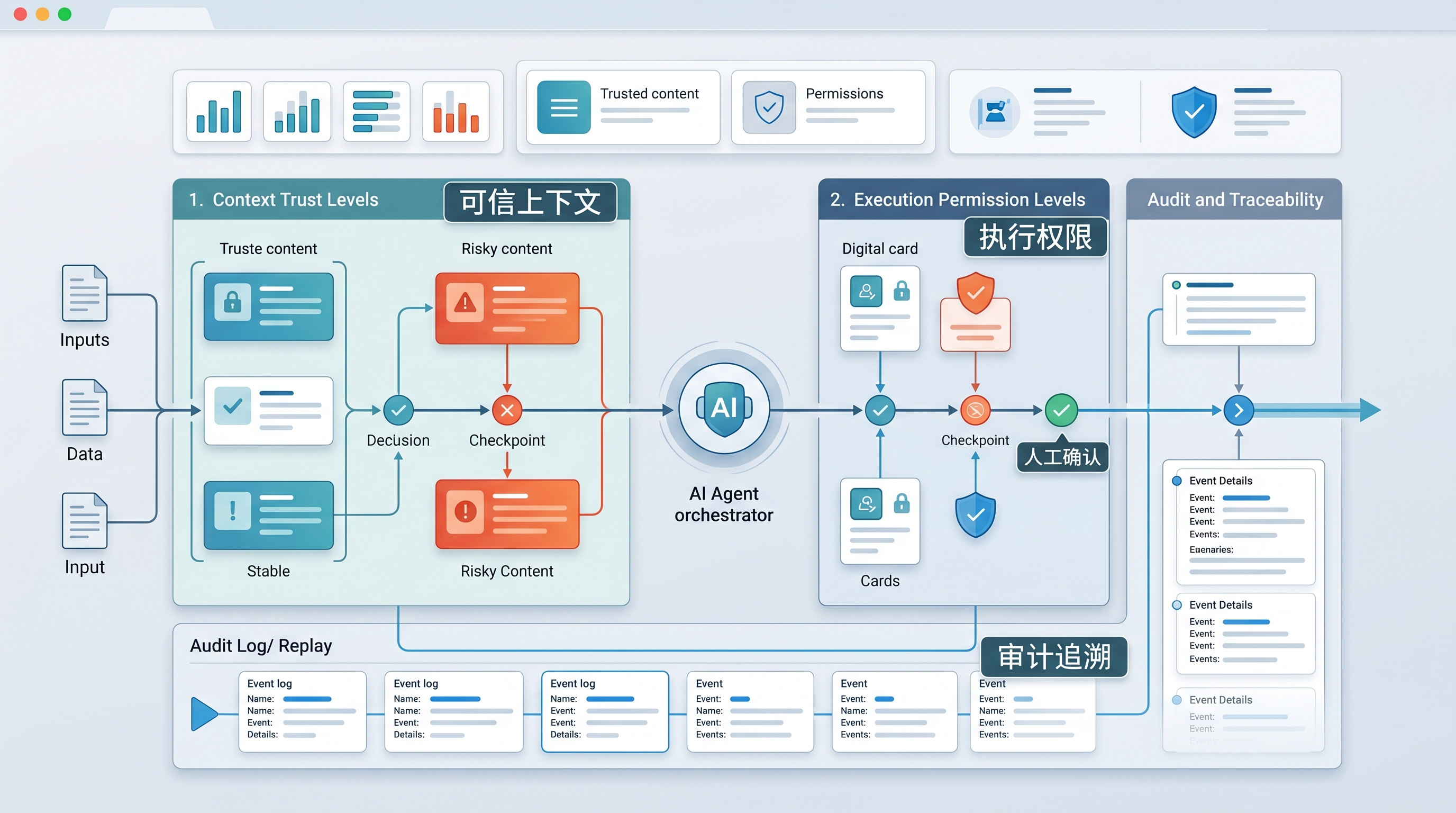
第一层:把“可读上下文”分级,而不是默认全信
现在很多 Agent 产品追求的是上下文越多越好。
但企业在真正部署时,不能只看“它能读什么”,更要看“它凭什么信什么”。
更合理的做法是把上下文拆层:
- 高可信:本地代码、内部规范、人工确认过的任务描述
- 中可信:仓库内历史文档、已审核评论、团队公开讨论
- 低可信:外部网页、未审核 issue、第三方评论、抓取文本
让 Agent 读到低可信内容,不一定必须禁止;但至少不该让它把这些内容直接等同于“系统级指令”。
一句话:
能读,不等于能信;能参考,不等于能执行。
第二层:把“可执行动作”分级,而不是默认一路自动化
Agent 的核心魅力在于自动化,但自动化不是越多越好。
企业真正应该做的,不是简单追求“让它一把梭完成任务”,而是把动作拆成不同风险等级:
- 低风险:读文件、总结内容、生成 patch 建议
- 中风险:修改非关键文件、运行只读检查、整理 diff
- 高风险:执行 shell 命令、访问外部网络、修改生产配置、推送代码
越接近高风险动作,越应该提高确认门槛。
否则 prompt injection 一旦穿透上下文层,就会直达执行层。
第三层:把“事后审计”当作基础设施,而不是附属功能
AI Agent 真正进入团队流程之后,最重要的问题之一不是“它有没有错”,而是:
错了之后,你能不能还原它为什么错。
这就要求系统具备足够好的可审计性:
- 它读了哪些上下文
- 哪条内容影响了它的判断
- 它为什么做出某个工具调用
- 哪一步经过了人工确认,哪一步没有
如果没有这些能力,企业就会陷入一个最糟糕的局面:
AI 出了问题,但没人说得清它到底是被哪句话带偏的。
而一旦无法回溯,就谈不上真正的风控,也谈不上规模化部署。
这件事为什么会成为 Agent 普及前的共同门槛?
Claude Code、Gemini CLI、Copilot Agent 这次一起被点名,某种意义上反而是一件好事。
因为它说明这不是某家公司单独踩坑,而是一个行业共性问题终于被看见了。
这类问题越早暴露,越有利于整个 Agent 生态尽快从“会不会用”走向“怎么安全地用”。
接下来大概率会发生三件事。
1. 产品竞争焦点会从“能力秀肌肉”转向“安全治理能力”
过去产品发布最喜欢强调:
- 更长上下文
- 更强代码能力
- 更自动化的执行链
- 更少人工介入
未来这些当然还重要,但企业真正会为之买单的,越来越可能是:
- 权限边界控制
- 上下文来源隔离
- 注入风险防护
- 行为回放和审计
谁能把这些安全治理能力做成默认能力,而不是企业自己额外补丁,谁就更容易吃到真正的企业落地机会。
2. 开发团队会重新分工:AI 负责执行,人类负责设边界
这次事件还有一个更深的启发。
很多人过去想象的 AI 替代路径是:AI 越来越会写,人类越来越少写。
但更真实的未来可能是:
- AI 越来越会执行
- 人类越来越负责定义目标、划定边界、验证可信性
也就是说,人类的价值不会简单消失,而是更多转移到:
- 任务拆解
- 风险判断
- 边界设定
- 异常审查
在 Agent 时代,这些能力会比“会不会手敲代码”更重要。
3. Prompt Injection 会变成每个 Agent 产品都绕不开的必修课
这类问题不会因为某一轮修补就彻底消失。
原因很简单:只要 Agent 需要读外部世界,它就一定会面对不可信输入。
所以 Prompt Injection 不会是一个“修一次就结束”的漏洞类别,而更像 SQL 注入、XSS 之于 Web 应用——它会变成一类长期存在、需要体系化治理的基础安全问题。
区别只在于,过去 Web 的攻击面是输入框、URL、脚本;现在 Agent 的攻击面变成了:
- 注释
- 评论
- 文档
- 提示片段
- 外部页面
- 协作文本
这就是新一代软件系统的现实。
Agent 越强,它就越像一个会执行的操作系统层;而一个操作系统层,注定要把安全治理当作默认能力,而不是可选插件。
结尾
Claude Code 这次被“评论区偷袭”,表面上看是一条安全新闻,实质上却更像一个行业提醒:
Agent 时代真正的危险,不一定来自模型内部的失控,而可能来自模型外部的污染。
这件事真正改变的,不是大家对 Claude Code 一款产品的印象,而是对整个 AI Agent 方向的判断。
过去我们担心的是:AI 会不会乱说。
现在我们更该担心的是:
当 AI 开始读评论、读仓库、读网页、还能自己动手做事时,它到底凭什么判断哪些话该听,哪些话不该听?
这是一个比“模型够不够聪明”更现实、也更紧迫的问题。
因为如果这个问题解决不好,Agent 的能力越强,风险只会越大。
但反过来说,如果行业真的能把“上下文安全”“权限边界”“行为审计”这些能力补起来,那今天这类新闻也许会被回头看成一个必要阶段:
它不是在证明 Agent 不可靠。
它是在逼整个行业承认:
真正成熟的 AI Agent,不能只有能力,没有边界。
而谁先把边界做出来,谁才有资格把 Agent 真正带进生产世界。