最近 StartupHub.ai 写了一篇关于 21st.dev 的公司分析。按原文说法,21st.dev 原本是一个面向 design engineers 的 React component registry,已经触达约 140 万开发者;现在它开始把重心转向 Agents SDK,提供 managed sandboxes、streaming、credential proxy 和 observability 等 Agent 基础设施。
这件事乍看像是一个创业公司改方向:从组件库转去做更性感的 AI Agent。
但我觉得它更该被放进 AI 编程工具演化的链条里看:当 AI 已经能写 UI、补接口、改 bug、跑脚本之后,稀缺点正在从“生成代码”转到“把任务安全、稳定、可审计地跑在真实用户面前”。
AI 会写组件之后,值钱的是沙箱。
从组件库到 Agent SDK,看起来跳跃,其实很顺
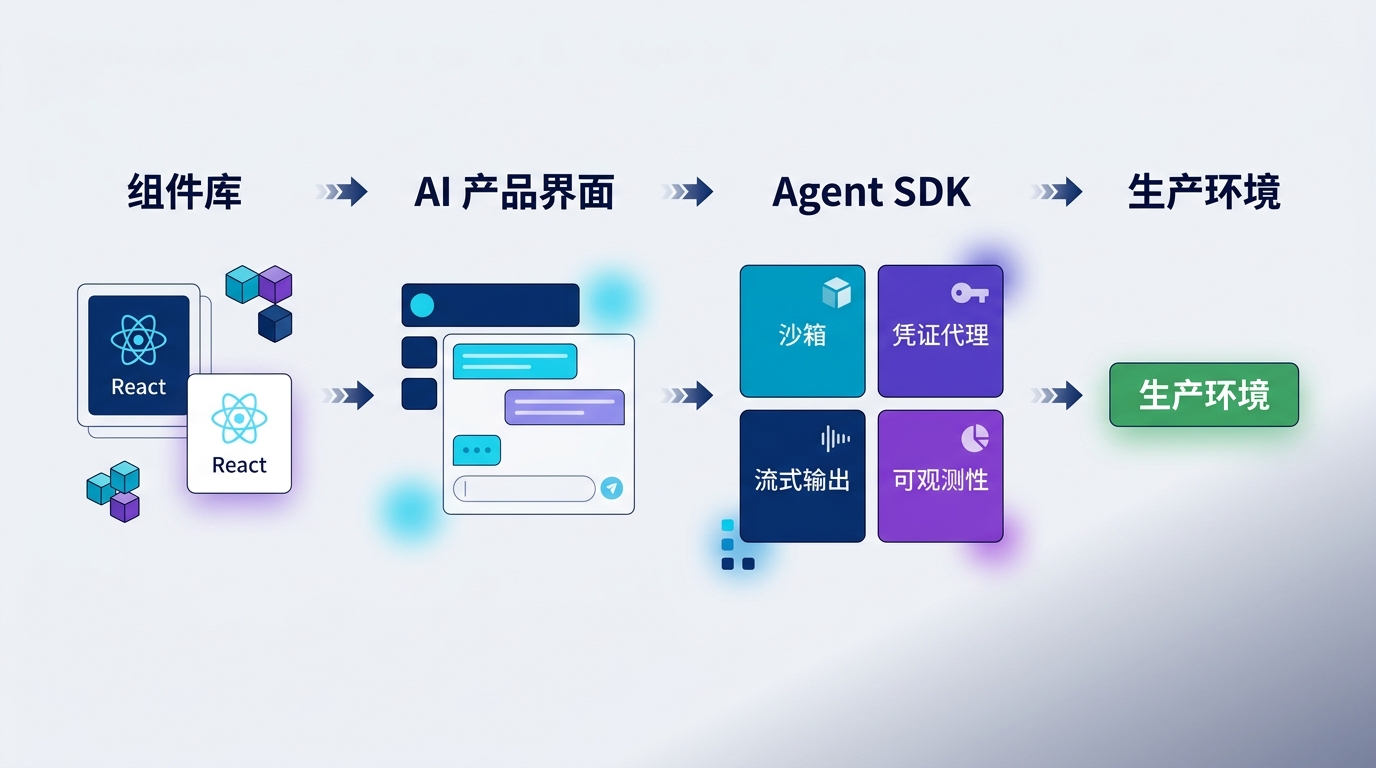
21st.dev 最早解决的是一个很前端的问题:开发者需要可复制、可改造、适合现代 AI 产品的 React 组件。
这条路不难理解。过去几年,shadcn/ui、Tailwind CSS、Radix UI 这类工具改变了前端组件的分发方式。开发者越来越喜欢“把代码复制到自己项目里”,而不是安装一个黑盒 UI 库。因为复制进去之后,代码就是自己的,可以改,可以删,可以适配项目风格,也没有运行时依赖和授权焦虑。
21st.dev 做的事情,大致就是把这种模式进一步社区化、搜索化、面向 AI 应用场景化。比如聊天界面、prompt box、流式消息、session history、输入框动画,这些都是今天 AI 产品里高频出现的 UI 模块。
如果只看到这里,它像是一个 AI 时代的组件分发平台。
但问题是:当 AI 编程工具越来越强,组件本身的稀缺性会下降。
以前,一个漂亮的 chat UI、一个复杂的 settings panel、一个能跑起来的 dashboard,可能需要前端工程师花半天甚至几天。现在 Claude Code、Cursor、Codex 这类工具已经能很快生成第一版。组件库当然还有价值,但它从“节省开发时间的核心资产”,逐渐变成“提高起步质量和审美一致性的辅助资产”。
如果 AI 能快速写出 UI,那么下一个瓶颈就会往后移动。
前端页面有了,用户输入有了,模型调用有了,Agent 开始执行任务时,麻烦才集中出现:它要在哪里运行?能访问什么文件?能不能拿用户凭证?失败时怎么追踪?循环调用工具把成本烧上去怎么办?多个用户同时使用时,状态怎么隔离?
这些问题都不是组件库能解决的。
当 AI 已经能快速生成 UI,工具公司就得沿着链路继续往后走:从“帮你把界面搭起来”,走到“帮你把 Agent 跑起来”。
AI 编程的瓶颈,正在从生成转向执行
过去一年,开发者讨论 AI 编程时,最常见的问题是:哪个工具写代码更好?Claude Code、Cursor、Codex、Antigravity 谁更强?哪个模型更会修 bug?哪个上下文更长?
这些问题当然重要,但它们仍然停留在“生成”层。
生成层关心的是:模型能不能根据需求写出正确代码。
生产层关心的是另一组问题:这些代码和工具调用能不能在真实环境里安全执行。
一个本地 demo 可以很随意。你在自己的电脑上跑 Claude Code,让它改文件、装依赖、执行测试,出了问题最多回滚一下。即使它把目录弄乱了,也只是你自己的工作区。
但如果你做的是一个面向外部用户的 AI Agent 产品,情况完全不同。
用户让 Agent 分析仓库、生成代码、运行脚本、调用第三方 API、读取私有数据。每一步都有风险。它不能和其他用户共用不干净的运行环境,不能把 A 用户的文件泄露给 B 用户,不能让模型在上下文里看到原始 API key,也不能在执行失败后只留下一句“出错了”。
这就是 21st.dev 这类 Agent 基础设施想切入的地方。
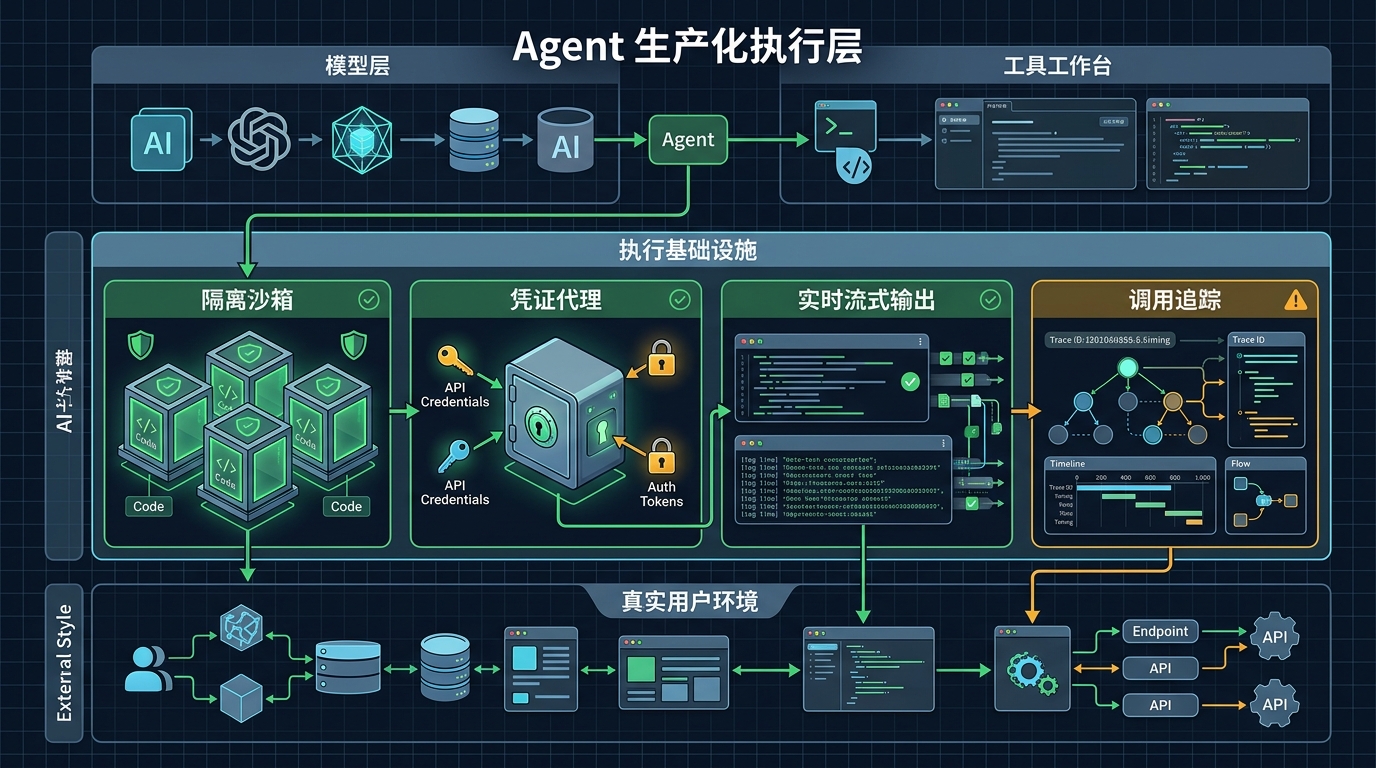
原文提到的几个模块,其实正好对应 Agent 产品从玩具到生产的关键门槛。
第一个是 sandboxed execution。Agent 需要一个隔离环境来运行代码和工具调用。这个环境最好每次会话独立创建,用完销毁。它不能污染其他 session,也不能留下不可控状态。原文提到 21st.dev 使用 E2B microVM 作为隔离基础,再在上层管理 session 生命周期、warm pool 和 API 表面。
第二个是 streaming infrastructure。好用的 Agent 产品不能让用户盯着一个 loading 圈等几分钟。模型 token、工具调用、执行日志、阶段性结果,都需要实时返回给前端。看起来只是 SSE 或 WebSocket,实际到了生产环境,会遇到断连、半截 JSON、重试、顺序错乱、客户端状态同步等一堆细碎问题。
第三个是 credential proxy。这个点尤其关键。很多 Agent 的价值来自“代替用户操作外部系统”,比如 GitHub、Linear、Slack、Stripe、数据库、云服务。但如果直接把用户 API key 塞进模型上下文或执行环境,安全边界会非常糟糕。更合理的方式是让代理层在网络请求层注入凭证,Agent 本身不直接持有原始 secret。
第四个是 observability。Agent 不是普通函数调用。它可能连续推理、循环调用工具、生成中间文件、执行命令、再根据结果改计划。出错时,你不能只看最终错误栈,而要知道它在哪一步开始偏离,调用了什么工具,花了多少 token,为什么进入循环。可观测性既是调试工具,也是成本控制和计费系统的基础。
这些能力听起来都不如“一个会写代码的模型”酷,但它们决定了 Agent 能不能进入生产。
为什么前端工具公司会看到这个机会
21st.dev 这个转向有意思的地方在于,它不是从云基础设施或 DevOps 领域切进来的,而是从前端组件库切进来的。
这条路径并不奇怪。
AI Agent 的第一批产品,很多会从前端和应用层长出来,而不是从底层 infra 长出来。一个团队先做聊天界面、任务面板、代码生成体验、工作流编辑器,然后很快发现:界面只是开始,背后的执行系统才麻烦。
前端产品天然离用户更近,也更早感受到“体验断裂”。
用户点击“生成项目”之后,不关心你用了什么模型,也不关心你后端怎么调度。他只关心这个任务能不能跑、日志能不能看、失败能不能恢复、权限是否安全、结果是否可复现。
这就让前端工具公司有机会沿着用户体验往基础设施下沉。
它们不是先卖一个抽象的 sandbox API,而是先拥有开发者入口。21st.dev 的组件 registry 如果确实已经积累了大量开发者使用,那么它就有一个很自然的漏斗:开发者先来找 AI 产品组件,复制代码,搭出界面;当他们开始把 Agent 产品推向真实用户时,就会遇到运行、隔离、凭证和观测问题;这时 Agents SDK 就成了顺手的下一步。
这比冷启动卖 infra 要轻得多。
开发者工具里,分发往往比技术更难。很多基础设施产品不是因为不好用而失败,而是因为开发者根本不知道它,或者没有在合适的时刻遇到它。组件库本身也许不是最终商业化重心,但它可以成为入口和信任资产。
这家公司案例最值得拆的地方也在这里:registry 负责分发,SDK 负责变现。
Agent 基础设施到底难不难?
从纯技术角度看,21st.dev 做的东西并不是不可复制。
沙箱可以基于 E2B、Firecracker、容器或其他隔离方案;流式输出可以基于 SSE;凭证代理可以用成熟的 token vault 和请求代理模式;可观测性也有 OpenTelemetry、日志系统、trace viewer 等大量现成经验。
所以这不是一个“只有他们能做”的硬科技壁垒。
难点在组合。
做一个 sandbox demo 不难。接一个 LLM streaming API 也不难。保存工具调用日志仍然不难。难的是在多租户、真实用户、高并发、可计费、可调试、可回滚的环境下,把这些东西组合成一个开发者愿意依赖的生产系统。
更难的是信任。
如果一个 SDK 只是帮你渲染按钮,迁移成本很低。不好用就删掉,换另一个组件。
但如果一个 SDK 接管了你的 Agent 运行环境、凭证代理、执行日志和计费数据,它就会嵌入你的生产架构。你不会轻易替换它,也不会轻易采用它。
这类基础设施的商业逻辑通常是:早期获客很难,一旦进入生产就很黏。
所以 21st.dev 的挑战不是“能不能做出一个 SDK”,而是“能不能让开发者相信它足够稳定,值得把生产 Agent 放上去”。
它原来的开发者社区就变得很重要。社区不是装饰,而是降低信任成本的方式。一个完全陌生的 infra 公司说自己能托管你的 Agent,你会谨慎;一个你已经用过它组件、看过它代码、在社区里见过别人使用的开发者品牌,说自己把踩过的坑产品化了,接受度会高一些。
这和 Claude Code、Cursor、Antigravity 有什么关系
很多人会把这类新闻直接理解成“又一个 Claude Code 竞争者”。我觉得这个理解不太准确。
Claude Code、Cursor、Codex、Antigravity 主要解决的是开发者如何与代码库协作。它们是工作台、IDE、CLI、agentic coding environment。
21st.dev 这类 Agent infrastructure 更像是面向“要把 Agent 能力嵌进自己产品里的开发团队”。
前者帮你开发软件,后者帮你交付一个会执行任务的软件。
当然,两者会越来越靠近。
当 Claude Code 这类工具越来越强,开发者会开始想:能不能把类似能力放进我的 SaaS?能不能让用户在我的产品里也拥有一个能改配置、查数据、跑流程、调用接口的 Agent?这时需要的就不是一个本地 CLI,而是一整套托管执行层。
Agent 生态未来可能会分成几层。
模型层提供推理能力。工作台层提供人机协作界面。工具协议层让 Agent 调用外部能力。执行基础设施层负责沙箱、权限、观测和计费。应用层再把这些能力包装成具体场景。
今天很多产品还把这些层混在一起。一个创业团队做 Agent,既要写前端,又要接模型,又要设计工具调用,又要处理执行环境,还要做日志和账单。结果很容易变成每家都重复造同一套不稳定轮子。
如果 21st.dev 这类公司能把执行层抽出来,它们就会成为 Agent 应用爆发前的“水电煤”。
对国内 AI 工具创业的启发:别只做壳,要做执行层
这个案例对国内 AI 工具创业也有参考价值。
过去一年,很多 AI 产品的形态都太像“壳”:套一个模型,做一个聊天界面,加一些 prompt 模板,再包装成某个垂直场景。短期能上线,长期很容易同质化。
Agent 时代的壳会更快贬值。因为 UI 可以生成,prompt 可以复制,模型能力会外溢,用户对“又一个聊天框”的耐心越来越低。
更有价值的部分,往往藏在那些不容易展示、但真实影响交付的地方。
比如执行环境。你的 Agent 能不能安全地跑代码、改文件、调用系统?
比如权限模型。它能访问什么,不能访问什么,用户如何授权,企业如何审计?
再比如状态、记忆和可观测性。它能不能记住项目上下文,同时避免错误记忆长期污染?它做了什么、为什么这么做、哪里失败、花了多少钱,能不能被追踪?
最后是交付闭环。它不只是生成建议,还要能完成任务、提交结果、等待批准、必要时回滚。
这些东西不一定适合做成最炫的发布视频,但它们决定产品能不能从 demo 进入生产。
如果一个团队只做“AI 帮你生成页面”,它很快会被模型能力吞掉。如果它能做“AI 生成之后,安全运行、持续调试、可控交付”,价值就厚很多。
21st.dev 的转向,其实是在回答这个问题:当 AI 把前端生产力大幅拉平之后,一个前端工具公司还能往哪里走?
它给出的答案是:往执行层走。
组件不是终点,运行时才是战场
我不确定 21st.dev 最后一定能赢。Agent 基础设施这个方向会很拥挤,模型厂商、云厂商、IDE 公司、开源框架、企业 SaaS 都可能往里挤。
OpenAI 和 Anthropic 可以从模型层往下做工具和执行环境;Cloudflare、Vercel、AWS 可以从云平台往上做 Agent runtime;Cursor、Google Antigravity 这类工作台也可能把托管执行能力纳入自己的产品。
21st.dev 的机会在于,它从开发者社区和前端应用场景出发,可能更懂 AI 产品开发者最早遇到的具体痛点。
这不是一个“技术最难者胜”的市场,而是一个“谁先在正确入口建立信任,谁就有机会变成默认选项”的市场。
过去,前端基础设施的默认选项可能是 npm、Vercel、shadcn/ui、Tailwind。未来,如果 AI Agent 真的进入大量应用,新的默认选项可能会出现在 sandbox、credential proxy、tool-call tracing、agent observability 这些看起来很底层的地方。
AI 编程先让代码更容易被生成。
接着,它会逼着团队重新处理维护问题。
再往后,会执行任务的 Agent 要安全进入生产。
21st.dev 的转向说明,已经有人在下注第三件事。
这也是为什么我觉得这个案例值得写。它不是一个普通的“公司 pivot”故事,而是一个信号:AI 工具的价值正在从“帮你写出来”,迁移到“帮你跑得住”。